

Для начала поймём, в чём отличие параметров модели от гиперпараметров:
- параметры настраиваются в процессе обучения модели на данных. Например, веса в линейной регрессии, нейросетях, структура решающего дерева;
- гиперпараметры — это характеристики модели, которые фиксируются до начала обучения: глубина решающего дерева, значение силы регуляризации в линейной модели, learning rate для градиентного спуска.
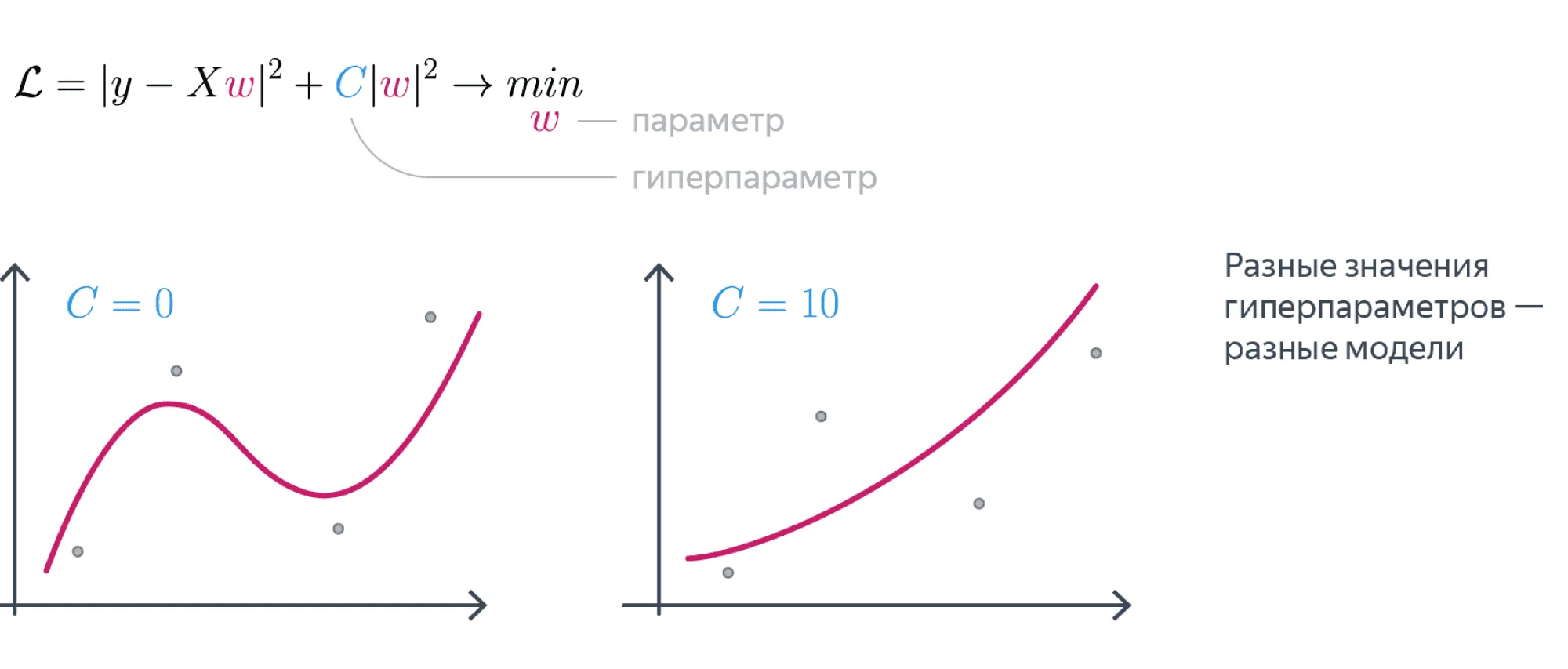
Рассмотрим, например, модель линейной регрессии:
где
- — веса модели;
- — матрица, в которой каждая строка содержит признаки одного объекта выборки (для удобства записи считаем, что первый столбец в этой матрице константный).
Эта модель может обучаться посредством минимизации следующего функционала:
где — целевая переменная, — коэффициент регуляризации. В процессе минимизации веса настраиваются по обучающей выборке, то есть являются параметрами. В то же время величина коэффициента регуляризации задаётся до начала обучения, то есть она — гиперпараметр.
Ещё хороший пример — решающее дерево. Его гиперпараметры: максимальная глубина дерева, критерий ветвления, минимальное число семплов в листе дерева и ещё много других. А параметр — сама структура решающего дерева: обучение состоит в том, чтобы на каждом уровне дерева выбрать, по какому признаку должно произойти ветвление и с каким пороговым значением этого признака.
Качество модели может очень сильно варьироваться в зависимости от гиперпараметров, поэтому существуют разнообразные методы и инструменты для их подбора. При этом, вне зависимости от выбранного вами метода подбора гиперпараметров, оценку и сравнение моделей нужно проводить грамотно. Пусть у нас есть несколько моделей разной природы (метод ближайших соседей, случайный лес, логистическая регрессия) или несколько нейросеток с разными архитектурами. Нужно для каждой из моделей подобрать гиперпараметры, а затем модели с наилучшими гиперпараметрами сравнить между собой.
Есть два наиболее часто используемых варианта.
Первый вариант
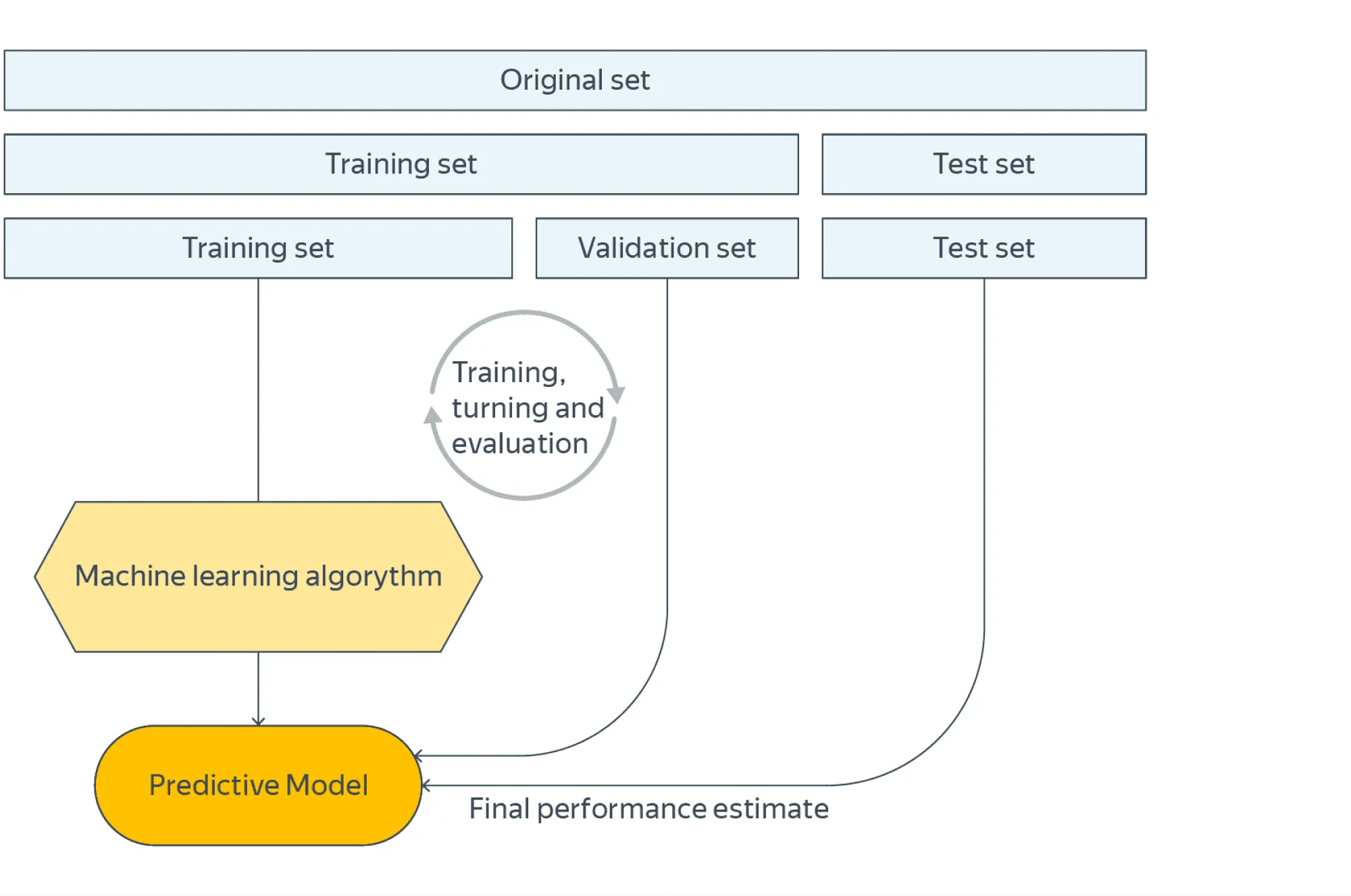
Разделить выборку на тренировочную, валидационную и тестовую части, для каждой модели выбирать гиперпараметры, максимизирующие её метрики на валидации, а окончательное сравнение моделей проводить по тестовым метрикам.
Разделения только на тренировочную и тестовую выборки недостаточно, так как в модель через подобранные гиперпараметры просачивается информация о тестовой выборке. Это означает, что на новых данных модели могут не сохранить свои качества и что их сравнение не будет честным.
Второй вариант
Провести кросс-валидацию.
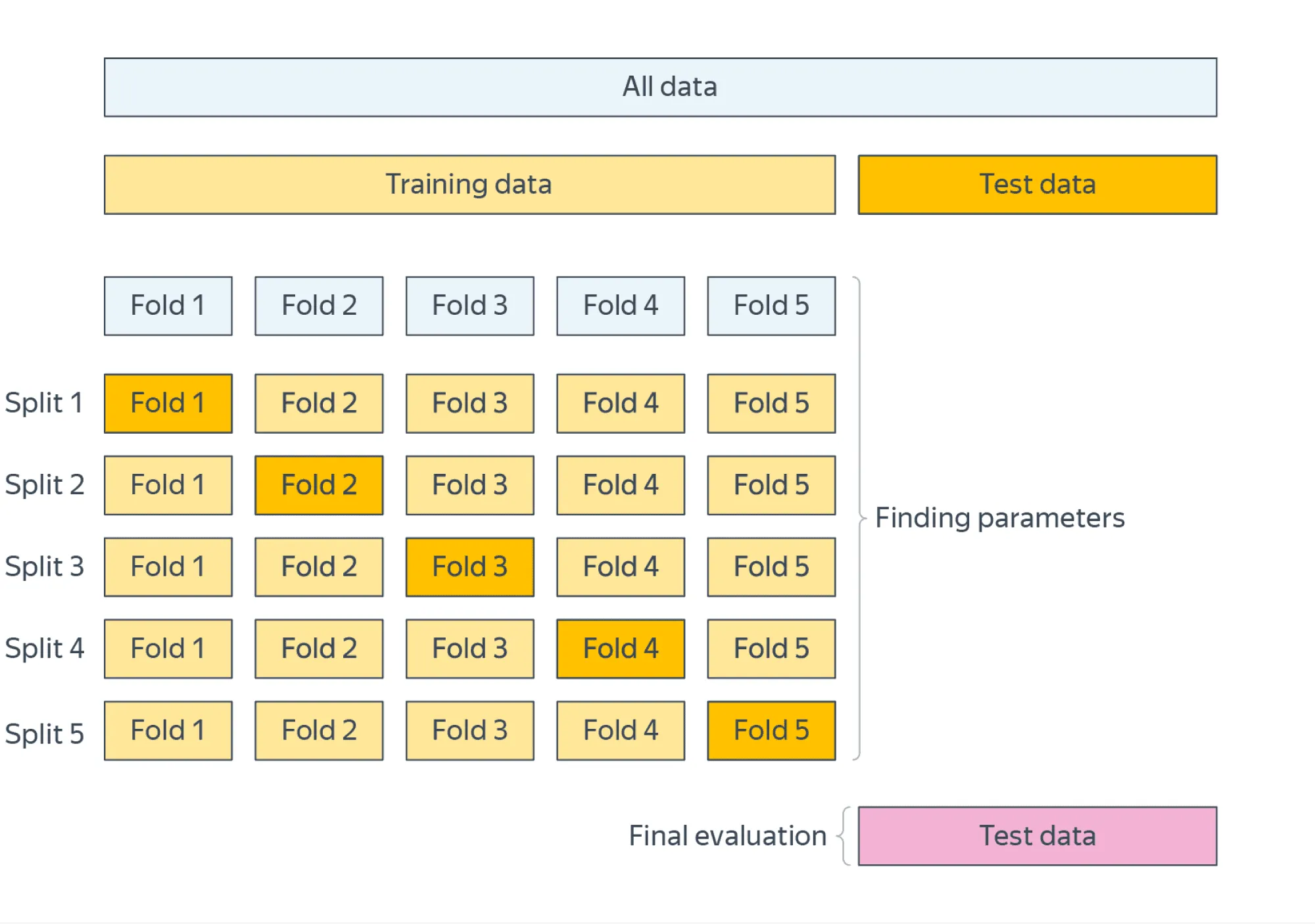
Кросс-валидация может быть нужна в случаях, если данных мало или мы не хотим зависеть от конкретного выбора валидационного множества. Примерный алгоритм:
- зафиксировать некоторое тестовое множество и отложить его;
- разделить оставшееся множество данных на фолдов (подмножеств), пройтись по ним циклом, на каждой итерации фиксируя один фолд в качестве валидационного и обучаясь на остальных;
- в качестве оценки качества модели взять среднее значение валидационной метрики по фолдам;
- финальное сравнение моделей с уже подобранными гиперпараметрами проводить на отложенном тестовом множестве.
Подробное описание процесса сравнения моделей между собой можно найти в параграфах, посвящённых кросс-валидации и сравнению и оценке качества моделей.
Далее мы рассмотрим несколько методов подбора гиперпараметров для моделей, а в конце будет приведён список питоновских библиотек, в которых эти методы реализованы, и дано верхнеуровневое сравнение всех описанных методов между собой.
Grid Search
Самый естественный способ организовать перебор наборов гиперпараметров — сделать перебор по сетке (Grid Search):
- для каждого гиперпараметра фиксируется несколько значений;
- перебираются все комбинации значений различных гиперпараметров, на каждой из этих комбинаций модель обучается и тестируется;
- выбирается комбинация, на которой модель показывает лучшее качество.
Примеры:
- для метода ближайших соседей можно, например, перебирать по сетке число соседей (например, от 1 до 20) и метрику, по которой будет измеряться расстояние между объектами выборки (евклидова, манхэттенская и так далее);
- для решающих деревьев можно перебирать по сетке сочетания значений максимальной глубины дерева и различные критерии ветвления (критерий Джини, энтропийный критерий).
Перебор некоторых значений гиперпараметров можно вести по логарифмической шкале, так как это позволяет быстрее определить правильный порядок параметра и в то же время значительно уменьшить время поиска. Так можно подбирать, например, значение learning rate для градиентного спуска, значение константы регуляризации для линейной регрессии или метода SVM.
Сразу же видно естественное ограничение данного метода: если комбинаций параметров слишком много либо каждое обучение / тест длится долго, алгоритм не завершится за разумное время.
Random Search
Если у вас возникает очень большое количество комбинаций параметров, вы можете какими-то способами пытаться справляться с этой проблемой:
- можно взять меньше значений каждого гиперпараметра, но тогда есть шансы пропустить наилучшую комбинацию;
- можно уменьшить число фолдов в кросс-валидации, но оценка параметров станет более шумной;
- можно оптимизировать параметры последовательно, а не перебирать их комбинации, но снова есть шанс получить неоптимальное решение;
- можно перебирать не все комбинации гиперпараметров, а только случайное подмножество.
Последний способ называется Random Search. Для каждого гиперпараметра задаётся распределение, из которого выбирается его значение, и комбинация гиперпараметров составляется семплированием из этих распределений (хорошие советы по поводу выбора распределений можно найти в документации sklearn). Таким образом, благодаря случайному выбору очередной комбинации гиперпараметров вы можете найти оптимальную комбинацию за меньшее число итераций.
Вот это изображение хорошо иллюстрирует отличия поиска по сетке от случайного поиска:
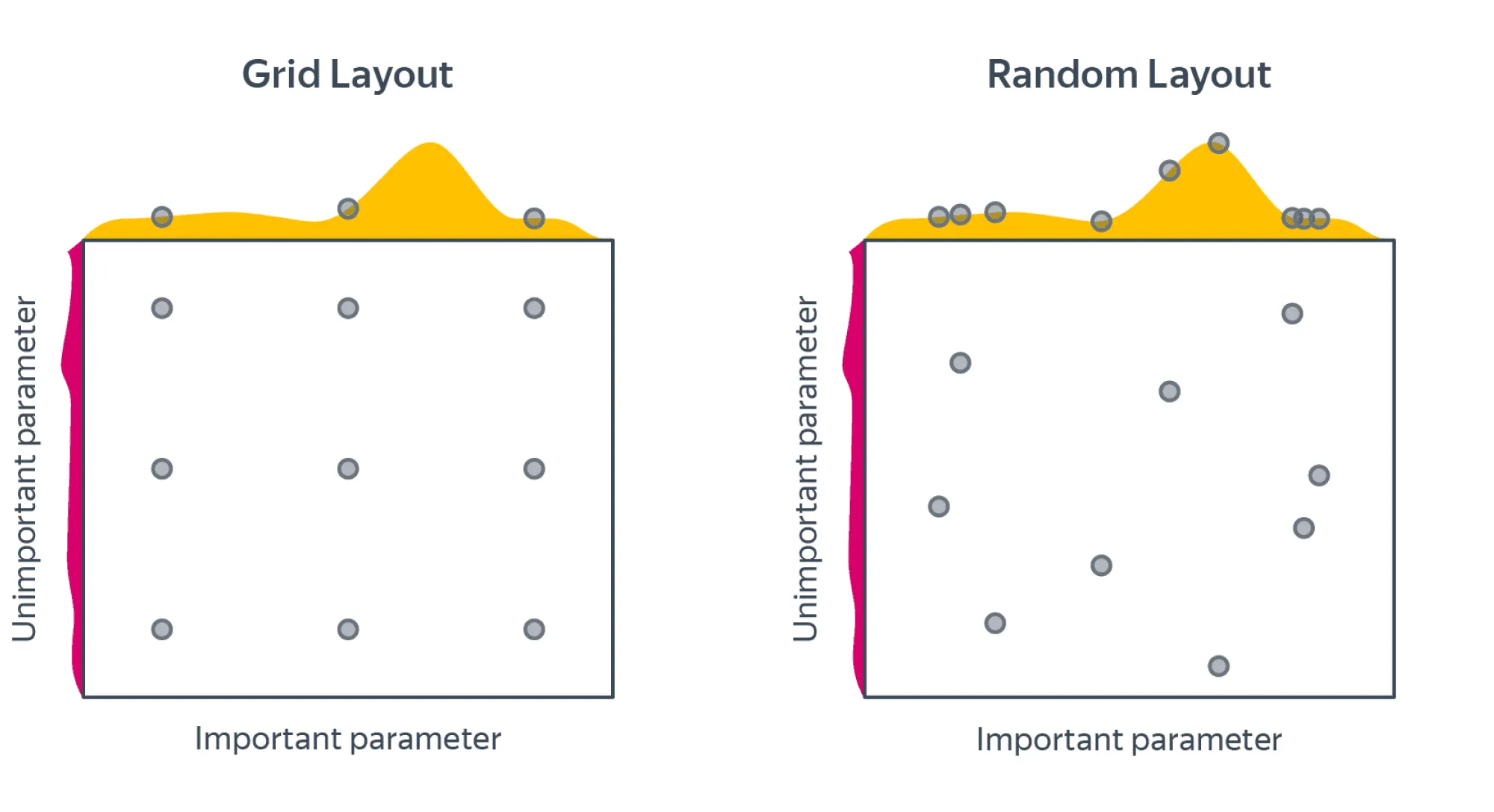
То есть: качество нашей модели в зависимости от гиперпараметров — это функция многих переменных с некоторой нетривиальной поверхностью. Но эта поверхность может зависеть от одной из своих переменных сильно меньше, чем от другой. Если бы мы знали, какой гиперпараметр важнее для перформанса модели, мы бы рассмотрели больше его возможных значений, но часто у нас нет такой информации, и мы рассматриваем некоторое наперёд заданное число значений для каждого гиперпараметра.
Random Search может за то же число итераций, что и Grid Search, рассмотреть более разнообразные значения гиперпараметров. Тем самым он с большей вероятностью найдёт те значения, которые больше всего влияют на качество модели, а значит, с большей вероятностью найдёт наилучшую комбинацию значений гиперпараметров.
Есть ещё одно довольно интересное объяснение, почему Random Search работает хорошо. Рассмотрим случай, когда у нас конечная сетка гиперпараметров (каждому гиперпараметру сопоставлено конечное число значений).
В этой сетке выделим группу размера от общего числа наборов гиперпараметров, на которой модель достигает лучшего качества (можно мысленно отранжировать все наборы по качеству в некоторый список и взять топ этого списка). Тогда некоторый набор гиперпараметров не попадает в эту группу с вероятностью . Если мы насемплировали наборов, то каждый из них не попал в эту группу с вероятностью , и, соответственно, вероятность того, что хотя бы один насемплированный набор попал в лучшую группу, равна . Мы можем решить неравенство
и выяснить, что при мы попадём в топ 5% с вероятностью, не меньшей . Это в большинстве случаев значительно быстрее, чем перебор всех комбинаций гиперпараметров с помощью Grid Search.
Если в рассуждении выше у нас некоторым гиперпараметрам соответствует непрерывное распределение, то всегда можно предположить, что мы уже насемплировали из этих распределений некоторое конечное число значений (равное числу итераций Random Search), а дальше считать, что мы работаем с конечной сеткой.
Конечно, остаётся наша зависимость от самой сетки гиперпараметров, и не всякая сетка обязана содержать в себе глобальный максимум перформанса модели или даже гиперпараметры из интервала вокруг него.
Exploration vs exploitation
В машинном обучении достаточно часто встречаются такие термины, как exploration и exploitation. Суть этих терминов хорошо поясняет следующий пример из реальной жизни. Допустим, перед вами стоит выбор, в какой ресторан пойти сегодня. Пусть ваш любимый ресторан находится прямо за углом.
Вы ходите туда каждый день и поэтому достаточно уверены в том, насколько вкусным будет ваш обед. Но при этом не рассматриваете никакие другие опции и, возможно, упускаете возможность поесть гораздо вкуснее в другом месте. Если же вы будете обедать каждый раз в новом месте, то очень часто будете не удовлетворены результатом.
В описанных далее методах подбора гиперпараметров будет так или иначе происходить поиск баланса между exploration и exploitation. Одно из основных отличий всех методов, которые будут описаны далее, от Grid Search и Random Search — возможность учитывать результаты предыдущих вычислений.
Одна из возможных стратегий выбора точки для следующей итерации — exploration: исследование тех областей, в которых у нас мало семплов на текущей итерации, что даёт нам возможность с меньшей вероятностью пропустить оптимальное значение.
Другая стратегия — exploitation: выбирать больше семплов в областях, которые мы достаточно неплохо изучили и где, как мы считаем, с большой вероятностью находится оптимум.
Байесовская оптимизация
Байесовская оптимизация — это итерационный метод, позволяющий оценить оптимум функции, не дифференцируя её. Кроме того, на каждой итерации метод указывает, в какой следующей точке мы с наибольшей вероятностью улучшим нашу текущую оценку оптимума. Это позволяет значительно сократить количество вычислений функции, каждое из которых может быть довольно затратным по времени.
Подбор гиперпараметров тоже можно сформулировать в виде задачи, которая может решаться с помощью байесовской оптимизации. Пусть, например, наша функция — значение валидационных метрик в зависимости от текущего сочетания гиперпараметров. Её вычисление затратно по времени (нужно натренировать и провалидировать модель), и мы не можем вычислить градиенты этой функции по её переменным (нашим гиперпараметрам).
Байесовская оптимизация имеет две основные компоненты:
- вероятностную модель, которая приближает распределение значений целевой функции в зависимости от имеющихся исторических данных (часто в качестве такой модели выбирают гауссовские процессы);
- функцию, которая позволяет по некоторым статистикам текущей вероятностной модели функции указать, в какой следующей точке нужно вычислить значение . Эта функция называется acquisition function. Она должна балансировать между exploration и exploitation в следующем смысле:
- exploration — исследовать те точки, в которых дисперсия нашей вероятностной модели велика;
- exploitation — исследовать те точки, где среднее нашей модели велико (и может служить оценкой максимума ).
Простой пример acquisition function — сумма среднего вероятностной модели и стандартного отклонения с некоторым весом:
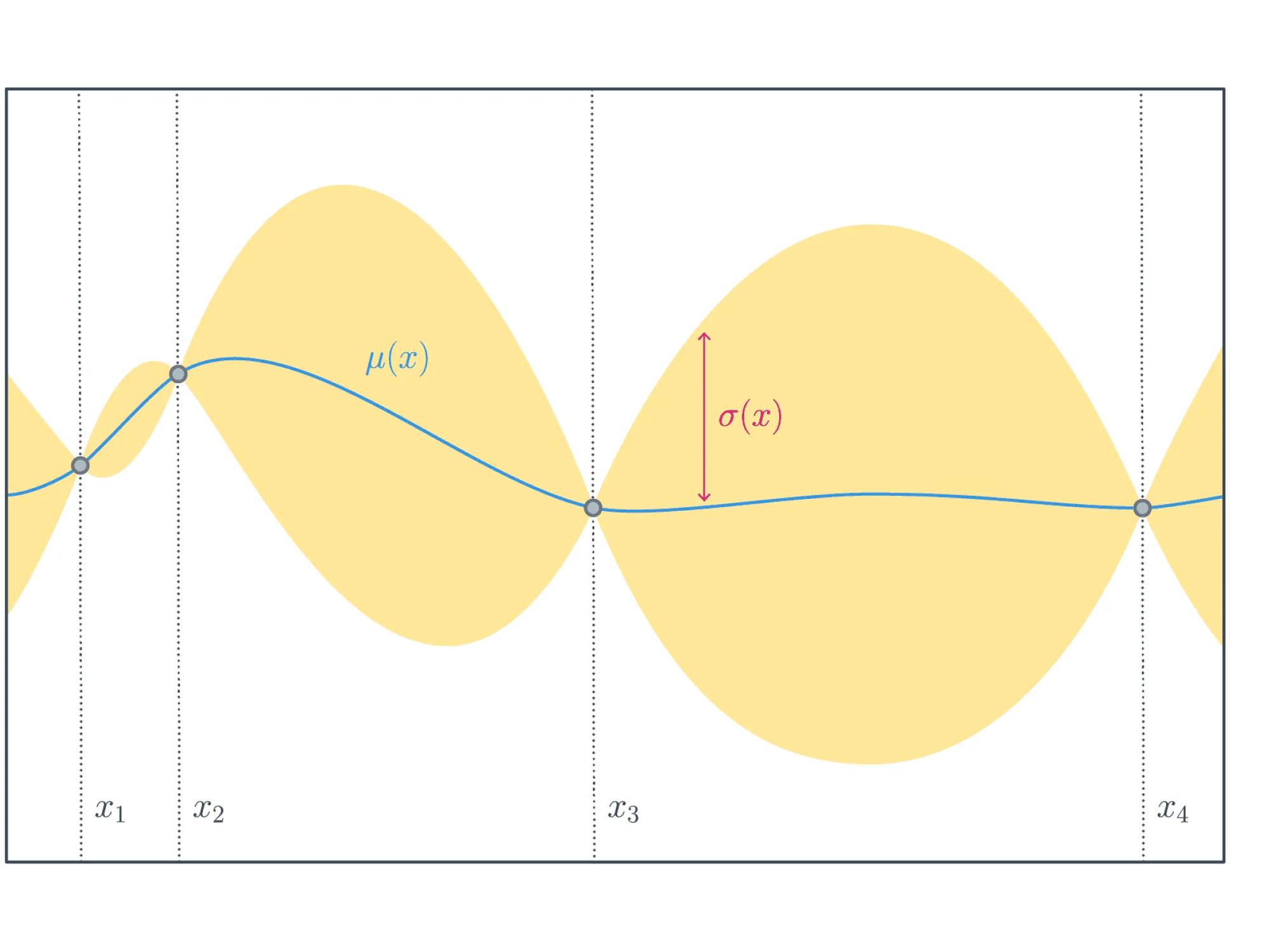
где — точка из пространства, в котором мы оптимизируем целевую функцию (в нашем контексте это вектор значений гиперпараметров). На картинке ниже изображены обе компоненты, из которых складывается данная acquisition function, — среднее вероятностной модели (синий график) и доверительный интервал, ширина которого в каждой точке пропорциональна стандартному отклонению вероятностной модели (жёлтая область).
Среднее модели стремится приблизить искомую функцию и в точности равно в тех точках, где значения известны. Доверительный интервал имеет переменную ширину, так как чем дальше находится некоторая точка от тех, значения в которых известны, тем более модель не уверена в том, какое значение функции в этой точке, и тем шире доверительный интервал. Наоборот, в точках, где значения известны, доверительный интервал имеет нулевой радиус.
Байесовская оптимизация в общем случае представляет из себя следующий алгоритм. Пусть — множество предыдущих наблюдений целевой функции : , а — некоторая acquisition function.
- На итерации вычисляется точка , в которой нужно провести следующее вычисление целевой функции:
- Вычисляется значение , и обновляется множество наблюдений .
- Обновляется статистическая модель.
Чтобы такой алгоритм работал эффективно, должна быть легко вычислимой и дифференцируемой.
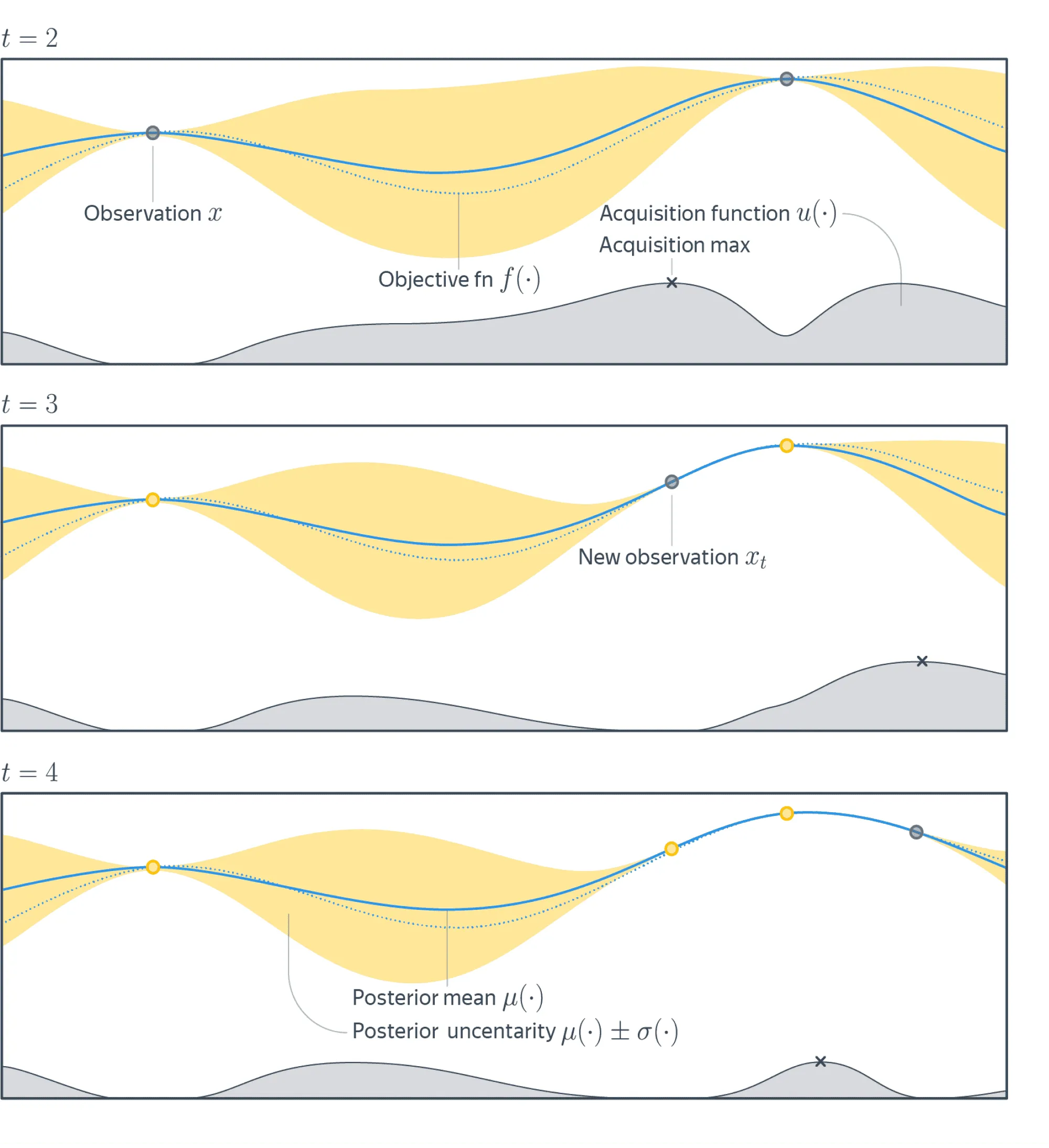
На рисунке ниже изображены три итерации этого алгоритма. Здесь пунктирная линия — это целевая функция, сплошная линия — график среднего вероятностной модели, жёлтым цветом обозначен доверительный интервал модели.
Серый график снизу — это график acquisition function. Её значения велики там, где вероятностная модель предсказывает большие значения целевой функции (exploitation), и там, где велика неуверенность вероятностной модели (exploration).
На каждой итерации находится точка максимума acquisition function (чёрный крестик), и следующая итерация произойдёт в этой точке (серый кружок на графике функции). На нижнем графике побеждает exploitation, так как acquisition function верно предсказала, что наблюдения из неизвестных областей слабо повлияют на нашу текущую оценку максимума .
Байесовская оптимизация хорошо работает, когда нужно оптимизировать небольшое число гиперпараметров, так как в наивной реализации алгоритм не поддаётся распараллеливанию. При большой размерности пространства гиперпараметров скорость сходимости не лучше, чем у обычного Random Search (как утверждается в этой статье).
Байесовская оптимизация в изначальной постановке предполагалась для работы с непрерывными гиперпараметрами, а для работы с категориальными гиперпараметрами ей нужны некоторые трюки:
-
Если нужно найти оптимальное значение только одного гиперпараметра и этот параметр категориальный, то можно, например, использовать Thompson sampling (как тут в разделе «Bernoulli bandit»). Вообще, проблему выбора наилучшего значения категориального гиперпараметра можно переформулировать как multi-armed bandit problem и использовать любой известный способ решения этой задачи.
-
Если категориальных гиперпараметров больше одного и кроме них есть некатегориальные, то:
- можно попробовать использовать специальные виды ядер в гауссовских процессах, как, например, сделано здесь;
- можно заменить гауссовские процессы на Random Forest (подробнее можно посмотреть здесь в разделе «Random Forests»).
Tree-structured Parzen Estimator (TPE)
Алгоритм TPE, как и алгоритм байесовской оптимизации, итерационный: на каждой итерации принимается решение о том, какие следующие значения гиперпараметров нужно выбрать, исходя из результатов предыдущих итераций. Но идейно имеет довольно сильные отличия.
Предположим сначала, что мы хотим сделать поиск оптимального значения для одного гиперпараметра.
На нескольких первых итерациях алгоритму требуется «разогрев»: нужно иметь некоторую группу значений данного гиперпараметра, на которой известно качество модели. Самый простой способ собрать такие наблюдения — провести несколько итераций Random Search (количество итераций определяется пользователем).
Следующим шагом будет разделение собранных во время разогрева данных на две группы. В первой группе будут те наблюдения, для которых модель продемонстрировала лучшее качество, а во второй — все остальные. Размер доли лучших наблюдений задаётся пользователем: чаще всего это 10-25% от всех наблюдений. Картинка ниже иллюстрирует такое разбиение:
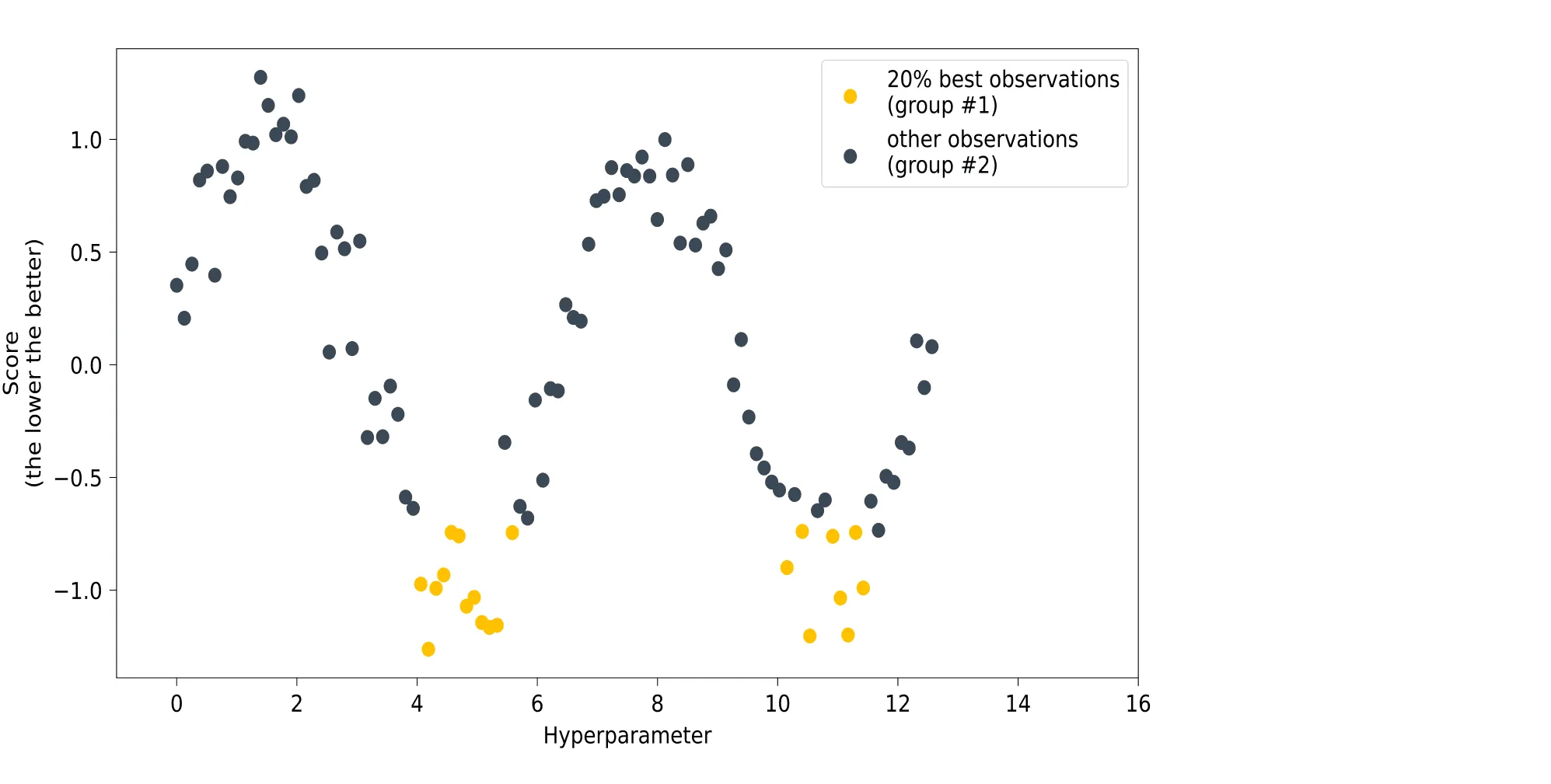
Далее некоторым образом строятся оценки распределения лучших наблюдений и распределения всех остальных в пространстве значений рассматриваемого гиперпараметра.
О том, как оцениваютсяи
Если гиперпараметр принимает непрерывные значения, то распределения и можно оценить на основе Parzen window density estimation. Идея данного метода в следующем. Пусть у нас имеются точки , которые были насемплированы из некоторого неизвестного распределения . Нам нужно каким-то образом оценить по известным данным. Для этого каждое наблюдение помещается в центр некоторого симметричного распределения с дисперсией , а оценкой для становится смесь этих распределений:
Распределения обычно называют ядрами, примеры ядер можно найти тут. На картинке ниже показана зависимость вида итогового распределения от параметра (который часто называют bandwidth):
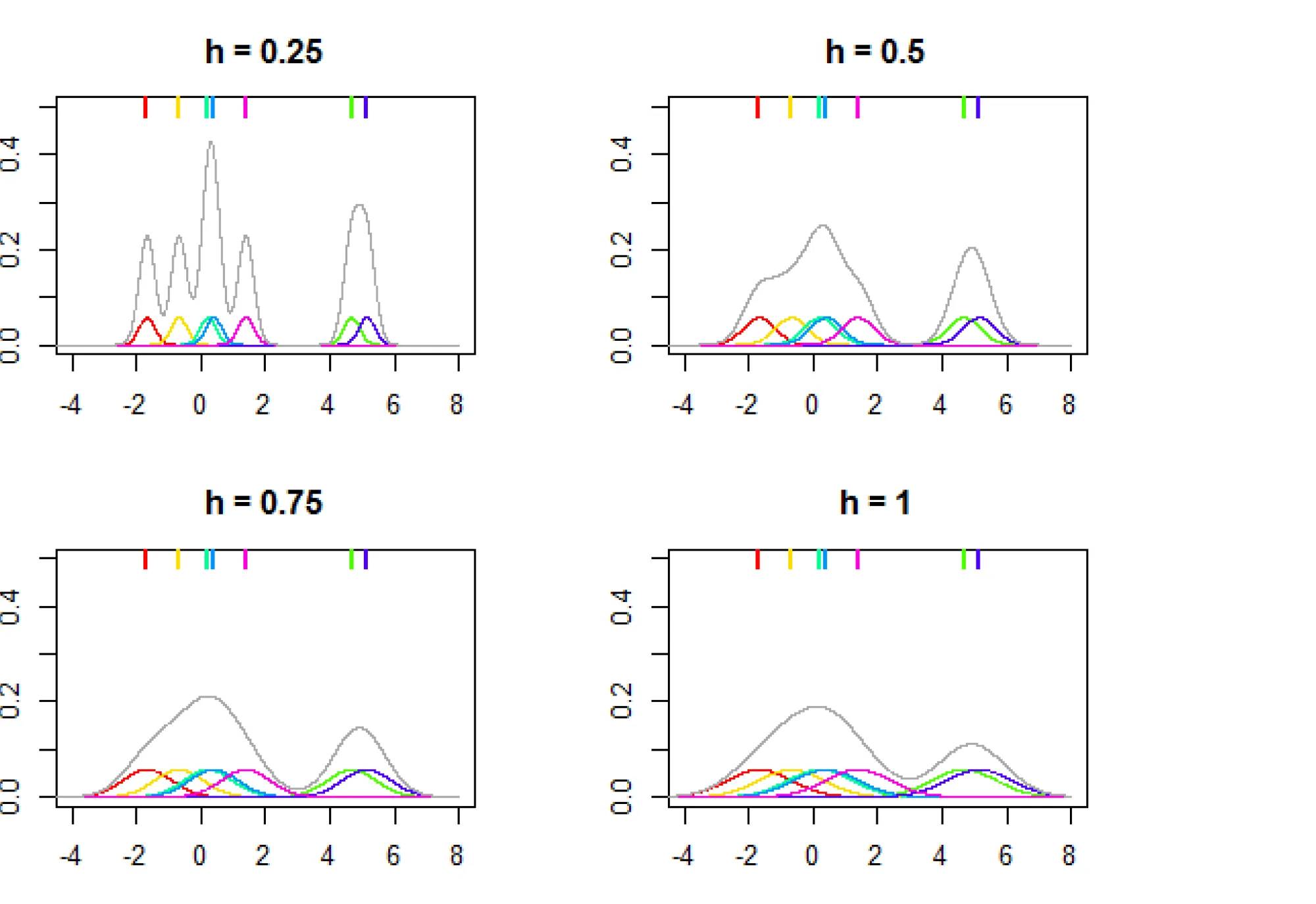
Чем больше у нас наблюдений, тем точнее можем оценить целевое распределение:
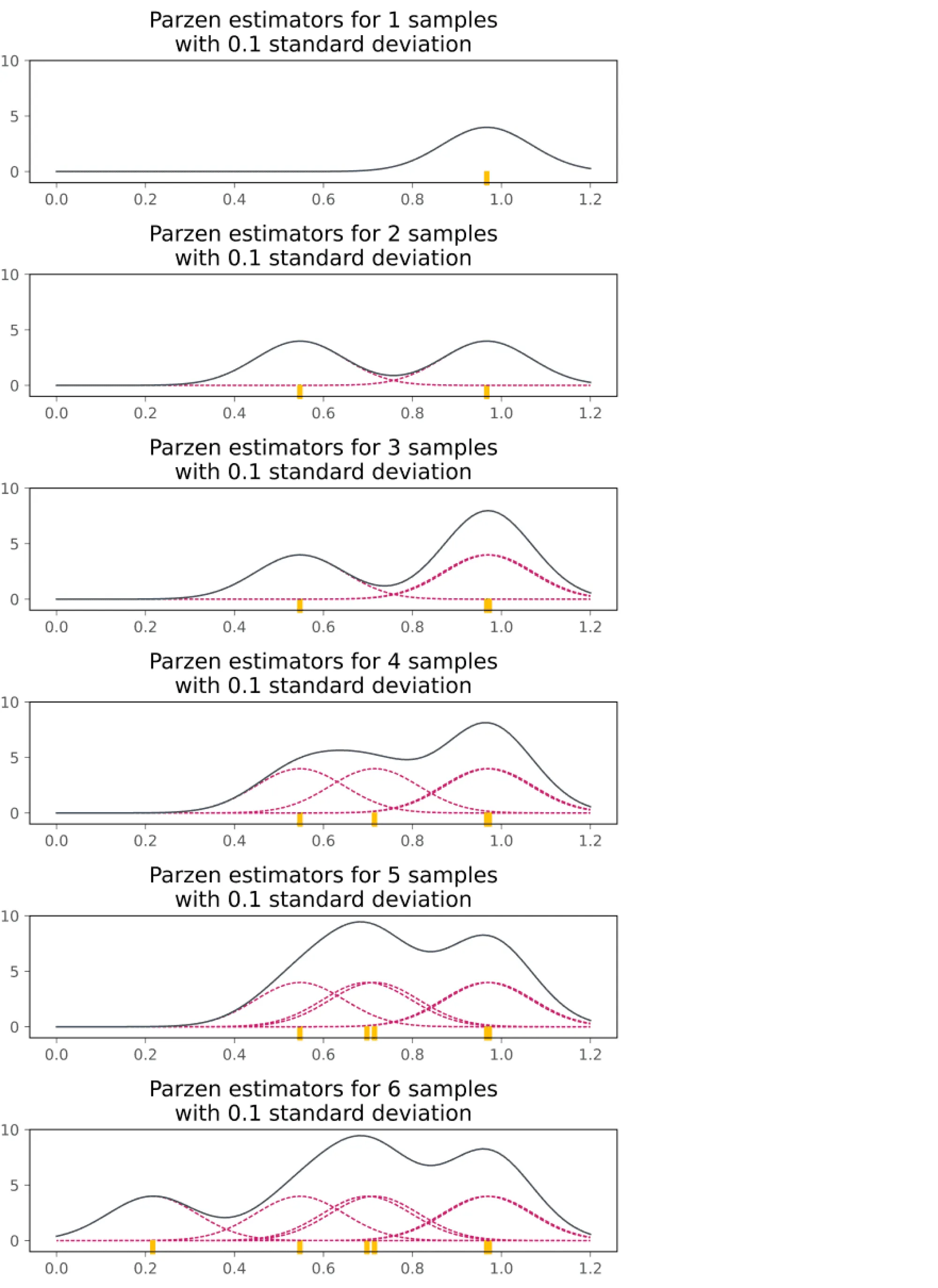
Если гиперпараметр категориальный и принимает значения , то в качестве и можно задать категориальные распределения в виде наборов из вероятностей , где соответствует вероятности насемплировать значение . Значения для будут пропорциональны числу раз, которое каждое из значений встретилось в группе лучших наблюдений (и, соответственно, худших наблюдений в случае ). Например, пусть у гиперпараметра всего 3 значения и уже прошло 60 итераций алгоритма. Пусть среди лучших 15 испытаний 2 раза встретилось значение , 5 раз встретилось значение и 8 раз встретилось значение . Тогда . Аналогично будет строиться .
На следующем шаге алгоритма мы семплируем несколько значений-кандидатов из распределения (количество таких семплирований тоже задаётся пользователем, можно задать их число равным, например, 1000). Из насемплированных кандидатов мы хотим найти тех, кто с большей вероятностью окажется в первой группе (состоящей из лучших наблюдений), чем во второй. Для этого для каждого кандидата вычисляется Expected Improvement:
Замечание: На самом деле стоит отметить, что в оригинальной статье величина имеет более общее определение. Но там же доказывается, что максимизация в исходном определении эквивалентна максимизации отношения выше.
Кандидат с наибольшим значением будет включён в множество рассматриваемых гиперпараметров на следующей итерации:
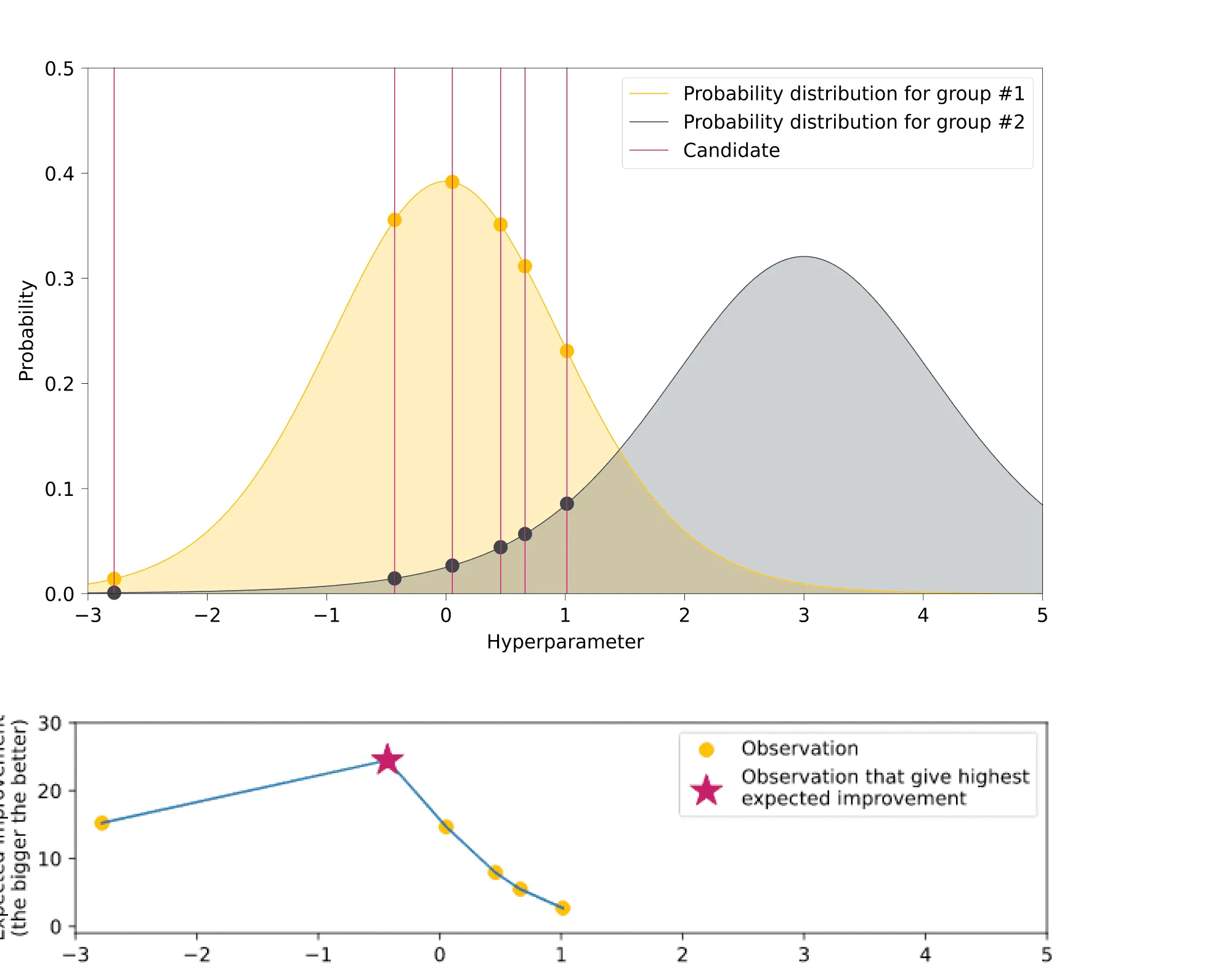
После того как было выбрано значение-кандидат, максимизирующее , обучается модель с этим значением гиперпараметра. После обучения мы замеряем её качество на валидационной выборке и в соответствии с этим результатом обновляем распределения и : снова ранжируем всех имеющихся кандидатов по качеству модели с учётом последнего, из топ 10-25% формируется обновлённое , из остальных — . Так происходит столько раз, сколько итераций алгоритма мы задали.
Теперь опишем, как алгоритм работает в общем случае, когда гиперпараметров более одного. Алгоритм работает с гиперпараметрами, представляя их в форме дерева (отсюда «tree» в названии). Например, в документации Hyperopt можно увидеть такой пример:
1from hyperopt import hp
2
3space = hp.choice('classifier_type', [
4 {
5 'type': 'naive_bayes',
6 },
7 {
8 'type': 'svm',
9 'C': hp.lognormal('svm_C', 0, 1),
10 'kernel': hp.choice('svm_kernel', [
11 {'ktype': 'linear'},
12 {'ktype': 'RBF', 'width': hp.lognormal('svm_rbf_width', 0, 1)},
13 ]),
14 },
15 {
16 'type': 'dtree',
17 'criterion': hp.choice('dtree_criterion', ['gini', 'entropy']),
18 'max_depth': hp.choice('dtree_max_depth',
19 [None, hp.qlognormal('dtree_max_depth_int', 3, 1, 1)]),
20 'min_samples_split': hp.qlognormal('dtree_min_samples_split', 2, 1, 1),
21 },
22])
На рисунке ниже изображено дерево, соответствующее данному примеру:
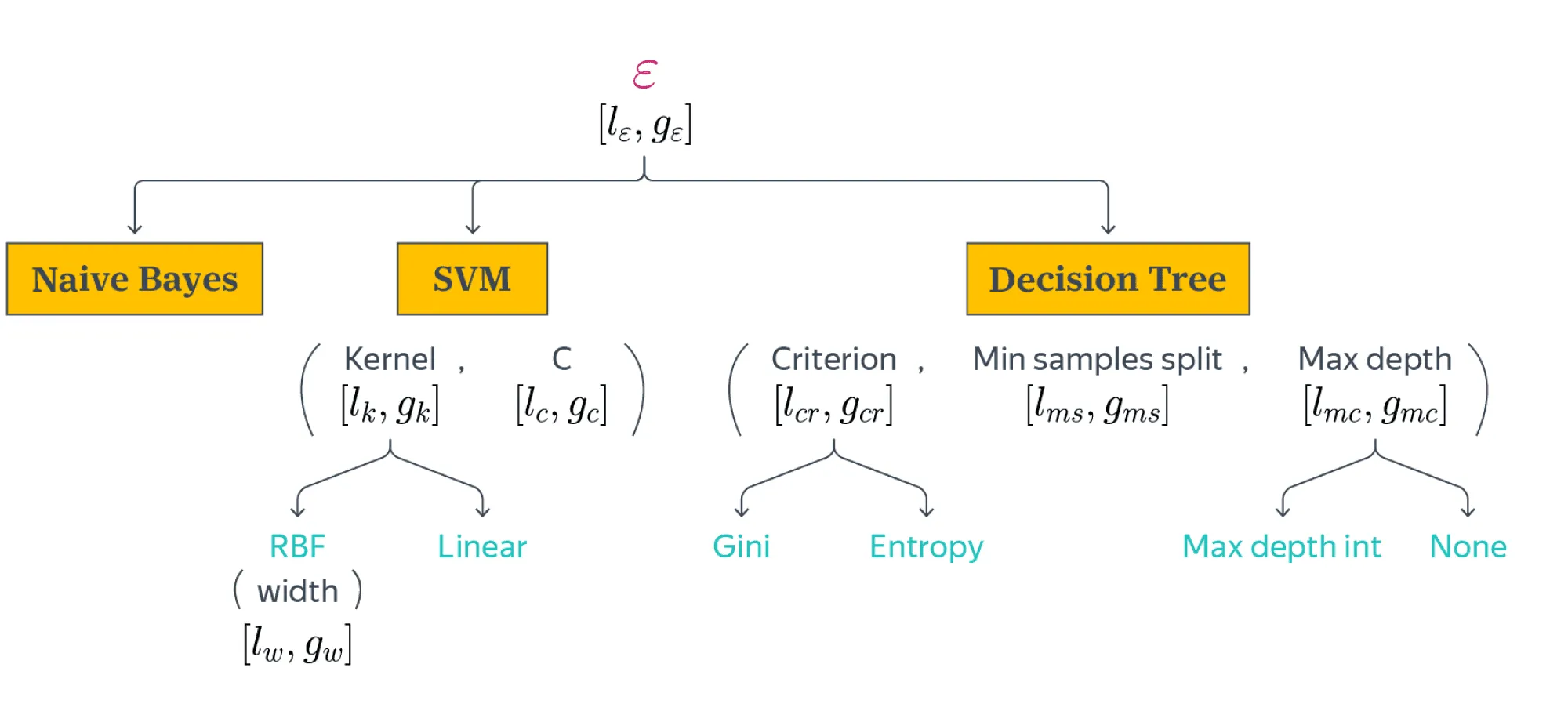
Корень дерева — фиктивная вершина, введённая для удобства. Здесь первый уровень дерева — выбор классификатора (наивный байес, SVM, решающее дерево). Дальнейшие уровни — гиперпараметры самих классификаторов и зависящие уже от них гиперпараметры (например, SVM kernel RBF width). Движение по дереву во время итераций алгоритма происходит по некоторому пути от корня к листу и обратно вдоль пройденного пути (этот процесс подробнее описан ниже).
Под некоторыми вершинами записан набор гиперпараметров в скобках (например, kernel и C под SVM). Это означает, что при приходе в эту вершину значения всех гиперпараметров, перечисленных в скобках, должны так или иначе быть выбраны.
Каждой вершине дерева, в которой будет происходить семплирование значений, сопоставляется своя пара и с учётом значений, насемплированных на этапе «разогрева». Каждому гиперпараметру, перечисленному в скобках, соответствует своя собственная пара. Если из названия гиперпараметра не идут стрелки (например, C у SVM и min_samples_split у Decision Tree), то это означает, что от его значения не зависят значения никаких других гиперпараметров.
Поэтому либо будет выбрано его значение, максимизирующее для соответствующих ему и , либо уже ничего не нужно семплировать (как, например, в вершинах linear или gini). Если же из гиперпараметра идут стрелки на следующий уровень, то с помощью максимизации будет выбрано, в каком направлении сделать переход. Например, из корня выбирается, какой классификатор рассмотреть на следующем этапе, а из параметра kernel можно перейти либо к RBF, либо к linear.
Теперь опишем сам алгоритм. Сначала так же, как и в одномерном случае, происходит «разогрев»: проводится некоторое количество итераций Random Search с теми изначальными распределениями, которые были заданы для гиперпараметров (в примере из Hyperopt эти распределения задаются как hp.qlognormal, hp.lognormal и так далее). Затем начинается итерационное обновление дерева гиперпараметров. Обновление дерева на каждой итерации происходит в два этапа:
- Сначала алгоритм идёт из корня дерева до некоторого листа. В каждой вершине для каждого соответствующего ей гиперпараметра он находит значение, максимизирующее . Если выбор значения для некоторого гиперпараметра означает переход на следующий уровень дерева, он идёт в ту вершину, которая соответствует максимизации . Так он идёт до тех пор, пока не упрётся в какой-то лист. Пройденный путь от корня до листа задаёт полный набор значений гиперпараметров для модели, и её с этими значениями можно провалидировать.
Пример
Пусть вы находитесь в корне и выбираете классификатор. Допустим, классификатор SVM оказался оптимальным по критерию . Вы переходите в соответствующую ему вершину, и здесь вам нужно провести семплирование значений для двух гиперпараметров: kernel и C. Для C вы выбираете некоторое значение, которое максимизирует . Пусть оно оказалось равно . А для kernel вы с помощью максимизации выбираете, в какую вершину на следующем уровне вы отправитесь. Пусть эта вершина — RBF. Для него вы семплируете конкретное значение width — пусть оно оказалось равным . Получилось, что вы прошли полный путь и получили модель с заданным набором гиперпараметров: , которую теперь можно провалидировать.
- После того как модель, полученная на предыдущем этапе, была провалидирована, распределения в вершинах дерева нужно обновить в соответствии с информацией о полученном качестве. Для этого алгоритм поднимается из листа наверх, обновляя распределения во всех вершинах дерева вдоль своего пути. В каждой вершине для каждого гиперпараметра процедура обновления та же, что была описана для одного гиперпараметра: имеющиеся значения гиперпараметров переранжируются по качеству с учётом результата последнего кандидата (этот результат общий для всех вершин вдоль пути), по топ 10-25% оценивается , по остальным — .
В качестве окончательного ответа алгоритм выдаёт набор гиперпараметров (или, как в примере выше, не только гиперпараметры, но даже саму модель), на котором было получено лучшее качество за все итерации. Число итераций алгоритма задаётся пользователем.
За дальнейшими деталями о процедуре обновления дерева для алгоритма TPE можно обратиться к этой статье и к исходному коду алгоритма TPE из библиотеки Hyperopt.
Стоит заметить, что если гиперпараметры не лежат вместе ни в одном пути в дереве, то TPE считает их независимыми. Это — недостаток данного алгоритма, так как некоторые гиперпараметры, находящиеся по смыслу в разных путях в дереве, зависят от друг от друга.
Например, с регуляризацией мы можем тренировать нейросеть большее число эпох, чем без регуляризации, потому что без регуляризации сеть на большом числе эпох может начать переобучаться. В этом конкретном примере можно использовать такой трюк:
1hp.choice('training_parameters', [
2 {
3 'regularization': True,
4 'n_epochs': hp.quniform('n_epochs', 500, 1000, q=1),
5 }, {
6 'regularization': False,
7 'n_epochs': hp.quniform('n_epochs', 20, 300, q=1),
8 },
9])
Но если внутренние зависимости между гиперпараметрами вам неизвестны, то алгоритм не сможет найти их сам.
Критерий позволяет методу TPE балансировать между exploration и exploitation. Семплирование из распределения — это, с одной стороны, exploitation, так как гиперпараметры, семплируемые из него, близки к оптимуму, но это же привносит элемент exploration, так как семплируемые гиперпараметры не равны оптимуму в точности.
Population Based Training (PBT)
Этот метод использует идеи из теории эволюционных стратегий и с самого начала включает в себя параллельные вычисления.
Методы, описанные выше, имеют свои сильные и слабые стороны.
- Grid Search и Random Search:
- отлично параллелизуются;
- не используют результаты предыдущих итераций.
- БО и TPE:
- трудно параллелизуются;
- используют результаты предыдущих итераций, при сходимости результаты лучше, чем у Random Search и Grid Search.
В алгоритме PBT была сделана попытка объединить сильные стороны обеих групп, что проиллюстрировано на картинке ниже:
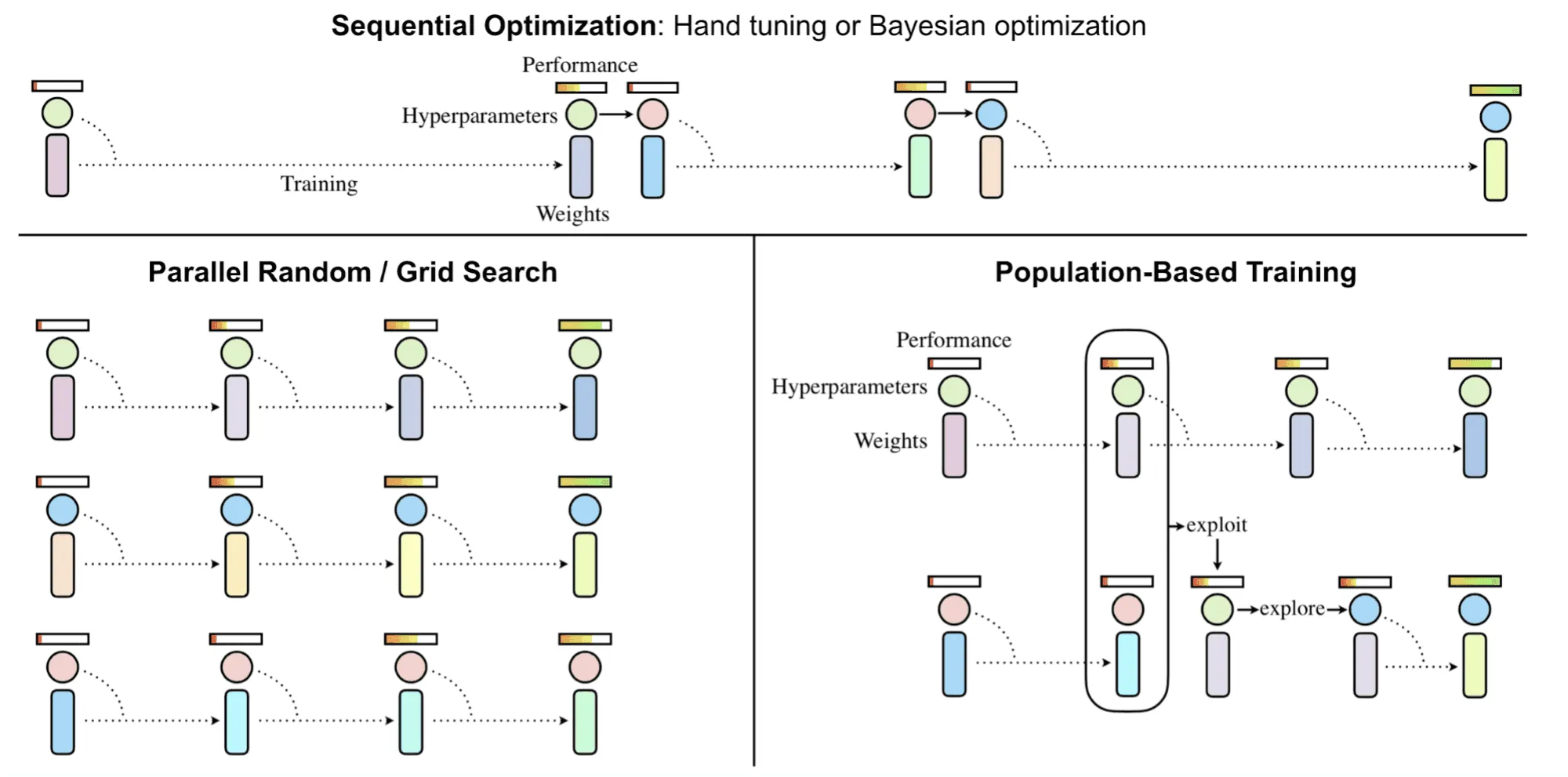
В процессе работы алгоритм обучает не одну модель, а целую популяцию моделей — набор моделей одинакового типа, отличающихся только набором гиперпараметров:
где и — веса и гиперпараметры модели соответственно.
Предполагается также, что модели обучаются как-то итерационно, например градиентным спуском (но могут использоваться и безградиентные методы, такие как эволюционные стратегии). Изначально каждая модель в популяции имеет случайные веса и гиперпараметры. Каждая модель из популяции тренируется параллельно с остальными, и периодически качество каждой модели замеряется независимо от остальных.
Как только какая-то модель считается «созревшей» для обновления (например, прошла достаточное число шагов градиентного спуска или преодолела некоторый порог по качеству), у неё появляется шанс быть обновлённой относительно всей остальной популяции:
- процедура exploit(): если у модели низкое качество относительно популяции, то её веса заменяются на веса модели с более высоким качеством;
- процедура explore(): если веса модели были перезаписаны, шаг explore добавляет случайный шум в параметры модели.
При таком подходе только лучшие пары моделей и гиперпараметров выживут и будут обновляться, что позволяет добиться более высокой утилизации ресурсов.

Стоит отметить, что наиболее оптимальный размер популяции, выявленный авторами в результате экспериментов, — от 20 до 40, что довольно много и не реализуется на обычном ноутбуке.
Красивая гифка с демонстрацией работы алгоритма:
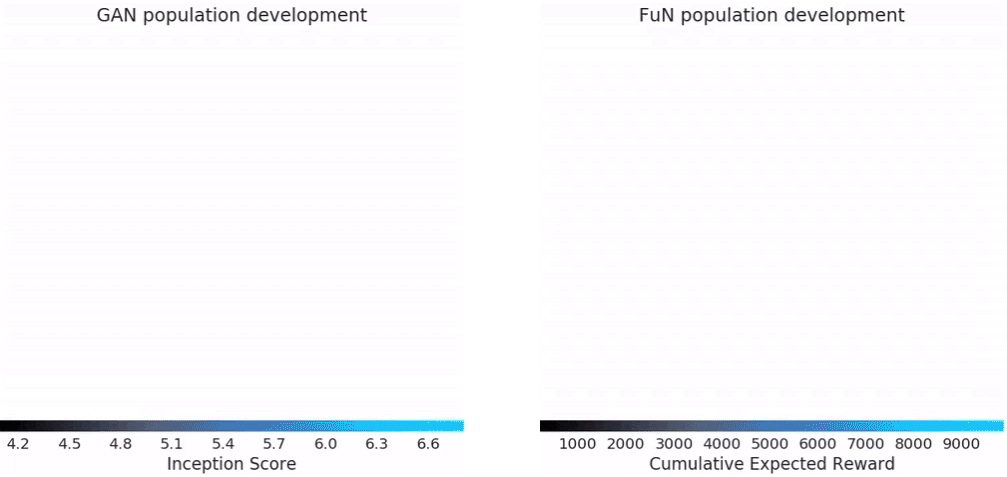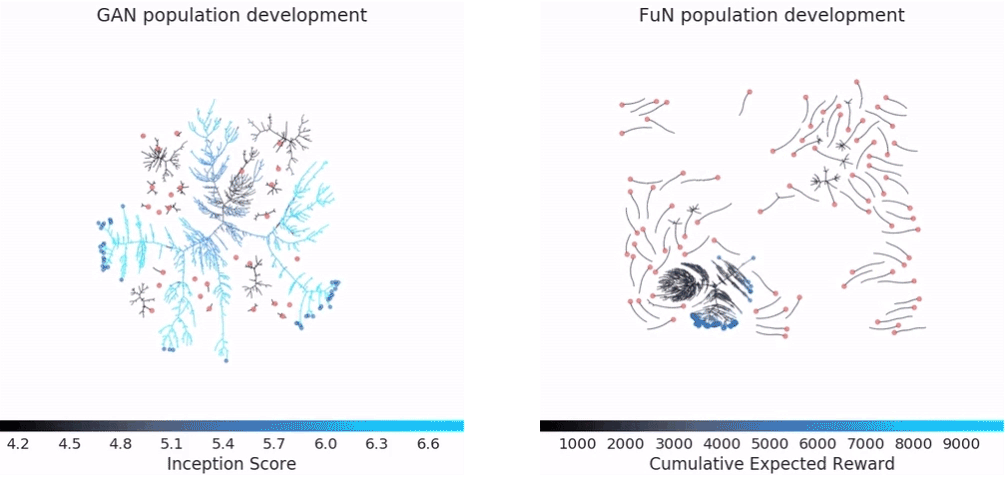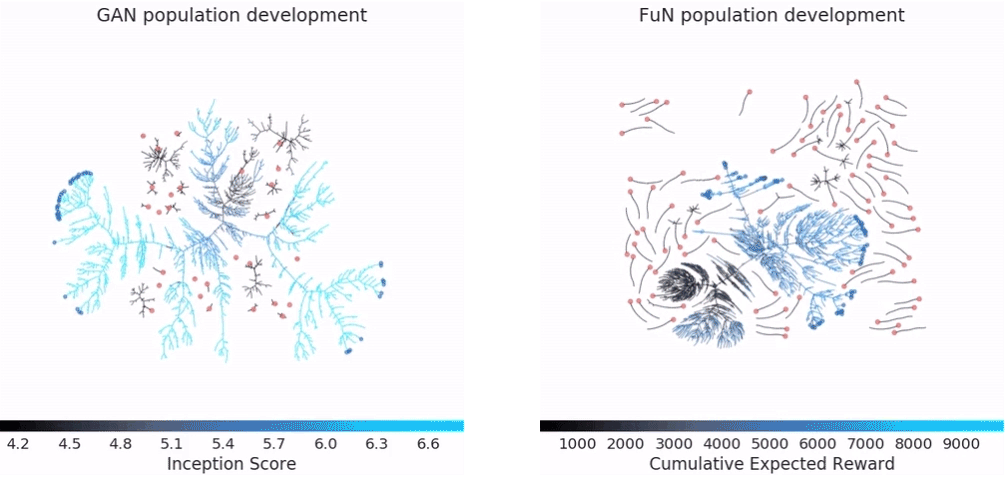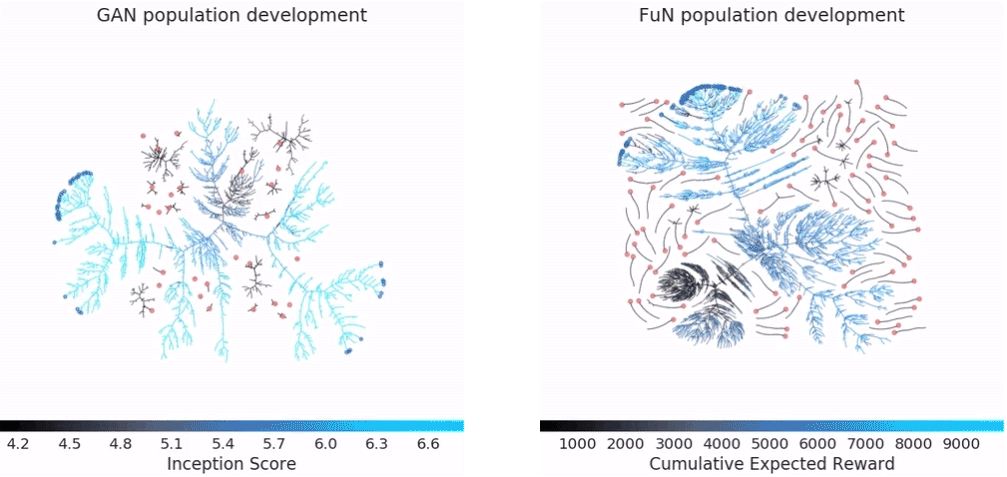
Open-source-библиотеки
Scikit-learn
В библиотеке Scikit-learn есть реализации Grid Search и Random Search, что очень удобно, если вы используете модели из sklearn. Примеры их использования можно найти здесь.
Hyperopt
В библиотеке Hyperopt реализованы три метода оптимизации гиперпараметров:
- Random Search
- TPE
- Adaptive TPE
У них есть небольшой туториал по тому, как начать пользоваться библиотекой. Кроме того, у них есть обёртка над sklearn, позволяющая работать с моделями оттуда: Hyperopt-sklearn.
Optuna
В библиотеке Optuna реализованы те же методы оптимизации, что и в Hyperopt, но по многим параметрам она оказывается удобнее. Хорошее сравнение Optuna и Hyperopt можно найти здесь.
Scikit-Optimize
В библиотеке Scikit-Optimize реализованы алгоритмы байесовской оптимизации и Random Search. Кроме самих методов оптимизации библиотека предоставляет отличный инструментарий для различных визуализаций. Хорошее описание возможностей библиотеки можно найти тут.
Keras Tuner
Библиотека Keras Tuner позволяет подбирать гиперпараметры для нейросеток, написанных на TensorFlow 2.0, и для обычных моделей из Scikit-learn. Доступные методы оптимизации — Random Search и Hyperband. Хороший гайд по использованию данной библиотеки можно найти тут.
Summary
Список описанных методов не исчерпывает все существующие на данный момент методы оптимизации гиперпараметров: остались за кадром такие алгоритмы, как ASHA, Hyperband, BOHB. Хороший сравнительный обзор этих трёх алгоритмов можно найти здесь.
Мы собрали все описанные выше алгоритмы в таблицу, чтобы вам было удобнее сравнивать их между собой. А к некоторым оставили дополнительные комментарии.
Grid Search. Хорошо работает, когда у вас совсем мало гиперпараметров либо вы смогли распараллелить его работу.
- Сильные стороны:
- самый простой для понимания и реализации;
- тривиально распараллеливается.
- Слабые стороны:
- не использует результаты других итераций;
- ограничен в выборе заданной сеткой;
- долго работает, если делает последовательный перебор по сетке. Нет гарантий на необходимое число итераций.
В защиту этого метода хочется сказать, что часто на практике приходится делать перебор гиперпараметров вообще вручную (если один инстанс вашей модели учится недели две и использует много ресурсов) либо по очень небольшой сетке. Так что метод вполне в ходу 😃
Random Search. Метод представляет собой небольшое усложнение над Grid Search, но при этом оказывается намного более эффективным.
- Сильные стороны:
- случайный перебор по сетке позволяет находить оптимальные гиперпараметры более эффективно, чем Grid Search, в частности из-за того, что непрерывные параметры можно задать в виде распределения, а не перечислять значения заранее;
- тривиально распараллеливается;
- допускает усиление за счёт использования квазислучайных распределений при семплировании.
- Слабые стороны:
- не использует результаты других итераций;
- ограничен в выборе заданной сеткой, хотя и в некоторых случаях менее жёстко, чем Grid Search.
Байесовская оптимизация
- Сильные стороны:
- использует результаты предыдущих итераций;
- может моделировать внутренние зависимости между гиперпараметрами (за счёт работы с ними в едином подмножестве , где — число гиперпараметров);
- может расширять заданные изначально границы множества поиска гиперпараметров;
- достигает более высокого качества, чем Random Search, если удалось провести достаточное количество итераций.
- Слабые стороны:
- паралеллится нетривиально;
- в нераспараллеленном случае работает долго, так как для каждой итерации ему приходится заново строить вероятностную модель. В случае если такая модель — гауссовские процессы, сложность получается порядка , где — число гиперпараметров;
- для работы с категориальными гиперпараметрами нужны нетривиальные хаки.
Tree-structured Parzen Estimator
-
Сильные стороны:
- использует результаты предыдущих итераций;
- может работать с зависимостями между гиперпараметрами, в которых один гиперпараметр не будет рассматриваться, если другой не примет какое-то определённое значение (например, число нейронов во втором слое нейросети нужно перебирать, если параметр «число слоёв» имеет значение не менее двух);
- имеет линейную сложность по числу гиперпараметров (в отличие от БО);
- не требует специальных хаков для работы с категориальными признаками, так как каждый гиперпараметр в этом алгоритме имеет своё отдельное одномерное распределение, и не нужно строить сложное совместное распределение всех гиперпараметров (как в БО);
- достигает высоких результатов по качеству, довольно часто используется в соревнованиях.
-
Слабые стороны:
- не может моделировать неявные зависимости между гиперпараметрами (те, которые юзер не задал с помощью дерева);
- хотя сложность и меньше, чем у БО, может работать довольно медленно даже на не очень большом числе гиперпараметров.
Population Based Training
- Сильные стороны:
- параллельный by design;
- может использовать результаты предыдущих итераций.
- Слабые стороны:
- для эффективной работы нужно много воркеров (от 20 до 40), что нетривиально для реализации.
Почитать по теме
- Примеры использования Grid Search от sklearn.
- Примеры использования Random Search от sklearn.
- Хороший блог-пост о гиперпараметрах, в первом разделе которого есть интересные рассуждения про усиление Random Search с помощью квазислучайных распределений.
- Блог-пост от DeepMind про предложенный ими алгоритм Population Based Training.
- Оригинальная статья, где был предложен алгоритм.
- Блог-пост про эволюционные стратегии.
А если вам интересно как следует разобраться в байесовской оптимизации (в частности, рассмотреть больше примеров вероятностных моделей и разных acquisition function), то вот полезный контент:
- Отличный туториал по различным методам оптимизации гиперпараметров, в частности по байесовской оптимизации.
- Статья-обзор, подробно объясняющая математические детали методов байесовской оптимизации и содержащая примеры их применения в ресёрче и индустрии.
- Видеолекция Евгения Бурнаева на летней школе Deep | Bayes.
- Оригинальная статья, в которой были предложены методы TPE и байесовская оптимизация.
- Пример использования skopt (Scikit-Optimize) — нахождение лучших параметров для SVM с помощью байесовской оптимизации.
- Реализация алгоритма байесовской оптимизации и примеры использования библиотечных реализаций.
- Про гауссовские процессы с хорошими визуализациями.
- Более формально про гауссовские процессы, но с хорошими примерами на питоне.
Для дальнейшего изучения метода TPE можно использовать следующие источники:
- Оригинальная статья, в которой были предложены методы TPE и байесовская оптимизация.
- Блог-пост про TPE и остальные методы тюнинга гиперпараметров от NeuPy. Там же можно найти пример применения TPE из Hyperopt.
- Отличное объяснение того, что такое Parzen window density estimation.
- Отличный туториал по различным методам оптимизации гиперпараметров (который уже был упомянут выше в разделе про байесовскую оптимизацию).