

В этом разделе вы познакомитесь с нейросетями для работы с данными, имеющими вид последовательностей некоторых токенов. Это может быть музыка или видео, временные ряды или траектория движения робота, последовательности аминокислот в белке или много чего ещё, но одним из самых богатых источников таких данных является Natural Language Processing (NLP).
Как следует из названия, Natural Language Processing (обработка естественного языка) — это область data science, посвященная анализу текстов, написанных на естественных (человеческих) языках. С задачами обработки текста мы встречаемся каждый день, например, когда просим Siri или Алису включить любимую песню или добавить напоминание в календарь, когда используем автодополнение при вводе поискового запроса или проверяем орфографию и пунктуацию с помощью специальных программ.
Вот ещё несколько примеров задач, относящихся к обработке естественного языка:
- классификация документов (по темам, рубрикам, жанрам и так далее);
- определение спама;
- определение частей речи;
- исправление орфографических ошибок и опечаток;
- поиск ключевых слов, синонимов / антонимов в тексте;
- распознавание именованных сущностей (имен, названий географических объектов, дат, номеров телефонов, адресов);
- определение эмоциональной окраски текста (sentiment analysis);
- поиск релевантных документов по запросу, а также их ранжирование;
- задача суммаризации (автоматическое составление краткого пересказа текста);
- автоматический перевод с одного языка на другой (машинный перевод);
- диалоговые системы и чат-боты;
- вопросно-ответные системы (выбор ответа из нескольких предложенных вариантов или вопросы с открытым ответом);
- кроме того, к NLP также относят задачу распознавания речи (Automated Speech Recognition, ASR).
Для работы с такими данными есть несколько возможных режимов:
- Many-to-one. На вход подается последовательность объектов, на выходе один объект. Пример 2: классификация текстов или видео. Пример 2: тематическая классификация. По предложению нефиксированной длины генерируем вектор вероятностей упоминания заранее фиксированных тем во входном предложении. Размерность выходного вектора постоянна и равна количеству тем.
- One-to-many. На вход подается один объект, на выходе последовательность объектов. Пример: генерация заголовка к изображению (image captioning).
- Many-to-many. На входе и выходе последовательности нефиксированной длины. Примеры: машинный перевод, суммаризация текста, генерация заголовка к статье.
- Синхронизированный вариант many-to-many. На входе и выходе последовательности одинаковой длины, токены входной явно сопоставлены соответствующим токенам выходной. Пример: генерация покадровых субтитров к видео, PoS-tagging (part of speech tagging, для каждого слова в предложении предсказываем, что это за часть речи).

Мы начнём с архитектур, в которых размер выхода предсказуемым образом зависит от размера входа: many-to-one и синхронизованном варианте many-to-many — но в итоге доберёмся и до остальных.
Word Embeddings
Перед тем, как рассказать об архитектурах, которые часто используются для работы с текстами, надо разобраться, каким образом можно кодировать текстовые данные: ведь нужно их превратить во что-то векторное, прежде чем подавать на вход нейросети. К векторизации текстов есть два базовых подхода:
- векторизовать текст целиком, превращая его в один вектор;
- векторизовать отдельные структурные единицы, превращая текст в последовательность векторов.
Первые, статистические подходы к векторизации следовали первому подходу и рассматривали текст как неупорядоченный набор («мешок») токенов (обычно токенами являются слова). Тем самым, тексты «Я не люблю ML» и «Я люблю не ML» получали одинаковые векторизации, то есть по ходу терялась существенная информация. Поэтому мы лишь коротко упомянем о них.
Немного о статистических подходах
Самый очевидный вариант так и называется — Bag-of-Words («мешок слов»). Текст предлагается представить в виде вектора частот встречаемости каждого токена, кроме элементов заранее заданного списка «стоп-слов», в которые обычно включают самые вездесущие токены: личные местоимения, артикли и так далее.
Чуть более усложненной версией является TF-IDF (Term Frequency-Inverted Document Frequency). Этот подход использует не только информацию из текста, но и пытается соотнести её с контекстом — остальными текстами из имеющейся у нас коллекции . Представление текста состоит из произведений по всем токенам . Разберёмся отдельно с каждым из сомножителей:
- , где — число вхождений токена в документ, а в знаменателе стоит общее число слов в данном документе . Это частота вхождения токена в документ.
- , где — число документов в текстовой коллекции , в которых встречается слово . Этот множитель штрафует компоненты, отвечающие слишком распространённым токенам, и повышает вес специфических для отдельных текстов (и, вероятно, информативных) слов.
Обратимся теперь к другому подходу и подумаем, как сопоставить векторы (эмбеддинги) словам.
Допустим, что у нас одно и то же слово будет представлено одним и тем же вектором во всех текстах и в любых позициях. Как заключить в векторе его смысл, содержающуюся в нём информацию? Ответ предвосхищает одну из основных идей обучения представлений: нужно использовать контекст. Если, читая книгу на иностранном языке, вы встречаете незнакомое слово, вы нередко можете угадать его значение по контексту, что оно значит. Можно сказать, что смысл слова — это те слова, которые встречаются с ним рядом.
Одним из воплощений такого подхода является Word2vec. Впервые он был предложен Т.Миколовым в 2013 году в статье Efficient Estimation of Word Representations in Vector Space.
Для обучения авторы предложили две стратегии: Skip-gram и CBOW (Сontinuous bag-of-words):
- В архитектуре CBOW модель учится предсказывать данное (центральное) слово по контексту (например, по двум словам перед данным и двум словам после него).
- В архитектуре Skip-gram модель учится по слову предсказывать контекст (например, каждого из двух соседей слева и справа);

Авторы предложили для каждого слова обучать два эмбеддинга: и , первое из которых используется, когда является центральным, а второе — когда оно рассматривается, как часть контекста. В модели CBOW при фиксированном контексте вычисляются логиты
после чего «вероятности» всевозможных слов быть центральным словом для контекста вычисляются как . Модель учится с помощью SGD на кросс-энтропию полученного распределения с истинным рапределением центральных слов.

В модели Skip-gram по данному центральному слову для каждой позиции контекста независимо предсказывается распределение вероятностей. В качестве функции потерь выступает сумма кросс-энтропий распределений слов контекста с их истинными распределениями.

Размерность эмбеддинга в каждой из архитектур — это гиперпараметр и подбирается эмпирически. В оригинальной статье предлагается взять размерность эмбеддинга 300. Полученные представления центральных слов могут дальше использоваться в качестве эмбеддингов слов, которые сохраняют семантическую связь слов друг с другом.
Мы не будем здесь останавливаться подробно на деталях работы Word2vec и его современных модификациях и предложим читателю обратиться к соответствующей лекции в учебнике Лены Войта по NLP. А мы лишь продемонстрируем, что он работает.
Примеры. Возьмём несколько слов и посмотрим, как выглядят топ-10 слов, ближайших к ним в пространстве эмбеддингов (обученных на одном из датасетов Quora Questions с помощью word2vec):
- quantum: electrodynamics, computation, relativity, theory, equations, theoretical, particle, mathematical, mechanics, physics;
- personality: personalities, traits, character, persona, temperament, demeanor, narcissistic, trait, antisocial, charisma;
- triangle: triangles, equilateral, isosceles, rectangle, circle, choke (догадаетесь, почему?), quadrilateral, hypotenuse, bordered, polygon;
- art: arts, museum, paintings, painting, gallery, sculpture, photography, contemporary, exhibition, artist.
Вопрос на подумать. В реальных текстах наверняка будут опечатки, странные слова и другие подобные неприятности. Word2vec же учится для фиксированного словаря. Что делать, если на этапе применения вам попадается неизвестное слово? Да и вообще, хорошо ли учить вложения для редких слов или слов с нетривиальными опечатками, которые, может быть, только раз встретятся в тексте?
Ответ (не открывайте сразу; сначала подумайте сами!)
Начнём с последнего вопроса: наверное, не очень хорошо. Словарь может получиться слишком большим и займёт всю оперативную память мира. Нередко для достаточно редких слов вовсе не учат специального эмбеддинга, вместо этого для всех них обучая представление одного единственного токена UNK (unknown). В таком случае и всем незнакомым словам, встреченным на этапе применения, также можно сопоставить этот же эмбеддинг.
В реальных сервисах, имеющих дело с текстами (например, в автоматических переводчиках) зачастую вовсе не имеют дела со словами, предпочитая дополнительно разбивать их на subword units. Самым популярным на данный момент решением является BPE (Byte pair encoding). Верхнеуровневая идея состоит в том, что мы фиксируем размер словаря (обычно не очень большой, несколько тысяч или десятков тысяч единиц), добавляем в него все символы, после чего повторяем, пока словарь не заполнится:
- находим самую часто встречающуюся вместе пару токенов;
- добавляем их конкатенацию в словарь.
Более подробно о BPE вы можете прочитать в учебнике Лены Войта.
Вопрос на подумать. В некоторых случаях всё же полезно уметь строить эмбеддинги не отдельных слов, а текстов (например, для поиска похожих документов). Можете ли вы, вдохновившись идеей word2vec, придумать более тонкий способ сделать это, чем BoW или TF-IDF?
Ответ (не открывайте сразу; сначала подумайте сами!)
Самый простой способ это сделать — сложить или усреднить эмбеддинги отдельных слов, но так мы теряем их порядок, и вместе с ним значительную часть смысла (очень похоже на bag-of-words, не так ли?). Другой подход, развивающий идеи word2vec, был предложен в другой статье Т. Миколова и носит название doc2vec. Он также имеет CBOW-подобную и Skip-gram-подобную версии. Остановимся на первой. Если в оригинальном CBOW мы предсказывали центральное слово по контексту, то теперь добавляется ещё дополнительный вектор , уникальный для каждого документа и кодирующий присутствующую в нём смысловую специфику:

Рекуррентные нейронные сети
Итак, мы представили текст в виде последовательности векторов, соответствующих словам или их кусочкам. Как с ней работать? Один из вариантов мы уже рассматривали: можно посмотреть на последовательность из векторов размерности как на «изображение» с «каналами», после чего использовать уже знакомые нам свёрточные нейросети, только с одномерными свёртками вместо двумерных.
В каких-то случаях это действительно будет работать, но всё же есть несколько сомнительных моментов:
- Хотя изображения тоже могут быть разного размера, всё же в датасете редко попадаются рядом картинки и , а среди, скажем, отзывов на ресторан могут попадаться как труды, сопоставимые по размеру с «Войной и миром», так и безликие «Да, вроде норм». И если обработать слишком длинное предложение нам поможет (с потерей информации, конечно) global pooling, слишком короткое может что-нибудь поломать, особенно если мы забываем про паддинг.
- Слегка философское соображение. Изображение однородно, в нём нет предпочтительных направлений, тогда как текст пишется и читается последовательно. Нам может показаться, что это стоит использовать: при обработке очередного токена обращаться к предыдущим, как к его контексту.
В последнем соображении уже непосредственно видна идея рекуррентных нейронных сетей (recurrent networks, RNN):

Давайте разберёмся, что тут происходит. Чтобы хранить информацию о предыдущих токенах, мы вводим понятие внутренней памяти или скрытого состояния (hidden state, векторы ). В простейшем случае оно выражается одним вектором фиксированной размерности. На каждом (дискретном) шаге в сеть подаются данные (например, эмбеддинг токена), при этом происходит обновление скрытого состояния.
Пример:
после чего по скрытому состоянию предсказывается выходной сигнал, к примеру, следующим образом:
Обратите внимание, что веса одинаковы на всех итерациях, то есть вы можете представлять себе, что очередные и подаются на вход одного и того же слоя, зацикленного на себе.
Рекуррентную сеть можно обучать на ошибку, равную суммарному отклонению по всем выходных сигналам нашей сети.
Вопрос на подумать. Как инициализировать веса мы, наверное, понимаем (про это можно почитать в параграфе про тонкости обучения нейросетей). А как инициализировать начальное скрытое состояние ? Можно ли инициализировать его нулём?
Ответ (не открывайте сразу; сначала подумайте сами!)
Важно разобраться, что в данном случае значит «инициализировать». Сравнение с инициализацией не работает, поскольку пока не объявлялся обучаемым параметром (хотя его, конечно, можно и обучать, если очень хочется). Можно всегда полагать нулём: как во время обучения, так и во время применения. И так действительно можно делать: в конце концов, скрытое состояние хранит информацию о предыдущих элементов последовательности, а до первого шага никакой информации нет.
Нетрудно представить себе и нейросеть с несколькими рекуррентными слоями: первый слой RNN будет принимать на вход исходную последовательность, вторая RNN — выходы первой сети, третья — выходы второй и т.д. Такие сети называют глубокими рекуррентными сетями.
Вот пример схему глубокой рекуррентной сети:

Вы, наверное, заметили, что описанная выше архитектура RNN решает синхронизованную версию задачи many-to-many. Её, впрочем, легко переделать для решения задачи many-to-one: достаточно убрать все выходы, кроме последнего:

Bidirectional RNN
Стандартная RNN учитывает только предыдущий контекст. Но ведь слово в предложении связано не только с предыдущими, но и с последующими словами. В таких случаях имеет смысл использовать двунаправленную рекуррентную сеть (bidirectional RNN, BRNN).
Как следует из названия, в bidirectional RNN есть две рекуррентных подсети: прямая (forward, токены в нее подаются от первого к последнему) и обратная (backward, токены подаются в обраттном порядке).
Вот пример такой архитектуры:

Конечно, формула для может быть и другой. Например, выходы обеих рекуррентных сетей могут агрегироваться путем усреднения, или суммирования, или любым другим способом.
Обратите внимание, что двунаправленная рекуррентная сеть работает с входом фиксированного размера, и по-прежнему не может решать не синхронизованный вариант задачи many-to-many. Backward RNN должна точно знать, где заканчивается входная последовательность, чтобы начать её обрабатывать с конца. Зато такая архитектура может помочь в решении задачи определения именованных сущностей или частей речи, использоваться в качестве энкодера в машинном переводе и так далее.
Взрыв и затухание градиента в RNN
При всех неоспоримых плюсах описанной выше глубокой рекуррентной архитектуры, на практике обычно используется её модифицированный вариант, который позволяет бороться с проблемой затухания или зашкаливания (взрыва) градиентов. Давайте разберёмся подробнее, почему она возникает.
Рассмотрим функцию потерь , измеряющую отклонение предсказанного -го выхода от истинного (напомним, что архитектура many-to-many обучается на , а архитектура many-to-one — на ). Выход зависит от скрытого состояния , а то, в свою очередь, от всех . Обновление градиента при переходе через преобразование имеет, как мы хорошо знаем, вид
То есть в ходе вычисления мы раз будем умножать на . Если у есть собственные значения, по модулю большие , и нам не посчастливится попадать в их окрестность, градиент будет стремиться к бесконечности («взрываться»).
Такие градиенты делают обучение нестабильным, а в крайнем случае значения весов могут стать настолько большими, что произойдет численное переполнение, и значения весов перестанут обновляться. Если же у есть маленькие собственные значения, градиент может затухать. В любом случае, эти проблемы делают получение информации от далеких по времени состояний затруднительным.
Теоретические выкладки о том, почему RNN без модификаций не могут достаточно хорошо учитывать долговременные зависимости, появились ещё в 90х. Их можно прочесть в статье Y.Bengio, 1994 или диссертации Josef Hochreiter, 1991.
Но как бороться с этой проблемой?
Простым инженерным решением является gradient clipping. Эта техника устанавливает максимально возможное значение градиента и заменяет все значения выше выбранного порога на это значение. При обратном распространении ошибки пробрасывается «ограниченный» градиент:
где — гиперпараметр, подбираемый порог.
Но сам по себе gradient clipping это довольно грубый инструмент. Поэтому были придуманы сложные модификации рекуррентных сетей, позволяющие им выучивать длинные зависимости.
LSTM
Вдохновение при написании этого параграфа черпалось из статьи в блоге исследователя Кристофера Олаха, из него же взяты иллюстрации.
Сеть с долговременной и кратковременной памятью (Long short term memory, LSTM) частично решает проблему исчезновения или зашкаливания градиентов в процессе обучения рекуррентных сетей методом обратного распространения ошибки. Эта архитектура была предложена Hochreiter & Schmidhuber в 1997 году. LSTM построена таким образом, чтобы учитывать долговременные зависимости.
Рассмотрим подробнее архитектуру LSTM.
Все рекуррентные сети можно представить в виде цепочки из повторяющихся блоков. В RNN таким блоком обычно является один линейный слой с гиперболическим тангенсом в качестве функции активации. В LSTM повторяющийся блок имеет более сложную структуру, состоящую не из одного, а из четырех слоев. Кроме скрытого состояния , в LSTM появляется понятие состояния блока (cell state, ).
Cell state будет играть роль внутренней, закрытой информации LSTM-блока, тогда как скрытое состояние теперь становится передаваемым наружу (не только в следующий блок, но и на следующий слой или выход всей сети) значением. LSTM может добавлять или удалять определенную информацию из cell state с помощью специальных механизмов, которые называются gates (ворота или вентили в русскоязычной литературе).
Рассмотрим этот механизм подробнее.
Основное назначение вентиля — контролировать количество проходящей через него информации. Для этого матрица, проходящая по каналу, который контролирует вентиль, поточечно умножается на выражение вида
Сигмоида выдает значение от до . Оно означает, какая доля информации сможет пройти через вентиль. Рассмотрим типы гейтов в том порядке, в каком они применяются в LSTM.
Forget gate (вентиль забывания). Он позволяет на основе предыдущего скрытого состояния и нового входа определить, какую долю информации из (состояния предыдущего блока) стоит пропустить дальше, а какую забыть.
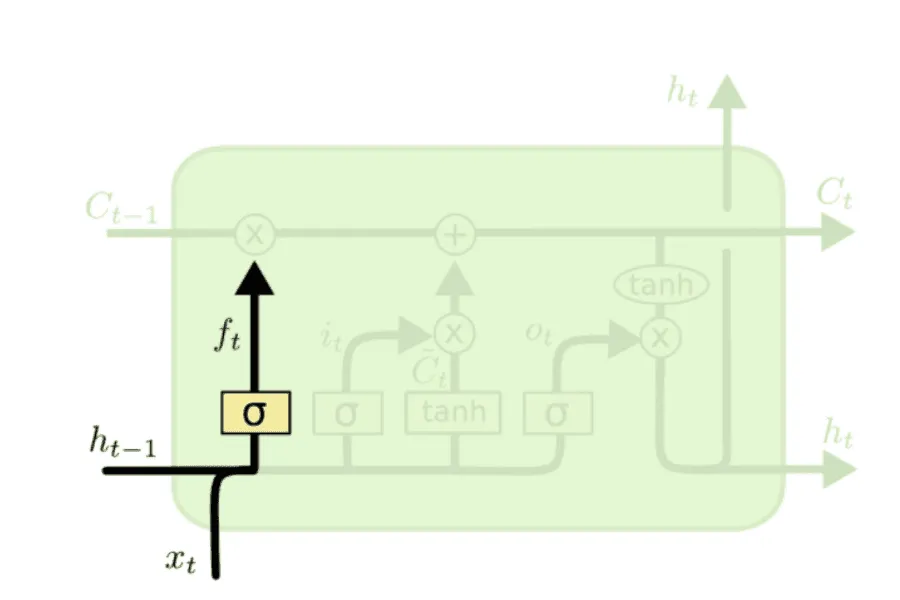
Доля сохраняемой информации из вычисляется следующим образом:
Дальше поэлементно умножается на .
Следующий шаг — определить, что нового мы внесём в cell state. Для этого у нас есть отличная кандидатура — уже привычное:
Но мы не уверены, что вся эта информация достаточно релевантна и достойна переноса в cell state, и хотим взять лишь некоторую её долю. Какую именно — поможет узнать наш следующий персонаж.
Input gate (вентиль входного состояния). Вычислим
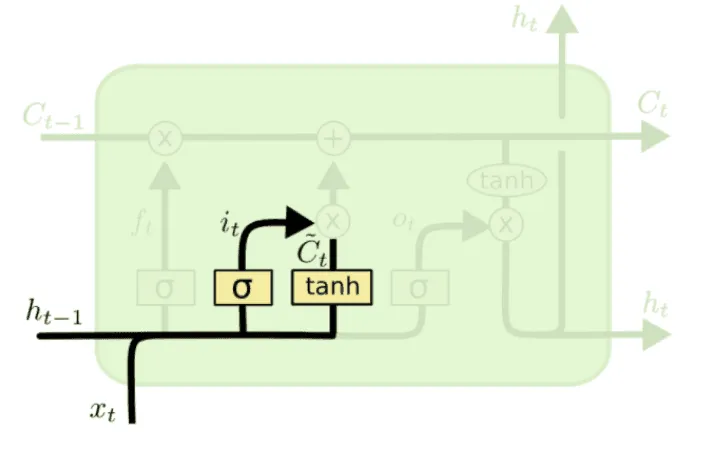
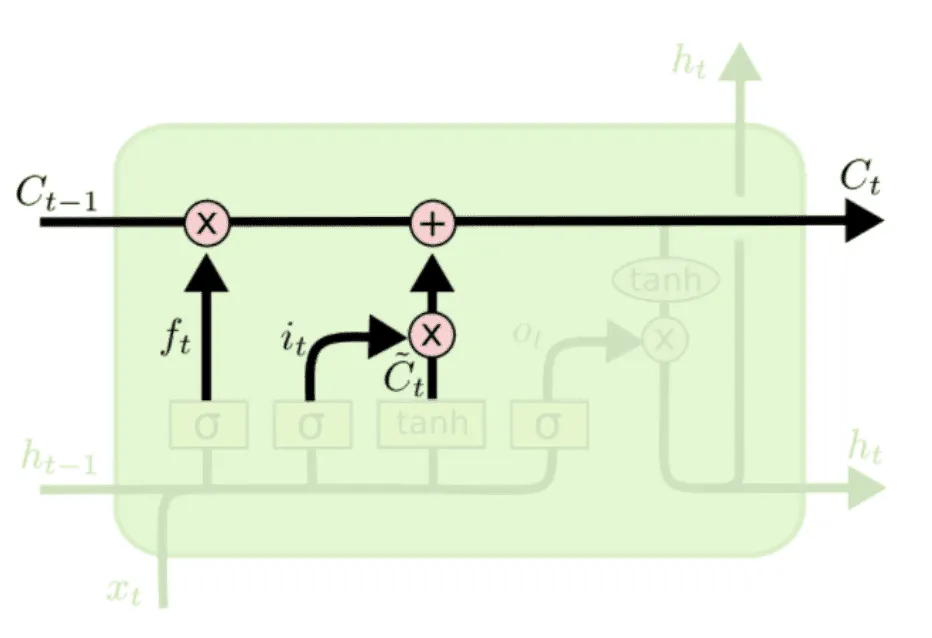
и умножим почленно на , чтобы получить информацию, которая поступит в cell state от и . А именно, новое состояние cell state будет равно:
где — это поэлементное умножение. Первое слагаемое отвечает за «забывание» нерелевантной информации из , а второе — за привнесение новой, релевантной.
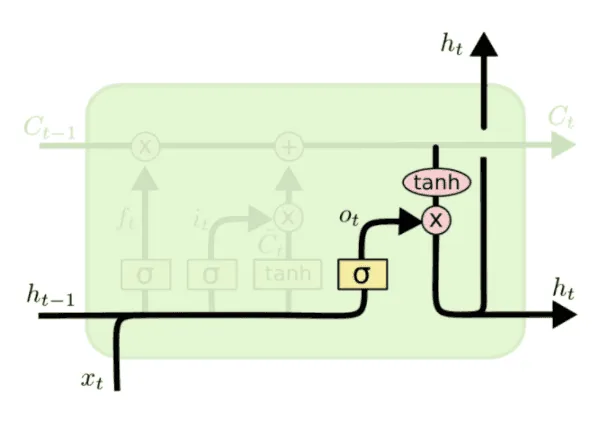
Как мы уже отмечали, роль выходного вектора LSTM-блока будет играть . Он вычисляется по cell state с помощью последнего вентиля.
Output gate (вентиль выходного состояния). Он отвечает на вопрос о том, сколько информации из cell state следует отдавать на выход из LSTM-блока. Доля вычисляется следующим образом:
Теперь пропускаем cell state через гиперболический тангенс, чтобы значения были в диапазоне от до , и умножаем полученный вектор на o_n, чтобы отфильтровать информацию из cell state, которую нужно подать на выход:
Описанная архитектура выглядит несколько сложно. Кроме того, вычисление четырех различных типов гейтов может быть вычислительно невыгодным. Поэтому были разработаны различные вариации LSTM, одна из самых популярных (Gated Recurrent Unit, GRU) освещена ниже.
Gated Recurrent Unit (GRU)
Gated Recurrent Unit был предложен в статье Cho et al. в 2014 году. GRU объединяет input gate и forget gate в один update gate, также устраняет разделение внутренней информации блока на hidden и cell state. Вот общий вид GRU-блока:
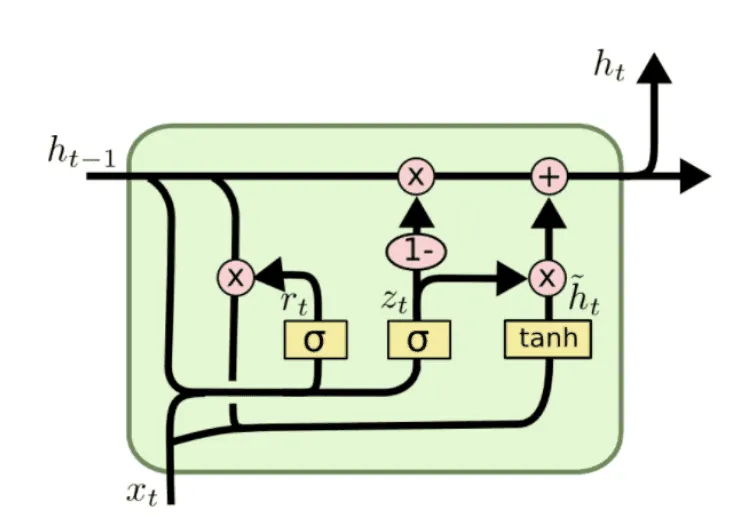
Внимательно посмотрев на структуру LSTM, можно заметить, что функции forget gate и input gate похожи. Первый механизм определяет, какие значения надо забыть, а второй — какие значения нового вектора нужно использовать для обновления старого cell state . Давайте объединим эти функции воедино: грубо говоря, будем забывать только те значения, которые собираемся обновить. Такую роль в GRU выполняет update gate ():
Новый тип гейта, который появляется в GRU — reset gate (). Он определяет, какую долю информации из с прошлого шага надо «сбросить», инициализировать заново.
Теперь мы вычисляем потенциальное обновление для скрытого состояния
и, наконец, решаем, что из старого забыть, а что из нового добавить:
В итоге GRU имеет меньше параметров, чем LSTM (в GRU нет output gate) и при прочих равных, быстрее учится. GRU и LSTM показывают сопоставимое качество на многих задачах, включая генерацию музыки, распознавание речи, многие задачи обработки естественного языка.
Модификации RNN, которые помогают лучше моделировать долгосрочные зависимости (LSTM, GRU) — важная веха развития нейросетей в NLP. Следующий большой этап в развитии — механизм внимания — мы рассмотрим чуть ниже.
Seq2seq
Вы, должно быть обратили внимание, что мы пока не касались задач, связанных с порождением последовательностей (синхронизованный варианты many-to-many не в счёт).
Действительно: имевшиеся у нас пока инструменты не позволяли генерировать последовательности произвольной длины. Но как тогда переводить с одного языка на другой? Ведь мы не знаем, какой должна быть длина перевода фразы, да и однозначного соответствия между словами исходного предложения и его перевода обычно нет.
Естественным решением для задачи sequence-to-sequence (seq2seq) является использование архитектуры энкодер-декодер, состоящей из кодировщика (энкодера) для кодирования информации об исходной последовательности в контекстном векторе (context vector) и декодировщика (декодера) для превращения закодированной энкодером информации в новую последовательность.

Очевидным выбором на роль энкодера и декодера являются рекуррентные сети, например, LSTM. Простейшая архитектура будет иметь вид:
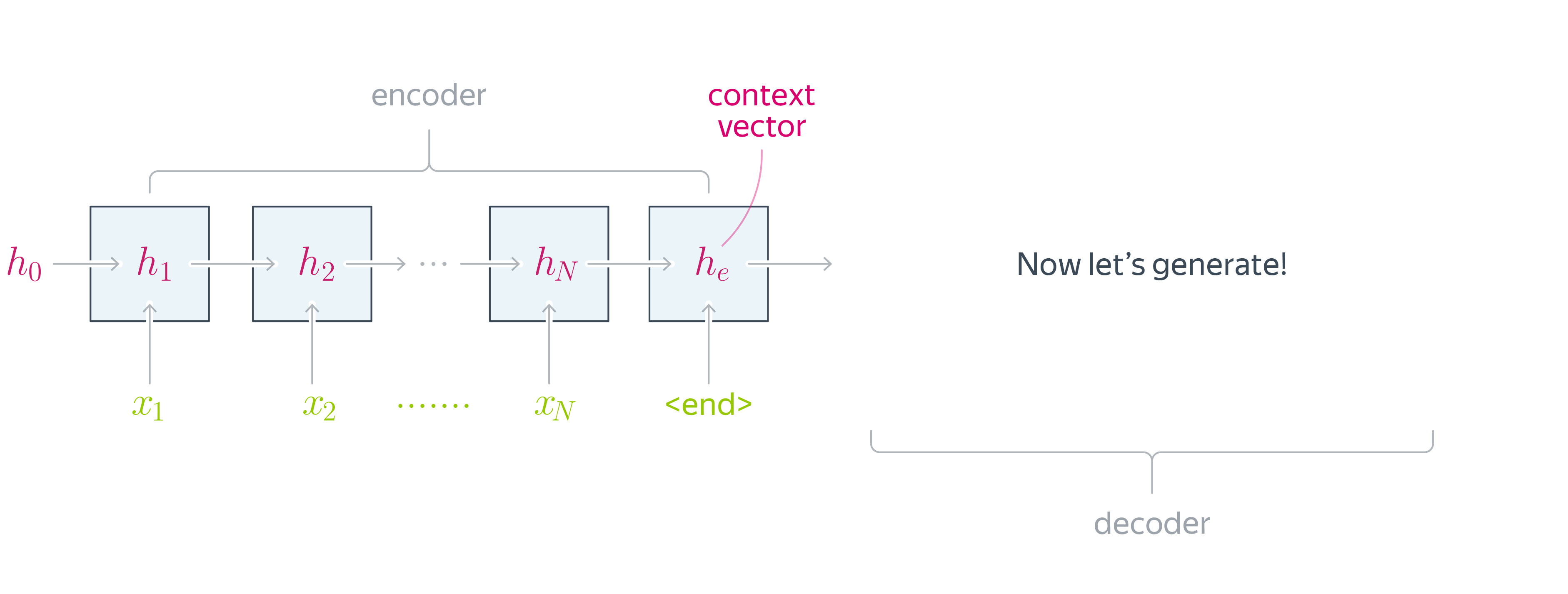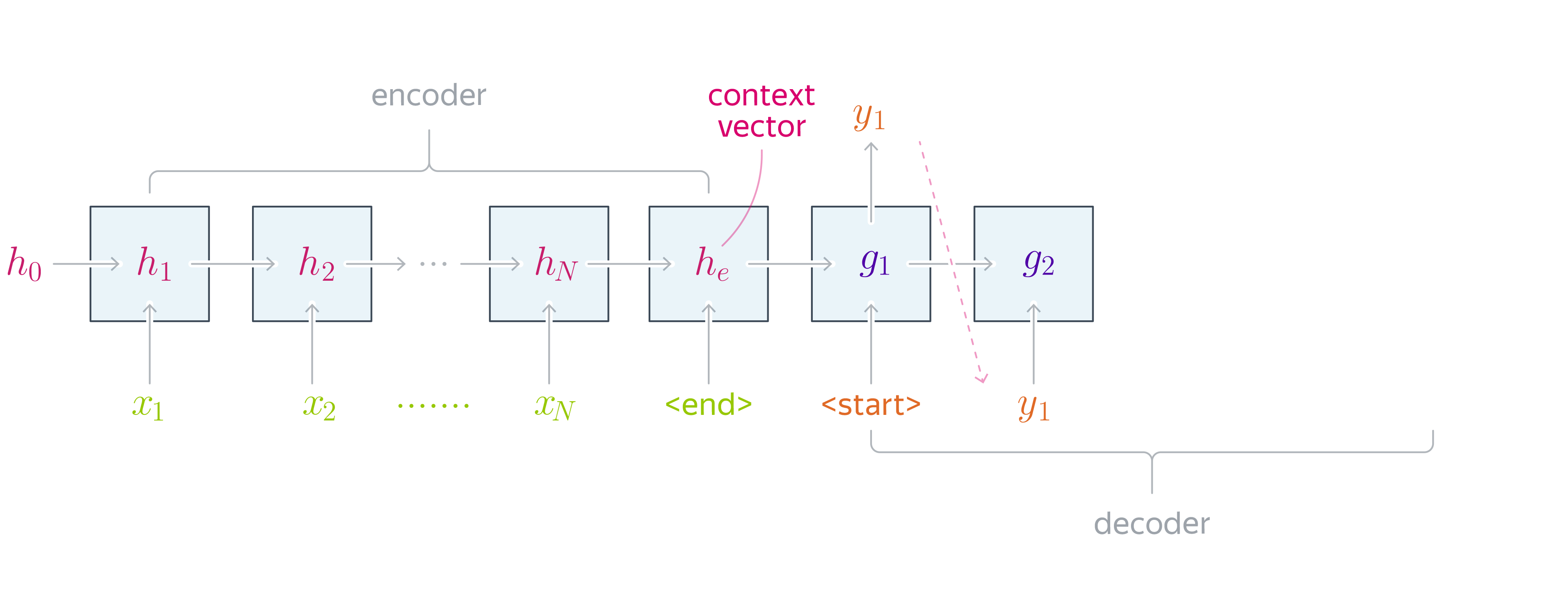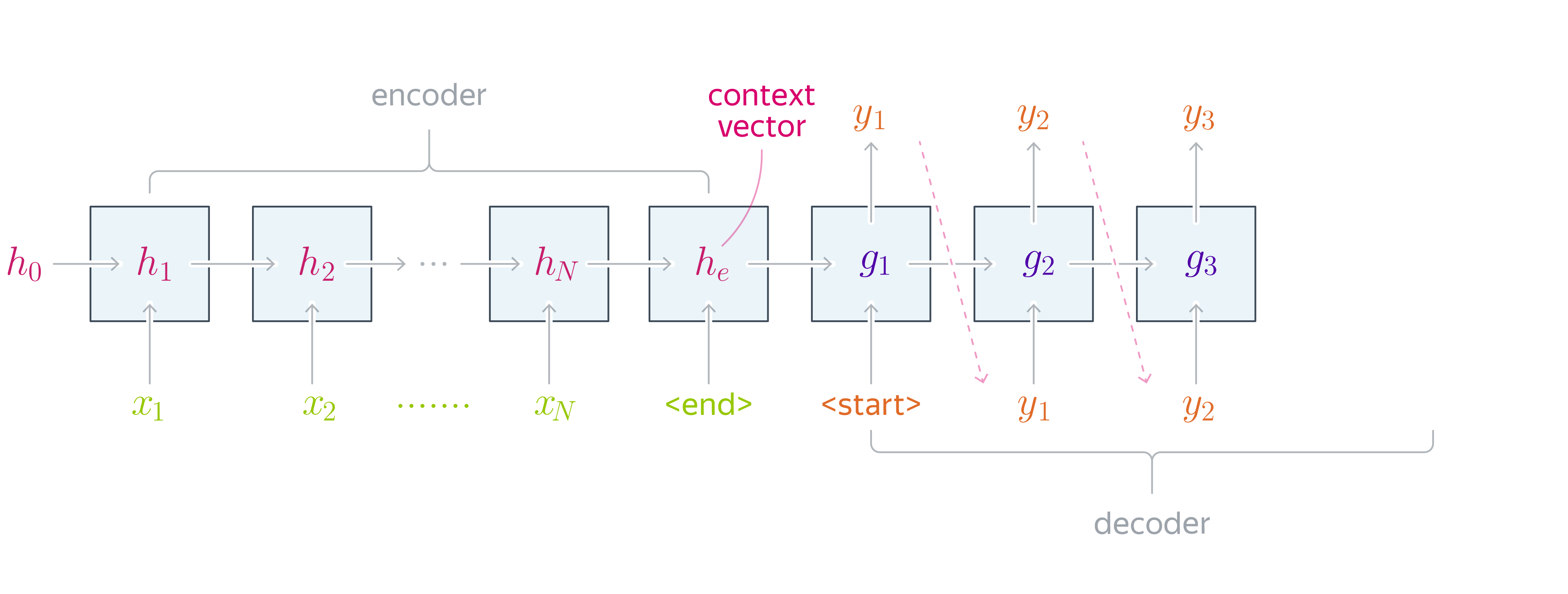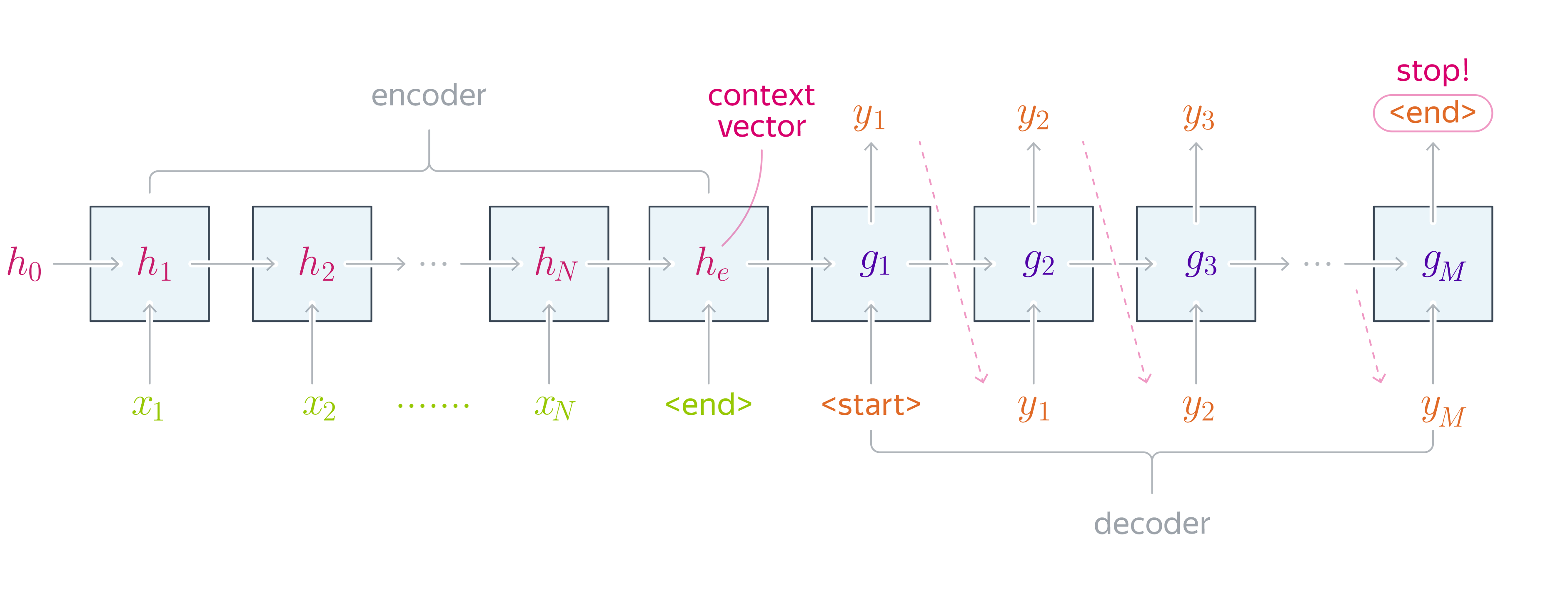
Рассмотрим подробнее энкодер и декодер.
Энкодер читает входное предложение токен за токеном и обрабатывает их с помощью блоков рекуррентной сети. Hidden state последнего блока становится контекстным вектором. Часто энкодер читает предложение в обратном порядке. Это делается для того, чтобы последний токен, который видит энкодер, совпал (или примерно совпал) с первыми токенами, которые будет генерировать декодер. Таким образом, декодеру проще начать процесс воссоздания предложения. Несколько первых правильных токенов сильно упрощают процесс дальнейшей генерации.
Архитектура декодера аналогична энкодеру. При этом каждый блок декодера должен учитывать токены, сгенерированные к текущему моменту, и также информацию о предложении на исходном языке. Вектор скрытого состояния в нулевом блоке декодера () инициализируется с помощью контекстного вектора.
Таким образом, декодер получит сжатое представление исходного предложения. Предложение генерируется следующим образом: в первый блок подаем метку начала последовательности (например, -токен, begin of sentence), на выходе первого блока получаем первый токен новой последовательности, и затем подаем его на вход следующего блока декодера. Повторяем аналогичную процедуру до тех пор, пока не сгенерируется метка конца последовательности (например, , end of sentence) или не будет достигнута максимально возможная длина предложения. Таким образом, декодер работает в режиме языковой модели, генерируя предложение токен за токеном и учитывая предыдущий контекст.
Разумеется, энкодер может быть и более сложным. Например, можно использовать многослойную двунаправленную сеть, лишь бы выходом её был один вектор контекста. С декодером сложнее: он должен порождать слова по одному, в одном направлении.
Далее мы очень коротко остановимся на нетривиальных моментах обучения и применения такой модели.
Тонкости применения
В предыдущих разделах мы не останавливались подробно на том, что происходит с выходами , но сейчас всё-таки попробуем разобраться. Если мы решаем задачу машинного перевода, то на очередном этапе декодер выдаёт нам условное распределение
на словах (или каких-то subword unit, например, BPE), из которого мы будем выбирать самое вероятное слово и подавать его на вход следующего блока. Но эта, жадная, стратегия может и подвести. Легко представить себе ситуацию, в которой самое вероятное на данный момент слово приведёт дальше к менее вероятной подпоследовательности:

Чтобы справиться с этим, на этапе применения модели используют beam search. В каждый момент времени мы поддерживаем некоторое количество самых вероятных гипотез, на -м шаге пытаясь продолжать все сохранённые, а из продолжений выбирая топ- по метрике

Число нет смысла делать большим (это и вычислительно будет тяжко, и может привести к более плохим результатам), можете брать в пределах .
Тонкости обучения
Как уже было сказано выше, на каждом шаге декодер предсказывает распределение вероятностей . Вся модель учится на сумму по всем кросс-энтропиям этих распределений с истинными .
Одна из сложностей такого обучения состоит в том, что единожды ошибившись и предсказав неправильный вместо истинного , модель скорее всего и следующие токены предскажет неверно, а это сделает всё дальнейшее обучение малополезным: ведь мы будем учить декодер предсказывать правильное продолжение неправильного начала. Одним из способов борьбы с этим является teacher forcing. Суть его в том, что на этапе обучения мы подаём на вход декодера не предсказанный им на предыдущем этапе токен, а истинный:

А как же one-to-many?
У нас остался лишь один неразобранный тип задач: one-to-many. К счастью, чтобы с ним справиться, ничего нового не нужно: достаточно уже знакомой модели энкодер-декодер, лишь с корректировкой энкодера.
Рассмотрим для примера задачу генерации подписей к изображениям (image captioning). Если мы уже умеем как-то превращать картинки в векторы, то эти векторы мы можем напрямую подавать в декодер в качестве векторов контекста:

Более подробно о том, как строить векторизации для изображений, вы узнаете в параграфе про обучение представлений.
А если у вас есть все данные мира, то вы можете в качестве энкодера взять свёрточную нейросеть и обучать её вместе с декодером end-to-end:

Механизм внимания (attention)
Как человек переводит предложения с одного языка на другой? Обычно переводчик уделяет особое внимание слову, которое записывает в данный момент. Хочется сообщить аналогичную интуицию нейронным сетям. Рассмотрим, как можно реализовать такой механизм на примере машинного перевода.
Внимательно посмотрим на seq2seq модель для машинного перевода. Вся информация о предложении на исходном языке заключена в контекстном векторе, но разные слова в предложении могут иметь разную смысловую значимость и следовательно, должны учитываться с разными весами. Кроме того, при генерации разных частей перевода следует обращать внимание на разные части исходного предложения. Например, первое слово переведенной фразы нередко связано с первыми словами в предложении, поданном на вход энкодеру, а порой одно слово перевода передаёт смысл нескольких слов, разбросанных по исходному предложению (вдруг кто-нибудь сталкивался с отделяемыми приставками в немецком?).
Механизм внимания (attention) реализует эту интуицию путем предоставления декодеру информации обо всех токенах исходного предложения на каждом шаге генерации. Рассмотрим классическую модель внимания, предложенную Bahdanau et al. в 2014 году.
Обозначим скрытые состояния энкодера , а скрытые состояния декодера . Важно отметить, что , это контекстный вектор. На каждом шаге декодера будем считать attention scores, умножая на вектор скрытого состояния каждого блока энкодера . Таким образом, получаем значений, указывающих, насколько каждый из токенов c номерами из исходного предложения важен для генерации токена из перевода:
(здесь и , как обычно, являются строками, так что — скаляр).
Теперь превращаем эти значения в attention distribution, применив к ним softmax:
Используем в качестве весов для нахождения окончательного вектора внимания :
Теперь в декодере на шаге i вместо вектора скрытого состояния будем использовать вектор -- конкатенацию скрытого состояния блока и соответствующего attention вектора. Таким образом, на каждом шаге декодер получает информацию о важности всех токенов входного предложения. Данная схема вычисления attention представлена на следующем рисунке.

Существует много разных видов механизмов внимания, например:
- Базовый dot-product, рассмотренный ранее:
- Мультипликативный: , где — обучаемая матрица весов.
- MLP: , где , — обучаемые матрицы весов, — обучаемый вектор весов
Важной особенностью механизма внимания является то, что его веса несут в себе информацию о связях слов в двух языках, участвующих в переводе. Визуализировав веса механизма внимания, получаем таблицу взаимосвязей между словами:

Весьма логично, что слово dogs теснее всего связано со словом собак, а слову очень соответствуют целых два слова: very и much.
Self-attention
В предыдущем разделе мы обсуждали применение механизма внимания во время работы декодера, но оказывается, что и энкодеру это может быть полезно.
Механизм внутреннего внимания (self-attention) используется, чтобы посмотреть на другие слова во входной последовательности во время кодирования конкретного слова. Изначально этот механизм был представлен в статье Attention is all you need как элемент архитектуры «трансформер» (Transformer).
Эффективность трансформера демонстировалась на примере задачи машинного перевода. Сейчас трансформеры и self-attention обрели огромную популярность и используются не только в NLP, но и в других областях (например, в компьютерном зрении: Vision Transformer, Video Transformer, Multimodal Transformer for Video Retrieval и так далее).
Более подробный обзор архитектуры Трансформер оставим курсу Лены Войта по NLP, а пока остановимся на механизме внутреннего внимания. Пусть на вход нейросети пришли два предложения «Мама мыла раму. Она держала в руках тряпку». Местоимение «она» относится к маме или к раме? Для человека это очень простой вопрос, но для модели машинного обучения — нет. Self-attention помогает выучить взаимосвязи между токенами в последовательности, моделируя «смысл» других релевантных слов в последовательности при обработке текущего токена.
Что происходит внутри self-attention-модуля? Для начала, из входного вектора (например, эмбеддинга каждого токена) формируются три вектора: Query (запрос), Key (ключ) и Value (значение). Они получаются с помощью умножения входного вектора на матрицы , и , веса которых учатся вместе со всеми остальными параметрами модели с помощью обратного распространения ошибки.
Выделение этих трех абстракций нужно, чтобы разграничить эмбеддинги, задающие «направление» внимания (query, key) и смысловую часть токена (value). Вектор query задает модальность «начальной точки» механизма внутреннего внимания (от какого токена направлено внимание), вектор key — модальность «конечной точки» (к какому токену направлено внимание). Таким образом, один и тот же токен может выступать как «начальной», так и «конечной» точкой направления внимания: self-attention вычисляется между всеми токенами в выбранном фрагменте текста.
Процесс происходит так: по очереди фиксируется каждый токен (становится query) и просчитывается степень его связанности со всеми оставшимися токенами. Для этого поочередно key-вектора всех токенов скалярно умножаются на query-вектор текущего токена. Полученные числа будут показывать, насколько важны остальные токены при кодировании query токена в конкретной позиции.
Дальше полученные числа надо нормализовать и пропустить через софтмакс, чтобы получить распределение. Затем подсчитывается взвешенная сумма value векторов,где в качестве весов используются полученные на предыдущем шаге вероятности. Полученный вектор и будет выходом слоя внутреннего внимания для одного токена. Изложенную выше схему вычисления self-attention вектора для одного токена можно представить простой схемой:
На практике self-attention не вычисляется для каждого токена по отдельности, вместо этого используются матричные вычисления. Например, вместо вычисления query, key и value векторов для каждого токена, настакаем эмбеддинги входных токенов в матрицу и посчитаем матрицы , и .
Затем происходит повторение описанных в предыдущем абзаце шагов, только для матриц. Посчитаем итоговую матрицу , подав матрицы Q, K и V в формулу:
В оригинальной статье Vaswani et al., 2017 в качестве нормализующей константы выбрали число 8 (квадратный корень размерности key-векторов). Нормализация приводила к более стабильным градиентам в процессе обучения.
Интересно, что обычно используют параллельно несколько self-attention блоков. Такая схема называется multi-head self-attention. Вычисление self-attention происходит несколько раз с разными матрицами весов, затем полученные матрицы конкатенируются и умножаются на еще одну матрицу весов (см. схему).
Это позволяет разным self-attention головам фокусироваться на разных взаимосвязях, например, одна голова может отвечать за признаковые описания, другая за действия, третья за отношения «объект-субъект». Разные головы могут вычисляться параллельно, при этом входная матрица эмбеддингов отображается в разные подпространства представлений, что значительно обогащает возможности внутреннего внимания моделировать взаимосвязи между словами. В виде формулы вычисление multihead self-attention можно представить так:
,
где

Есть много реализаций self-attention (PyTorch, TensorFlow). Также советуем ознакомиться с jupyter-ноутбуком от Гарвардской NLP-группы, в котором представлена реализация архитектуры «трансформер» с подробными объяснениями. Еще один отличный источник, позволяющий подробнее разобраться с self-attention и трансформером, - это статья Jay Alammar под названием «Illustrated Transformer».
Особенности работы с текстами
Предобработка текстов
Перед тем, как применять описанные выше архитектуры (или даже использовать простые подходы, вроде TF-IDF или word2vec), нужно разобраться, как делать предобработку текстов.
Первым делом надо научиться представлять связный текст в виде последовательности. Для начала имеет смысл разбить текст на предложения, а дальше уже на слова или символьные n-граммы. Этот процесс называется токенизацией. Можно делать токенизацию вручную, например, с помощью регулярных выражений, или воспользоваться готовыми методами из библиотеки NLTK.
Представим, что мы получили упорядоченный список слов, из которых состоит текст. Но это еще не все. Обычно тексты содержат разные грамматические формы одного и того же слова. Привести все словоформы к начальной форме можно с помощью лемматизации. Лемматизация - это алгоритм приведения слова к его начальной форме с использованием морфологическего анализа и знаний об особенностях конкретного языка.
Пример работы лемматизатора:
«собаки, собака, с собакой, собаками -> собака»
Другой способ приведения всех словоформ к одной форме - это стемминг. Стемминг — это более грубый процесс на основе эвристик, который действует без знания контекста, словарей и морфологии. Стеммер не поймет, что слова с чередованием имеют один и тот же корень (только если прописать в явном виде такую эвристику) или что слова «есть», «буду» и «был» - это формы глагола «быть». Стемминг - менее аккуратный процесс по сравнению с лемматизацией, зато гораздо более быстрый.
Еще один важный этап предобработки текстов - это удаление стоп-слов. Стоп-словами называют междометия, союзы, предлоги, артикли, в общем все слова, которые будут вносить шум в работу алгоритма машинного обучения. Иногда дополнительно убирают слова общей лексики, оставляя только специфические термины. Универсального списка слов не существует, но для начала можно использовать список стоп-слов из библиотеки NLTK.
Аугментации для текстов
Аугментации данных часто используются, чтобы увеличить количество данных в обучающей выборке, а также повысить обобщаемость модели. И если для компьютерного зрения аугментации относительно простые и могут выполняться на лету (масштабирование, обрезка, вращение, добавление шума и т.д.), то для текстов в виду грамматической структуры, синтаксиса и особенностей языка все не так просто.
Аугментации текста менее «автоматические», в идеале нужно понимать смысл фразы и иметь под рукой отлично работающий механизм перефразирования. Рассмотрим несколько популярных способов аугментации текстовых данных:
- Обратный перевод. Переводим исходный текст на какой-то язык, и затем переводим его обратно. Это помогает сохранить контекст, но при этом получить синонимичную формулировку.
- Замены слова на синонимичное/близкое по смыслу. Для этого можно использовать словари синонимов либо искать близкое слово в пространстве эмбеддингов, минимизируя расстояние между соответствующими векторами. В качестве таких эмбеддингов можно взять привычный word2vec, fasttext или контекстуализированные эмбеддинги на основе претренированных моделей (BERT, ELMO, GPT-2/GPT-3 и так далее).
- Вставка синонима слова в случайное место в предложении.
- Замена сокращения на полное наименование и обратно. Для английского языка этот способ более актуален, чем для русского.
- Случайная вставка/удаление/замена/перемена местами слов в предложении.
- Случайная перестановка местами предложений.
- Случайное изменение букв на произвольные/ближайшие на клавиатуре, добавление/исправление орфографических и пунктуационных ошибок, изменение регистра.
- MixUp для текстов. В задаче классификации смешиваем признаковые описания двух объектов и с такими же весами смешиваем их метки классов, получаем новый объект с признаками и меткой класса :
Для текстов признаковые описания можно смешивать на уровне слов (выбирать ближайшее слово в пространстве word embeddings) или на уровне предложений. Еще один вариант: сэмплировать слова из двух разных текстов с вероятностями и .
9. Аугментации с использованием синтаксического дерева предложения.
10. Генерация текста языковыми моделями. Например, генерация текста с помощью упоминавшейся ранее модели GPT-3.
Подробнее про некоторые методы аугментации текстов можно почитать в статье Easy Data Augmentation (EDA). Многие из описанных выше и в статье методов реализованы в библиотеке NLPAug, использование которой сильно упрощает задачу аугментации текстовых данных на практике.