

Наверное, ни один из рассказов про современные нейросети не обойдётся без упоминания трансформер-моделей: в самом деле, почти все нашумевшие достижения в глубинном обучении последних лет так или иначе опираются на эту архитектуру. Что же в ней такого особенного и почему трансформеры успешно применяются в самых разных задачах?
Давайте разбираться.
Зачем нам внимание
Для начала вспомним, что основным подходом для работы с последовательностями до 2017 года (выхода оригинальной статьи про архитектуру «трансформер») было использование рекуррентных нейронных сетей, или RNN. Однако у такого подхода есть несколько известных минусов:
- Во-первых, RNN содержат всю информацию о последовательности в скрытом состоянии, которое обновляется с каждым шагом. Если модели необходимо «вспомнить» что-то, что было сотни шагов назад, то эту информацию необходимо хранить внутри скрытого состояния и не заменять чем-то новым. Следовательно, придется иметь либо очень большое скрытое состояние, либо мириться с потерей информации.
- Во-вторых, обучение рекуррентных сетей сложно распараллелить: чтобы получить скрытое состояние RNN-слоя для шага , вам необходимо вычислить состояние для шага . Таким образом, обработка батча примеров длиной должна потребовать последовательных операций, что занимает много времени и не очень эффективно работает на GPU, созданных для параллельных вычислений.
Обе этих проблемы затрудняют применение RNN к по-настоящему длинным последовательностям: даже если вы дождетесь конца обучения, ваша модель по своей конструкции будет так или иначе терять информацию о том, что было в начале текста. Хочется иметь способ «читать» последовательность так, чтобы в каждый момент времени можно было обратиться к произвольному моменту из прошлого за константное время и без потерь информации. Таким способом и является лежащий в основе трансформеров механизм self-attention, о котором далее пойдет речь. Как мы узнаем позже, благодаря своей универсальности и масштабируемости этот механизм оказался применим к множеству задач помимо обработки естественного языка.
Ниже приведено устройство архитектуры «трансформер» из оригинальной статьи:
Слева на схеме представлено устройство энкодера. Он по очереди применяется к исходной последовательности из блоков:
Каждый блок выдаёт последовательность такой же длины. В нём есть два важных слоя, multi-head attention и feed-forward. После каждого из них к выходу прибавляется вход (это стандартный подход под названием residual connection) и затем активации проходят через слой layer normalization: на рисунке эта часть обозначена как “Add & Norm”.
У декодера схема похожая, но внутри каждого из блоков два слоя multi-head attention, в одном из которых используются выходы энкодера.
Давайте подробнее обсудим каждую из составляющих частей этого механизма.
Слой внимания
Первая часть transformer-блока — это слой self-attention. От обычного внимания его отличает то, что выходом являются новые представления для элементов той же последовательности, что мы подали на вход, причем каждый элемент этой последовательности напрямую взаимодействует с каждым.
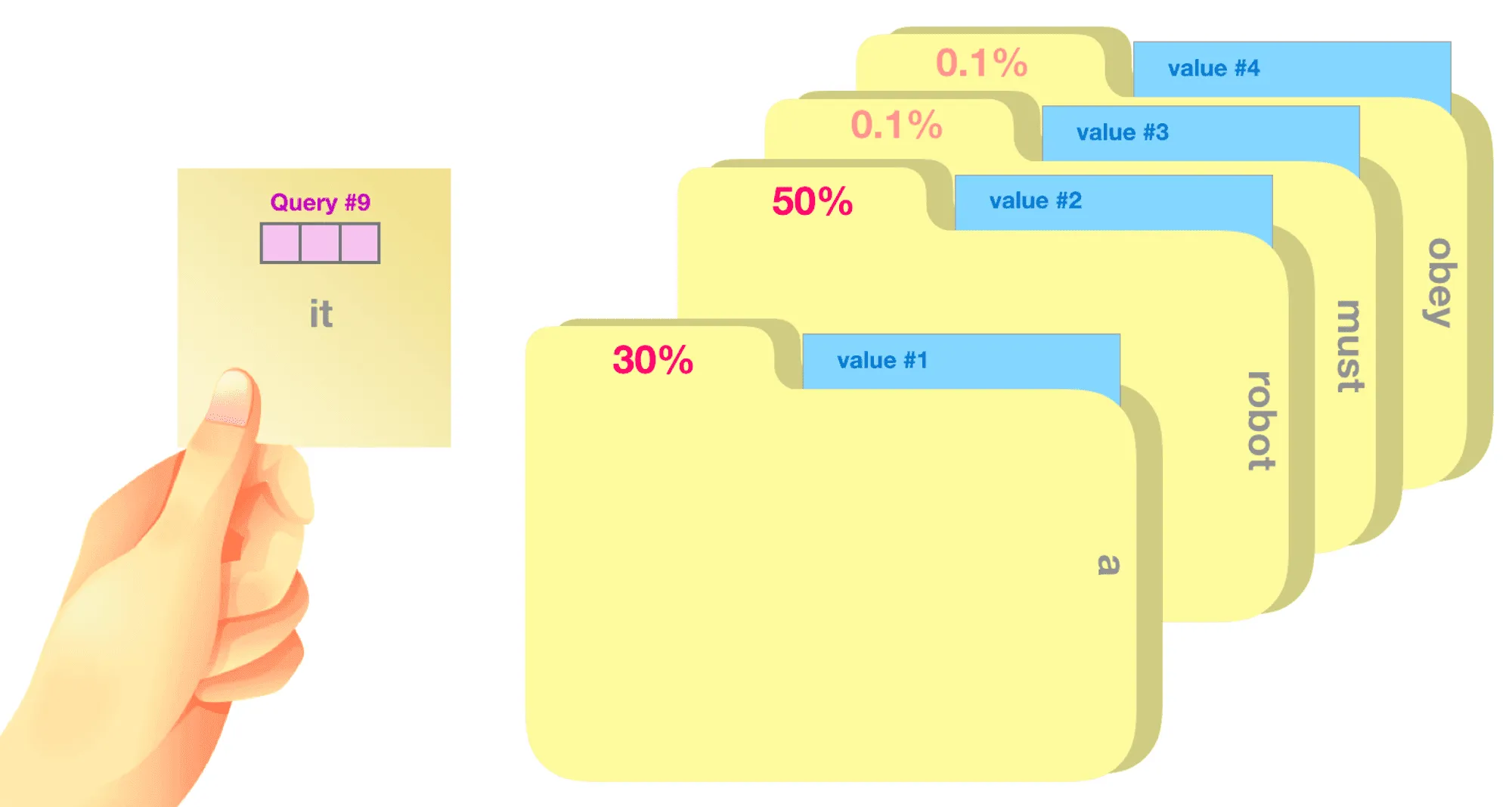
Если говорить более подробно, то в вычислении внимания для последовательности будет участвовать три обучаемых матрицы . Представление каждого элемента входной последовательности мы умножаем на , получая вектор-строки ( — номер элемента), которые соответственно называются запросами, ключами и значениями (query, key и value). Их роли можно условно описать следующим образом:
- — запрос к базе данных;
- — ключи хранящихся в базе значений, по которым будет осуществляться поиск;
- — сами значения.
Близость запроса к ключу можно определять, например, с помощью скалярного произведения:
где — некоторая нормировочная константа. Именно так и делали в исходной статье; в качестве нормировочной константы брался корень из размерности ключей и значений. Теперь мы складываем значения с полученными коэффициентами. Это и будет выходом слоя self-attention. В векторизованном виде можно записать:
где , , — матрицы запросов, ключей и значений соответственно, в которых по строкам записаны , , , а берётся построчно.
Особенности слоя внимания в декодере
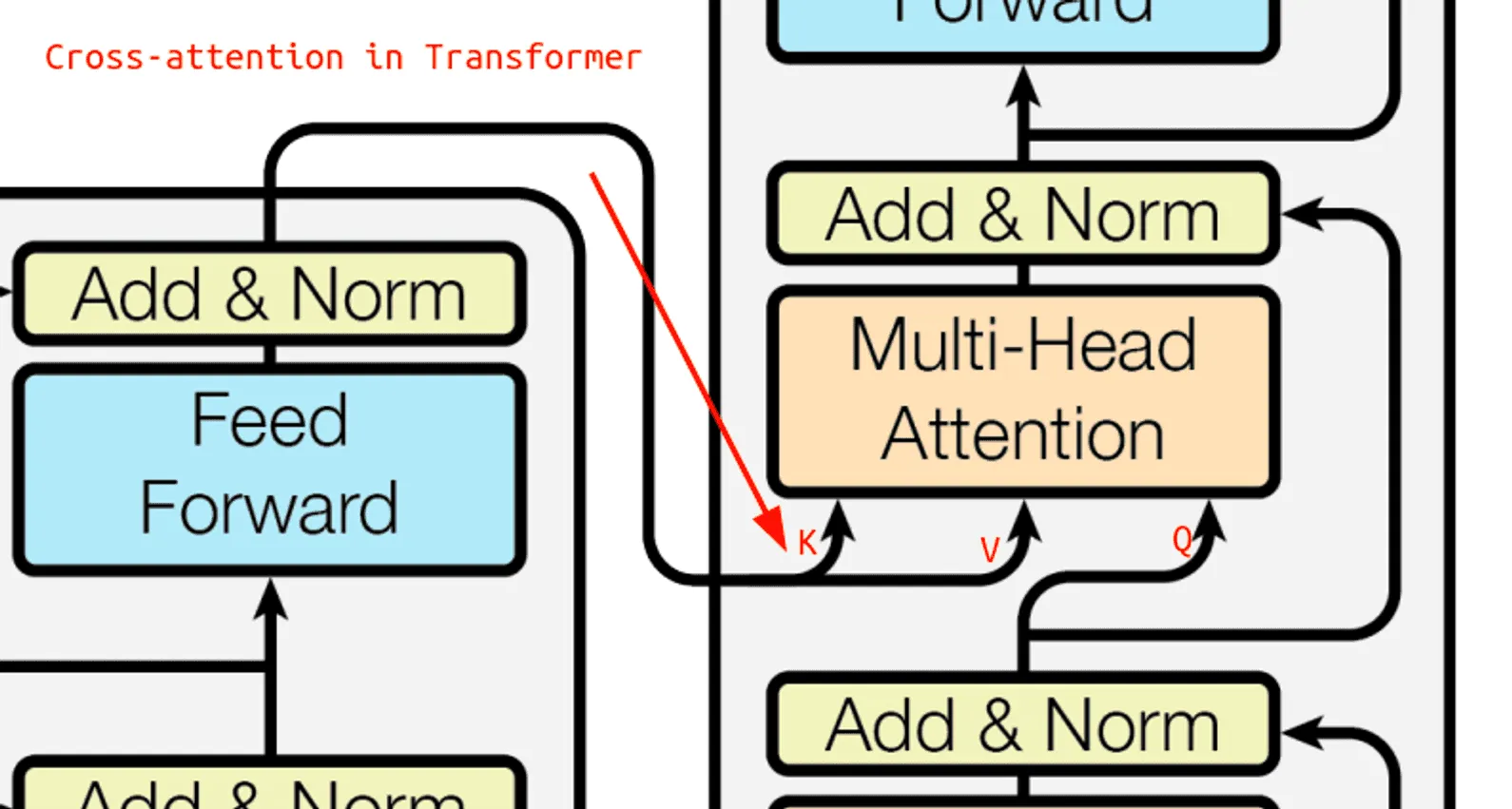
Как мы уже упоминали выше, в декодере один из attention-слоёв является слоем кросс-внимания (cross-attention), в котором запросы берутся из выходной последовательности, а ключи и значения — из входной (то есть из результатов работы энкодера).
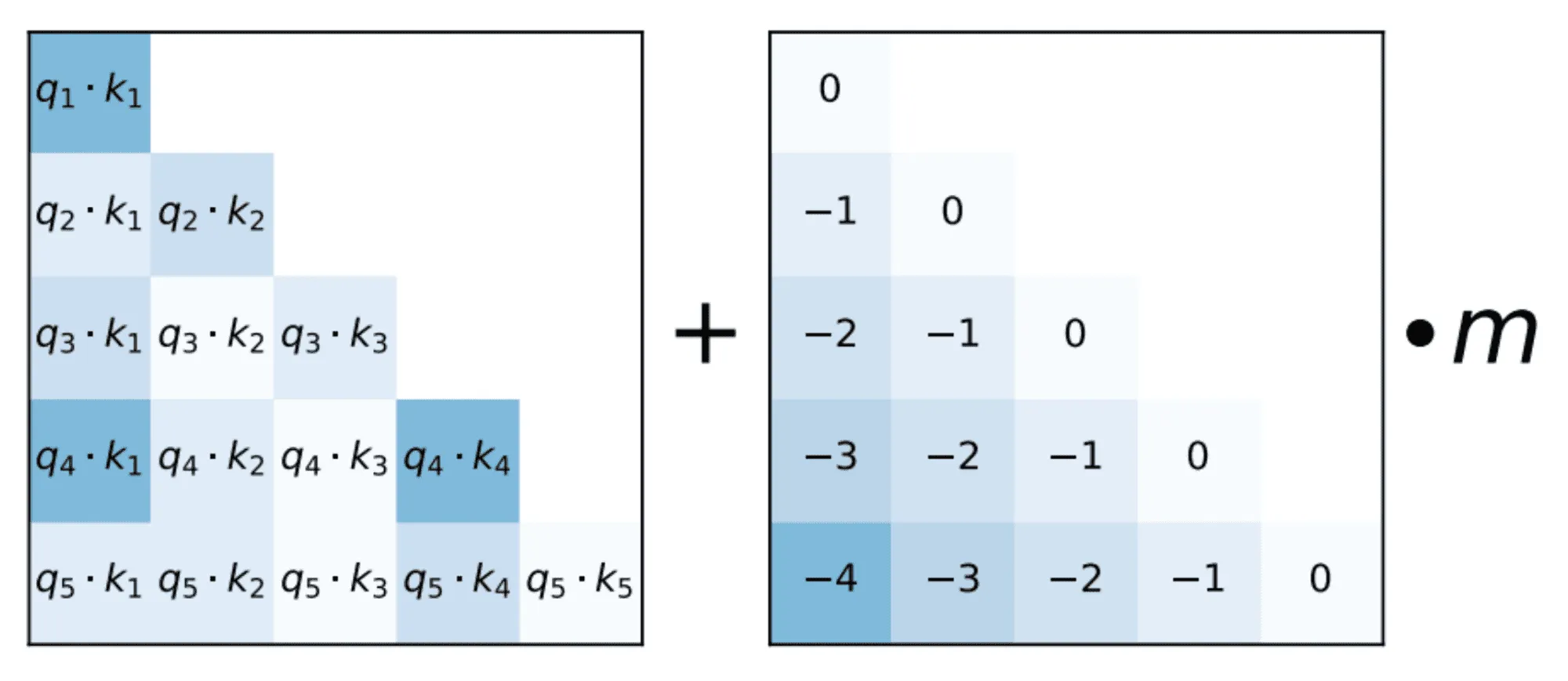
Также стоит учитывать, что в описанном выше виде внимания каждый токен будет «смотреть» на всю последовательность, что нежелательно для декодера. Действительно, на этапе генерации мы будем порождать по одному токену за шаг, и доступ к последующим шагам на этапе обучения приведёт к утечке информации в декодере и низкому качеству модели. Чтобы избежать этой проблемы, при обучении к вниманию нужно применять авторегрессивную маску, вручную обращая в веса до softmax для токенов из будущего, чтобы после softmax их вероятности стали нулевыми. Как можно увидеть на рисунке внизу, эта маска имеет нижнетреугольный вид.
Multi-head attention
Один набор , и может отражать только один вид зависимостей между токенами, и матрицы извлекают лишь ограниченный набор информации из входных представлений. Чтобы скомпенсировать эту неоптимальность, авторы архитектуры предложили подход с несколькими «головами» внимания (multi-head attention): по сути вместо одного слоя внимания мы применяем несколько параллельных с разными весами, а потом агрегируем результаты. Рисунок ниже показывает, как выглядит multi-head attention:
Эффективность
Подход к обработке последовательностей целиком через внимание позволяет избавиться от такого понятия, как скрытое состояние, обновляющееся рекуррентно: каждый токен может напрямую «прочитать» любую часть последовательности, наиболее полезную для предсказания. В частности, отсутствие рекуррентности означает, что мы можем применять слой ко всей последовательности одновременно, так как матричные умножения прекрасно параллелятся.
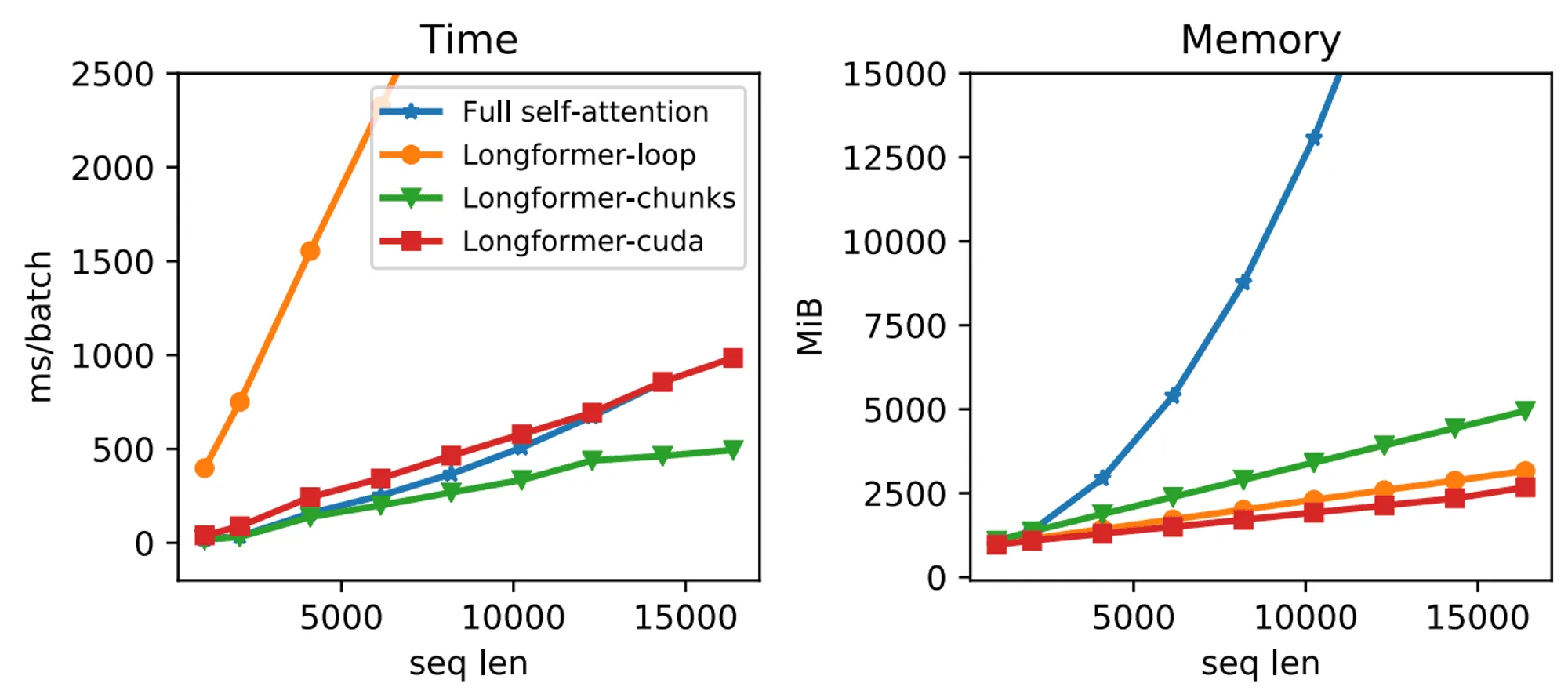
Однако стоит помнить о затратах памяти и времени: поскольку каждый элемент последовательности взаимодействует с каждым, легко показать, что сложность self-attention составляет по длине последовательности, а простые реализации, формирующие полную матрицу внимания, будут расходовать ещё и памяти. С оптимизацией вычислительной сложности внимания связано множество работ как инженерного, так и архитектурного плана: в частности, есть подходы, которые позволяют сократить время работы self-attention до линейного или существенно уменьшают константы за счёт учёта иерархии памяти GPU.
Например, на графиках ниже сравнивается время работы и потребление памяти трансформера со стандартным вниманием и с механизмом из статьи Longformer:
Полносвязный слой и нормализация
Вторая часть трансформерного блока называется feed-forward network (FFN) и представляет собой два обычных полносвязных слоя, применяемых независимо к каждому элементу входной последовательности. В последних архитектурах размер промежуточного представления (то есть выхода первого слоя) бывает весьма большим — в 4 раза больше выходов блока.
Из-за этого вычислительной стоимостью FFN не стоит пренебрегать: несмотря на квадратичную асимптотику внимания, в больших моделях или на коротких последовательностях FFN может занимать существенно больше времени по сравнению с self-attention. В виде формулы применение FFN можно представить так:
Промежуточные активации в FFN бывают разными: начиналось всё с широко известной ReLU, но в какой-то момент сообщество перешло на GELU (Gaussian Error Linear Unit) с формулой , где — функция распределения стандартной нормальной случайной величины.
Скажем ещё пару слов о layer normalization: как было показано в ряде работ, их положение внутри residual-ветки довольно важно. В стандартной архитектуре используется формулировка PostLN, где нормализация применяется после остаточной связи. Однако такое применение нормализации оказывается довольно нестабильным при обучении моделей с большим числом слоёв: вместо этого предлагается использовать PreLN (справа на рисунке снизу), где нормализация применяется ко входу residual-ветки.
Кодирование позиций
Внимательный читатель может заметить, что все операции внутри трансформер-блока, строго говоря, инвариантны к порядку элементов в последовательности. Например, результат внимания зависит от скалярных произведений между эмбеддингами токенов, но расположение этих токенов внутри текста значения не имеет. Таким образом, итоговые представления каждого токена на выходе из модели будут одинаковыми вне зависимости от порядка слов, что вряд ли нас устроит. Как с этим справиться?
На помощь приходит такая вещь, как позиционные эмбеддинги. Это вспомогательные представления, которые прибавляются к обычным эмбеддингам токенов входной последовательности и позволяют слоям внимания различать одинаковые токены на разных местах.
Исторически первым подходом были фиксированные эмбеддинги, однозначно кодирующие позицию тригонометрическими функциями (ниже — номер позиции, — индекс элемента в векторе, кодирующем эту позицию, — размерность эмбеддинга):
С момента появления архитектуры «трансформер», однако, появилось множество других способов кодировать позиции токенов. Например, можно просто сделать позиционные эмбеддинги обучаемыми наряду с эмбеддингами токенов. Иной подход — напрямую учесть тот факт, что нам важны не абсолютные позиции токенов, а расстояние между ними, и обучать относительные позиционные представления: подобный подход заметно улучшает качество на чувствительных к порядку слов задачах, а его более современные модификации регулярно используются в самых мощных моделях.
Про BERT и GPT
Несомненно, трансформер-модели не были бы так интересны, если бы практически все задачи NLP сейчас не решались бы с помощью этой архитектуры. Главными факторами, повлиявшими на бурный рост популярности идеи self-attention, послужили два семейства хорошо всем известных архитектур — BERT и GPT, которые в некотором роде являются энкодером и декодером трансформера, которые зажили своей жизнью.
Модель GPT (Generative Pretrained Transformer) хронологически появилась раньше. Она представляет собой обычную языковую модель, реализованную в виде последовательности слоев декодера трансформера.
В качестве задачи при обучении выступает обычное предсказание следующего токена (то есть многоклассовая классификация по словарю). Важно, что в качестве маски внимания как раз выступает нижнетреугольная матрица: в противном случае возникла бы утечка в данных из-за того, что токены из «прошлого» будут видеть «будущее». Полученную модель можно использовать для генерации текстов и всех задач, которые на это опираются. Даже ChatGPT, обученная на специальных инструкциях, по своей сути незначительно отличается от базовой модели.
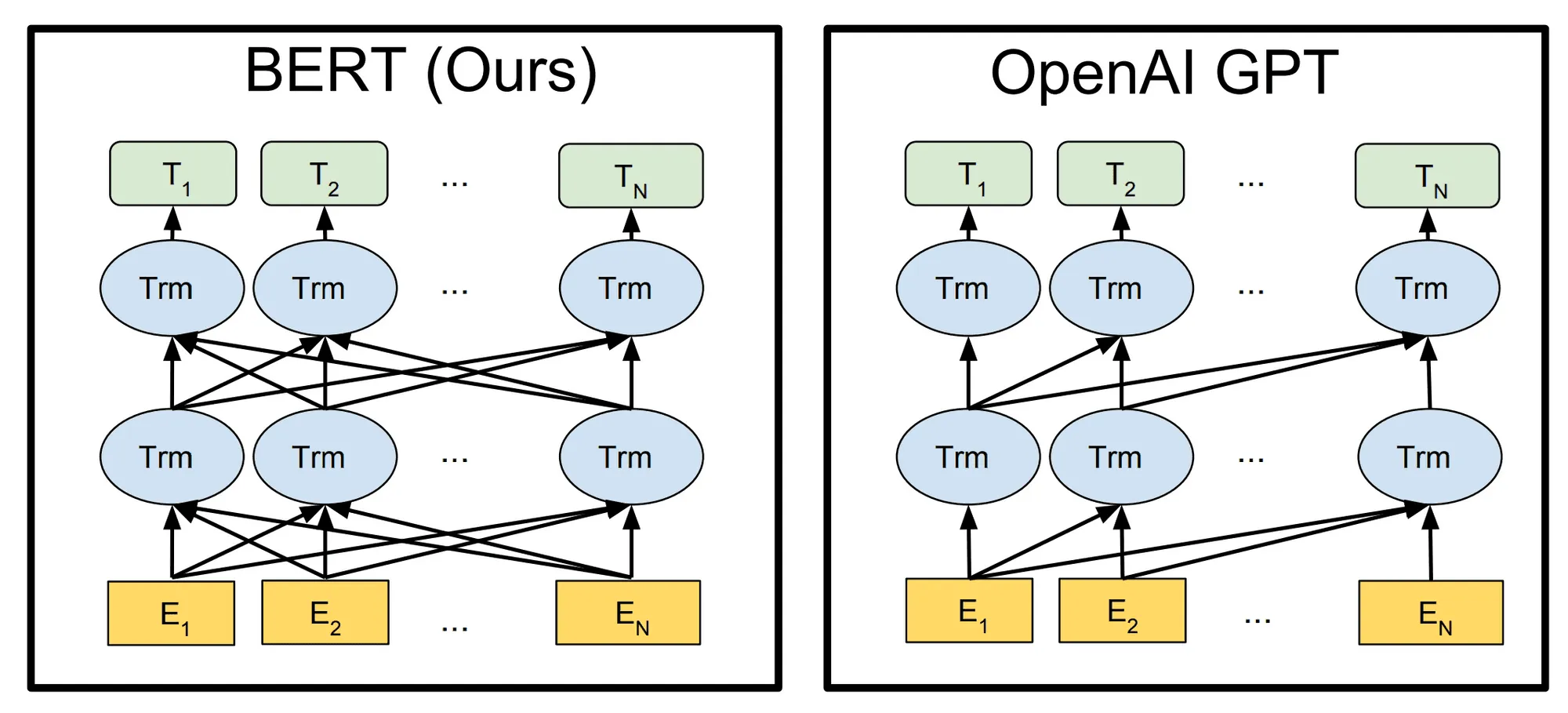
Как понятно из названия, модель Bidirectional Encoder Representations from Transformers (или BERT) отличается от GPT двунаправленностью внимания: это значит, что при обработке входной последовательности все токены могут использовать информацию друг о друге.
Это делает такую архитектуру более удобной для задач, где нужно сделать предсказание относительно всего входа целиком без генерации, например, при классификации предложений или поиске пар похожих документов. Важно, что при этом BERT не учится генерировать тексты с нуля: одна из его задач при обучении — это masked language modeling (предсказание случайно замаскированных слов по оставшимся, изображено на рисунке ниже), а вторая — next sentence prediction (предсказание по паре текстовых фрагментов, следуют они друг за другом или нет).
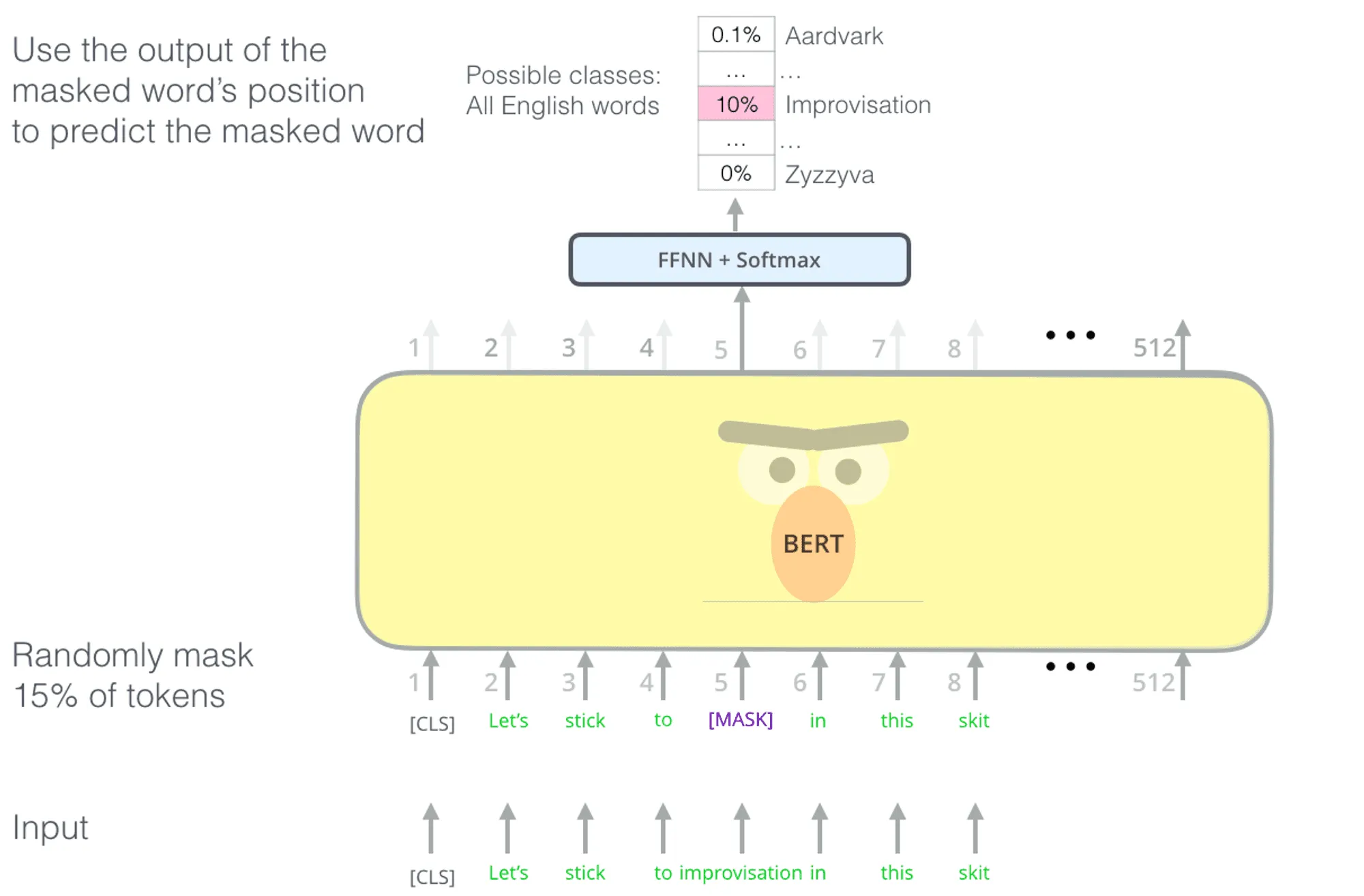
Заметим, что самое ключевое отличие в моделях BERT и GPT (а не в задачах для обучения или применениях) можно свести к использованию разных видов внимания, изображенных на рисунке снизу.
Тонкости обучения
К сожалению, если вы просто напишете код Transformer-нейросети и попробуете сразу обучить что-то содержательное, используя привычные для других архитектур гиперпараметры, то вас с большой вероятностью постигнет неудача. Оптимизационный процесс для таких моделей зачастую требуется изменить, и недостаточное внимание к этому может повлечь за собой существенные потери в итоговом качестве или вообще привести к нестабильному обучению.
Первый момент, на который стоит обратить внимание, — размер батча для обучения. Практически все современные Transformer-модели обучаются на больших батчах, которые для самых больших языковых моделей могут достигать миллионов токенов. Разумеется, ни одна современная GPU не может обработать столько данных за один шаг: на помощь приходят распределенное обучение и чуть более универсальный трюк с аккумуляцией градиентов по микробатчам.
Также в последних статьях зачастую прибегают к увеличению размера батча по ходу обучения: идея заключается в том, что на ранних этапах важнее быстрее совершить много шагов градиентного спуска, а на поздних становится важнее иметь точную оценку градиента.
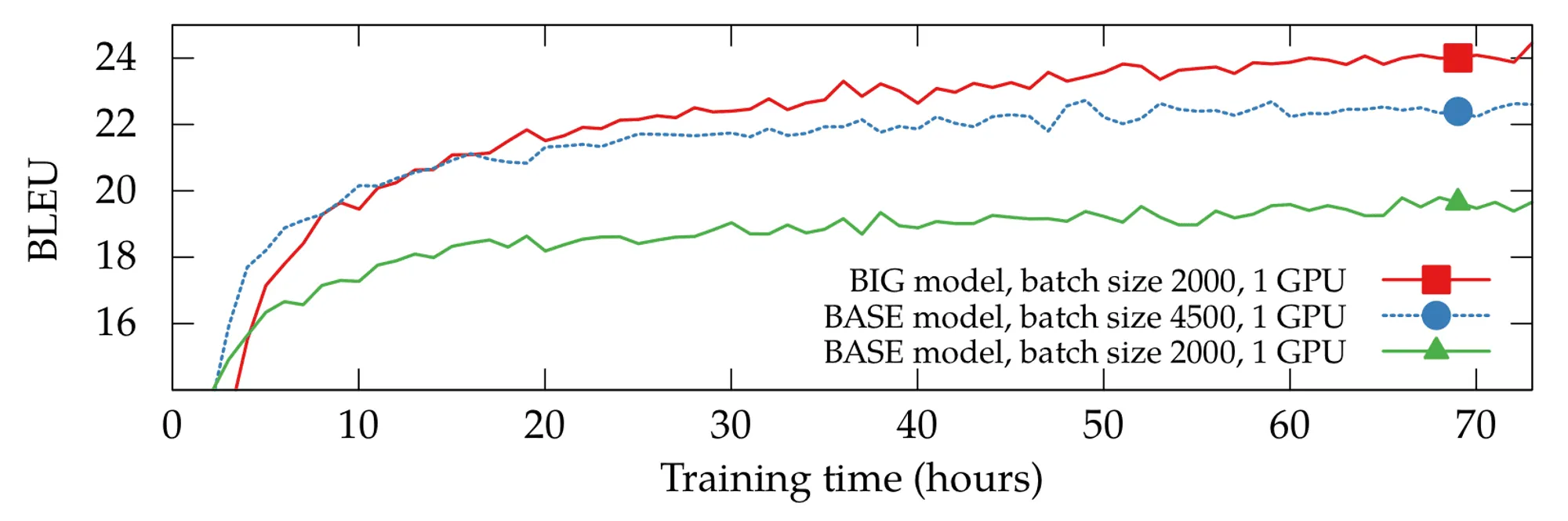
Второй немаловажный фактор — выбор оптимизатора и расписания для learning rate. Обучить трансформер стандартным SGD, скорее всего, не выйдет: в оригинальной статье в качестве оптимизатора использовался Adam, и де-факто он остаётся стандартом до сих пор.
Однако стоит заметить, что для больших размеров батча Adam порой работает плохо: из-за этого порой приходится прибегать к алгоритмам наподобие LAMB, нормализующим обновления весов для каждого слоя.
Трансформеры не для текстов
Разумеется, успех этого семейства архитектур на множестве текстовых задач не мог остаться незамеченным для исследователей в других доменах. Одним из наиболее ярких примеров областей, в которой Transformer-модели нашли новое приложение, несомненно, является компьютерное зрение.
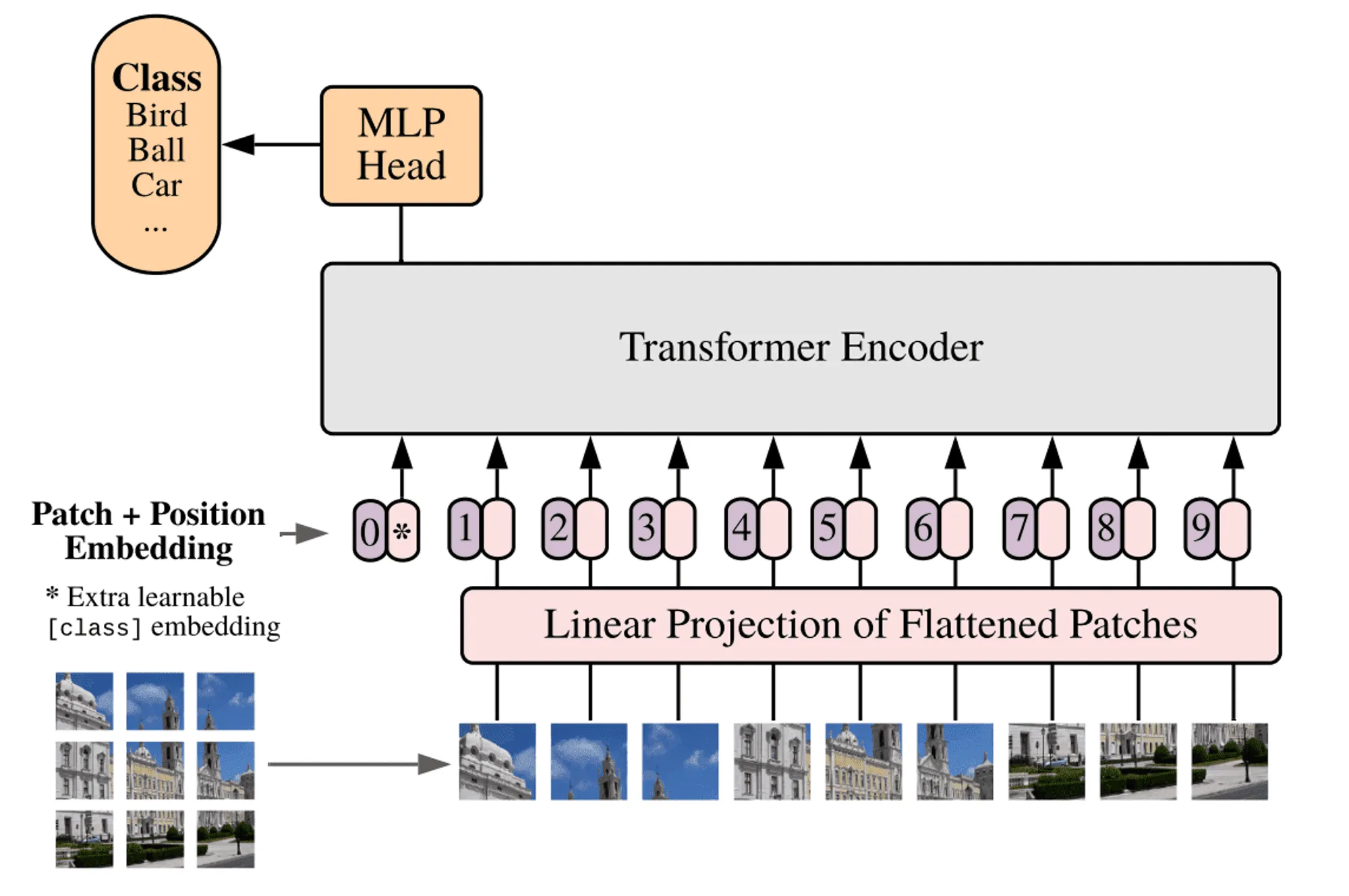
К примеру, архитектура ViT (Vision Transformer) в свое время побила рекорды качества по классификации изображений, задействуя идею self-attention для картинок, разделенных на множество «лоскутных» (patches) сегментов квадратной формы.
Как пишут авторы статьи, идея использовать Transformer-архитектуру в зрении пришла к ним после наблюдения за успехами таких моделей в NLP: использование такого общего подхода, как self-attention, позволяет избежать необходимости явно закладывать в архитектуру особенности задачи (это ещё называют inductive bias) при достаточном времени обучения, числе параметров и размере выборки.
Также именно на трансформерах базируется генеративная часть DALL-E — модели, положившей начало активным исследованиям последних лет в генерации изображений по тексту. Концептуально DALL-E довольно проста: её можно рассматривать как авторегрессивную «языковую модель», генерирующую изображение по одному «визуальному токену» за шаг.
Применяют трансформеры и к обучению с подкреплением: ярким примером является работа Decision Transformer, в которой предлагают использовать авторегрессивное моделирование с использованием этой архитектуры для построения агента.
Авторы показали, что такой же подход, который используют для генерации текстов, можно использовать для предсказания действий в динамической среде: как показано на рисунке ниже, модель последовательно принимает стандартные тройки из закодированных состояний, текущих действий и наград и в качестве ответа на каждом шаге выдаёт следующее действие.