

В этом параграфе мы рассмотрим ещё одно семейство моделей машинного обучения — решающие деревья (decision trees).
Решающее дерево предсказывает значение целевой переменной с помощью применения последовательности простых решающих правил (которые называются предикатами). Этот процесс в некотором смысле согласуется с естественным для человека процессом принятия решений.
Хотя обобщающая способность решающих деревьев невысока, их предсказания вычисляются довольно просто, из-за чего решающие деревья часто используют как кирпичики для построения ансамблей — моделей, делающих предсказания на основе агрегации предсказаний других моделей. О них мы поговорим в следующем параграфе.
Пример решающего дерева
Начнём с небольшого примера. На картинке ниже изображено дерево, построенное для задачи классификации на пять классов:
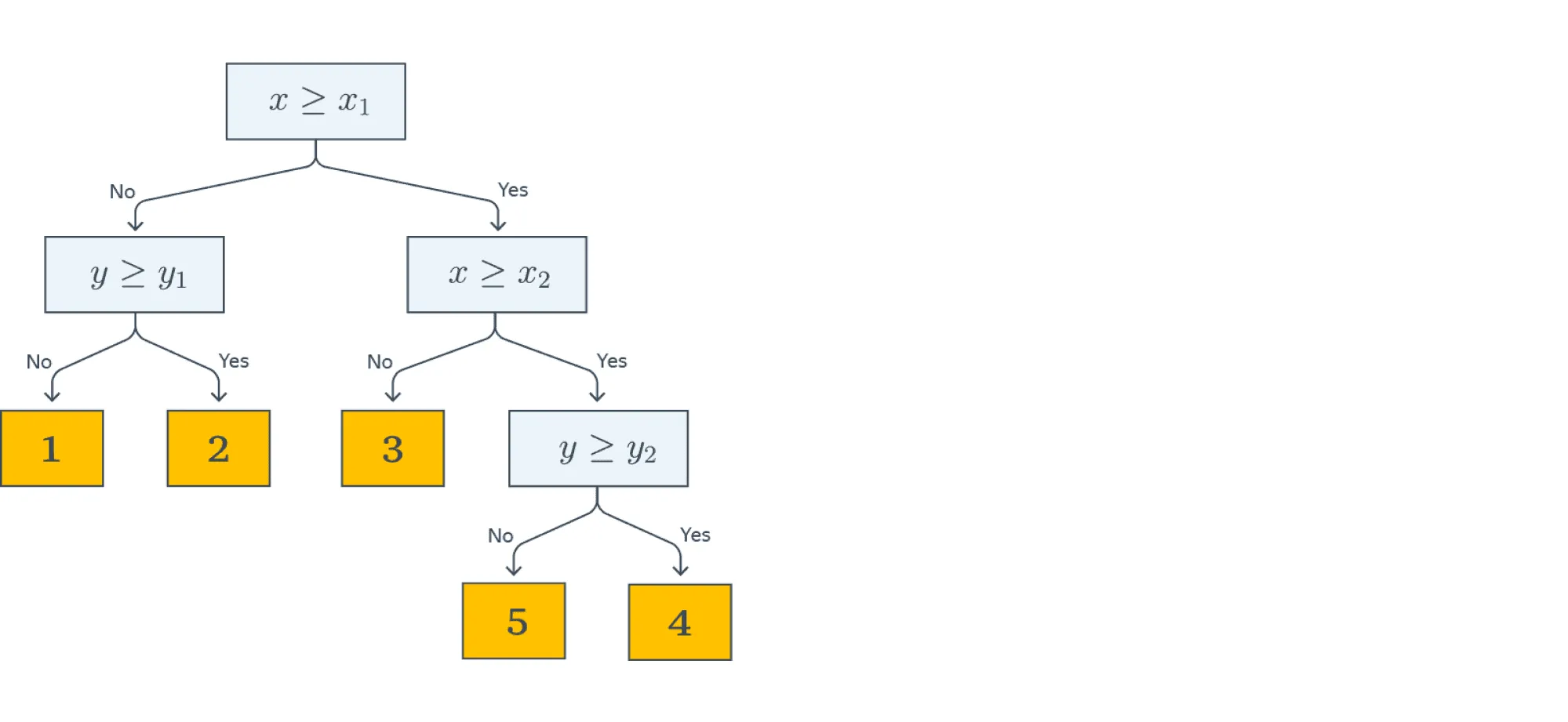
Объекты в этом примере имеют два признака с вещественными значениями: и . Решение о том, к какому классу будет отнесён текущий объект выборки, будет приниматься с помощью прохода от корня дерева к некоторому листу.
В каждом узле этого дерева находится предикат. Если предикат верен для текущего примера из выборки, мы переходим в правого потомка, если нет — в левого. В данном примере все предикаты — это просто взятие порога по значению какого-то признака:
В листьях записаны предсказания (например, метки классов). Как только мы дошли до листа, мы присваиваем объекту ответ, записанный в вершине.
На картинке ниже визуализирован процесс построения решающих поверхностей, порождаемых деревом (правая часть картинки):
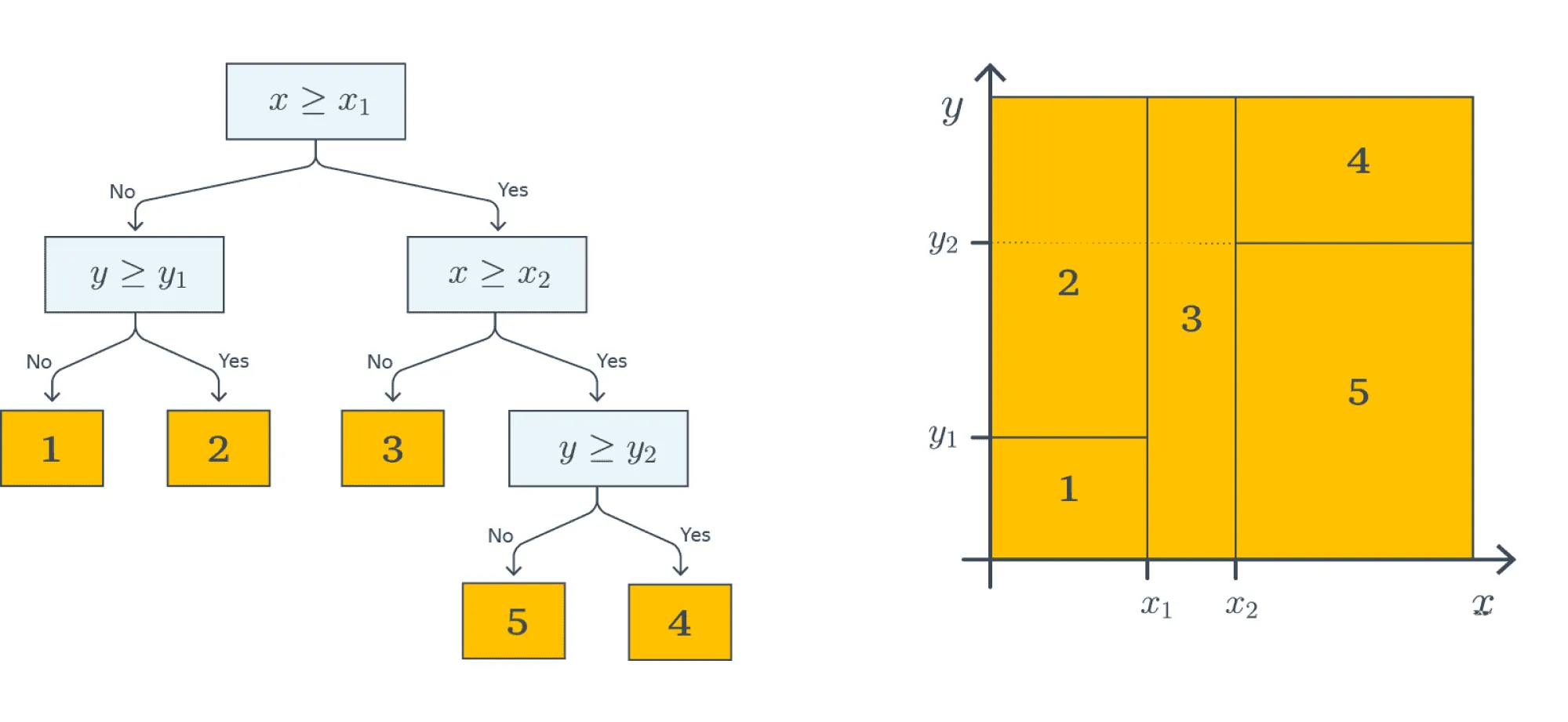
Каждый предикат порождает разделение текущего подмножества пространства признаков на две части. На первом этапе, когда происходило деление по , вся плоскость была поделена на две соответствующие части. На следующем уровне часть плоскости, для которой выполняется , была поделена на две части по значению второго признака — так образовались области 1 и 2. То же самое повторяется для правой части дерева — и так далее до листовых вершин: получится пять областей на плоскости. Теперь любому объекту выборки будет присваиваться один из пяти классов в зависимости от того, в какую из образовавшихся областей он попадает.
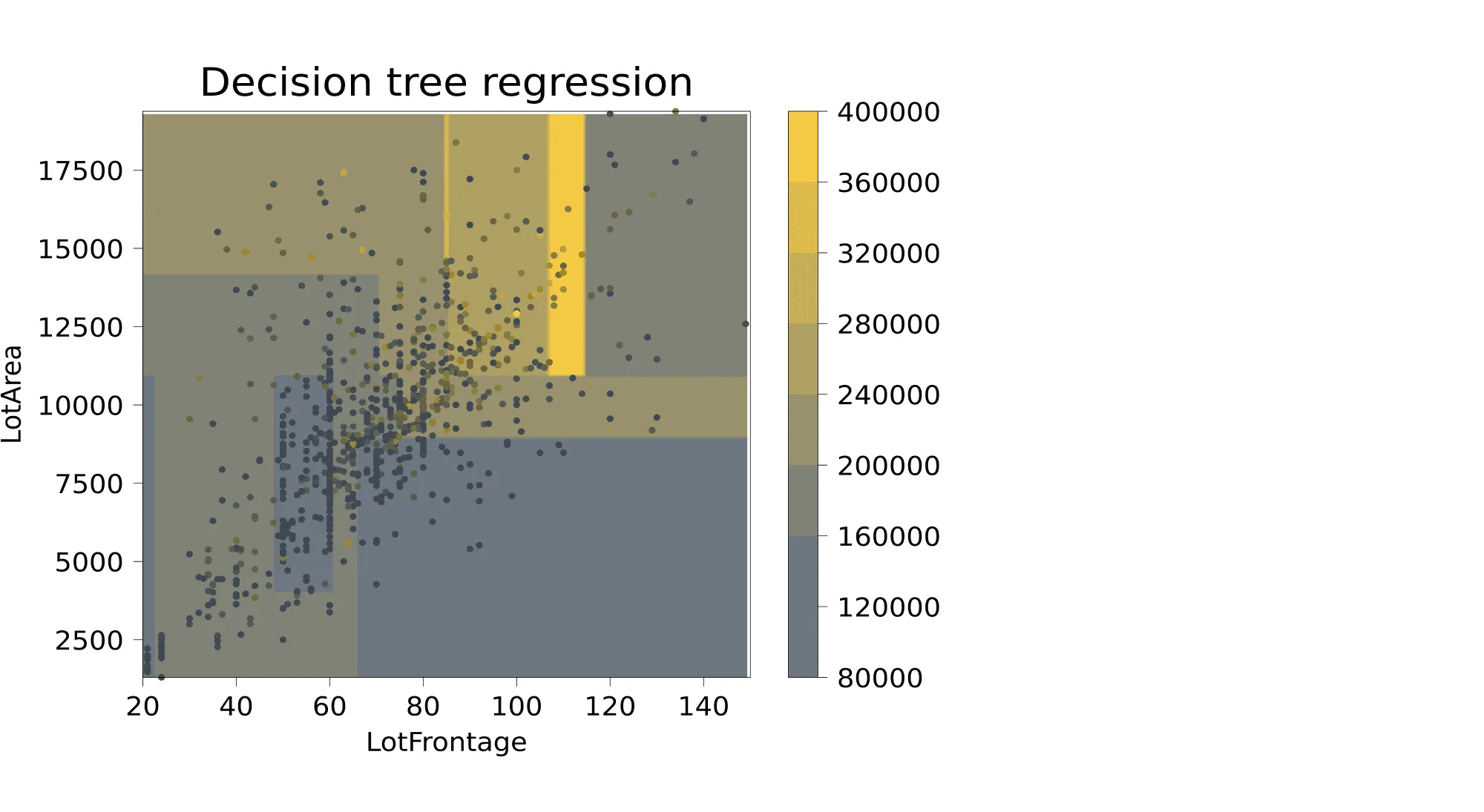
Этот пример хорошо демонстрирует, в частности, то, что дерево осуществляет кусочно-постоянную аппроксимацию целевой зависимости. Ниже приведён пример визуализации решающей поверхности, которая соответствует дереву глубины 4, построенному для объектов данных из Ames Housing Dataset, где из всех признаков, описывающих объекты недвижимости, были выбраны ширина фасада (Lot_Frontage) и площадь (Lot_Area), а предсказать нужно стоимость.
Для более понятной визуализации перед построением дерева из датасета были выкинуты объекты с Lot_Frontage > 150 и с Lot_Area > 20000. Вот что получилось — в каждой из прямоугольных областей предсказывается одна и та же стоимость:
Определение решающего дерева
Разобравшись с приведёнными выше примерами, мы можем дать определение решающего дерева. Пусть задано бинарное дерево, в котором:
- каждой внутренней вершине приписан предикат ;
- каждой листовой вершине приписан прогноз , где — область значений целевой переменной (в случае классификации листу может быть также приписан вектор вероятностей классов).
В ходе предсказания осуществляется проход по этому дереву к некоторому листу. Для каждого объекта выборки движение начинается из корня. В очередной внутренней вершине проход продолжится вправо, если , и влево, если . Проход продолжается до момента, пока не будет достигнут некоторый лист, и ответом алгоритма на объекте считается прогноз , приписанный этому листу.
Вообще, предикат может иметь, произвольную структуру, но на практике чаще используют просто сравнение с порогом по какому-то -му признаку:
При проходе через узел дерева с данным предикатом объекты будут отправлены в правое поддерево, если значение -го признака у них меньше либо равно , и в левое — если больше. В дальнейшем рассказе мы будем по умолчанию использовать именно такие предикаты.
Из структуры дерева решений следует несколько интересных свойств:
- выученная функция — кусочно-постоянная, из-за чего производная равна нулю везде, где задана. Следовательно, о градиентных методах при поиске оптимального решения можно забыть;
- дерево решений (в отличие от, например, линейной модели) не сможет экстраполировать зависимости за границы области значений обучающей выборки;
- дерево решений способно идеально приблизить обучающую выборку и ничего не выучить (то есть такой классификатор будет обладать низкой обобщающей способностью): для этого достаточно построить такое дерево, в каждый лист которого будет попадать только один объект. Следовательно, при обучении нам надо не просто приближать обучающую выборку как можно лучше, но и стремиться оставлять дерево как можно более простым, чтобы результат обладал хорошей обобщающей способностью.
Несколько иллюстраций для закрепления
Сгенерируем для начала небольшой синтетический датасет для задачи классификации и обучим на нём решающее дерево, не ограничивая его потенциальную высоту.
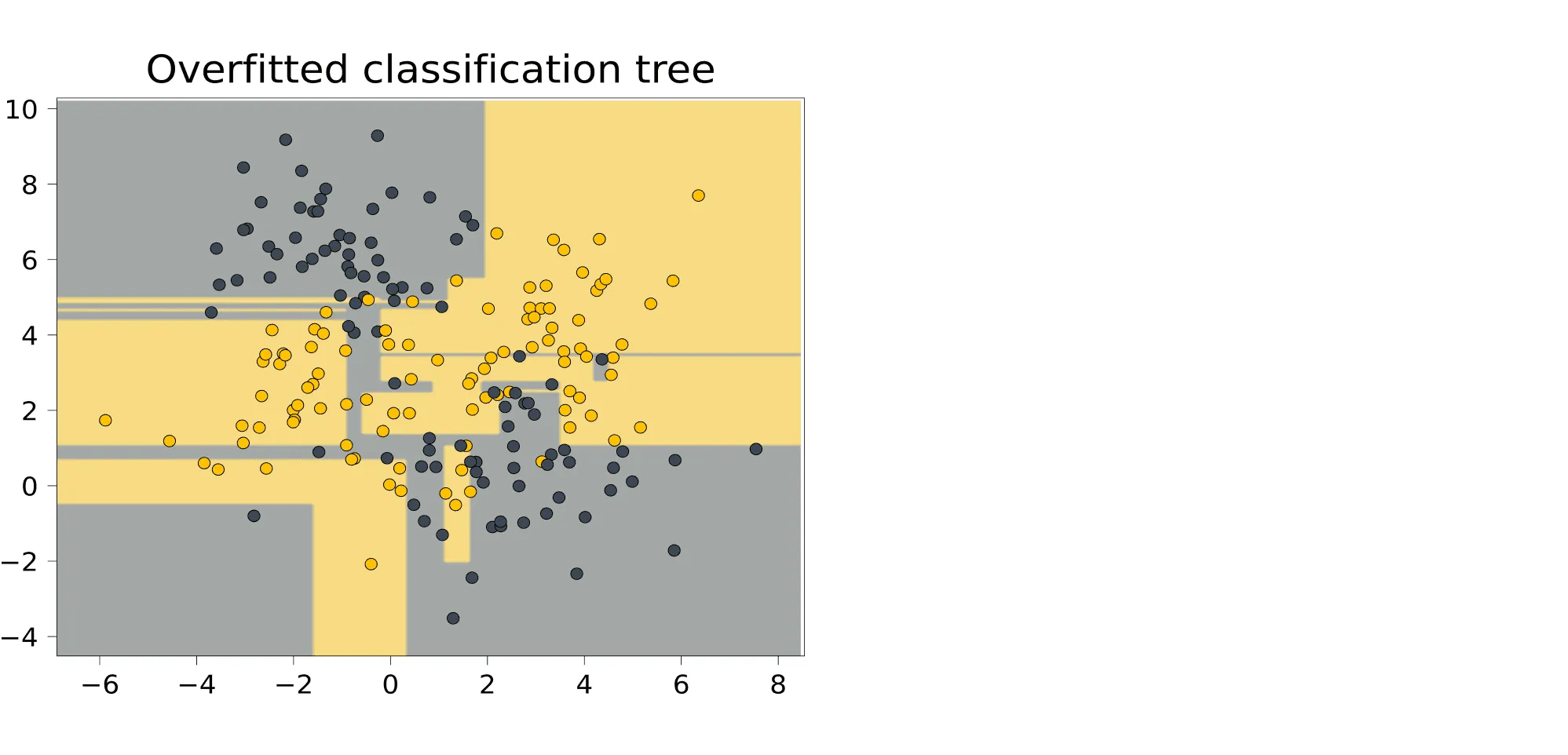
Выученная закономерность очень сложная: иногда она выделяет прямоугольником одну точку. И действительно, как мы увидим дальше, деревья умеют идеально подстраиваться под обучающую выборку. Это чемпионы переобучения. Помешать этому может лишь ограничение на высоту дерева. Вот как будет выглядеть дерево высоты 3, построенное на том же датасете:
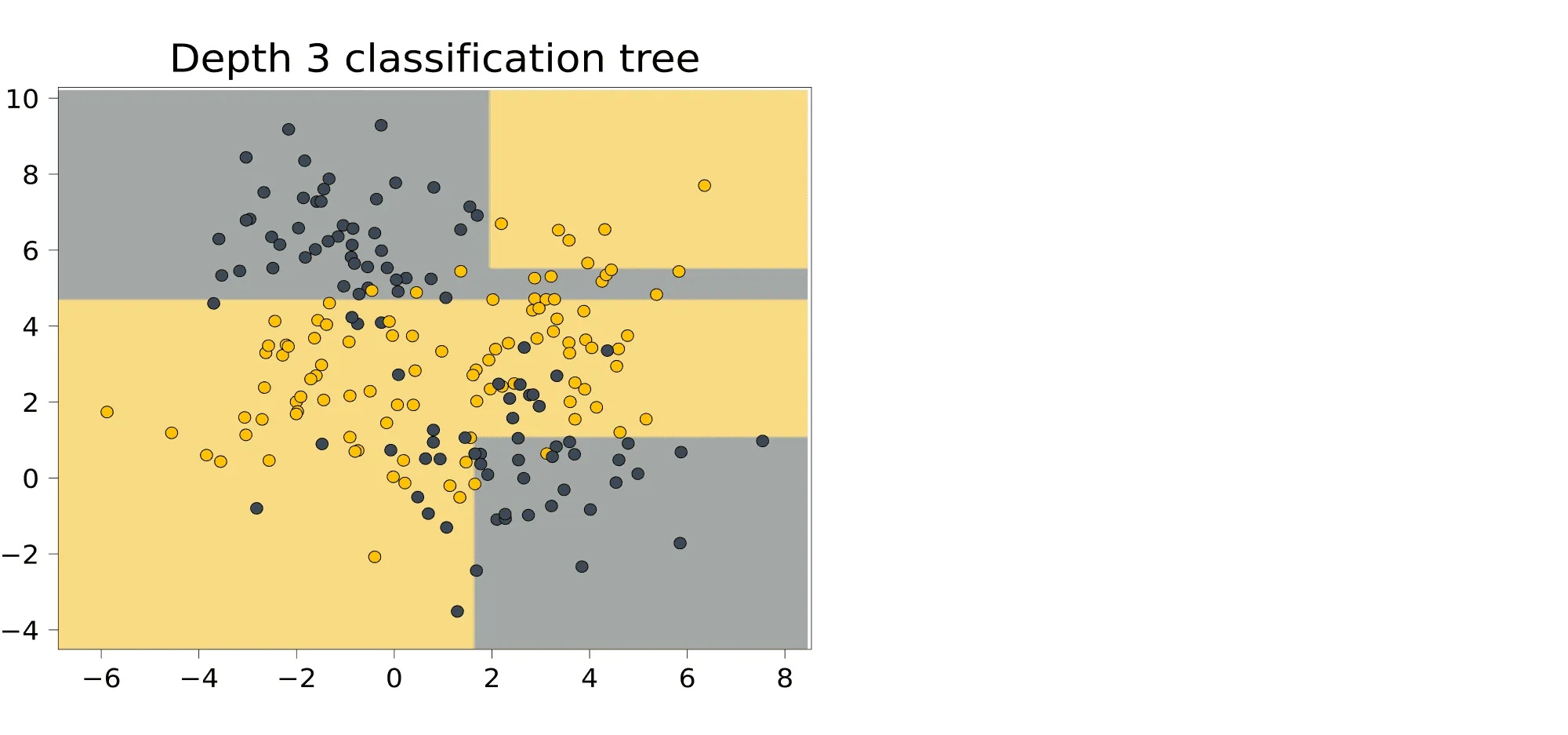
Не всё идеально, но классификатор уже не такой безумный. Теперь обратимся к задаче регрессии. Обучим решающее дерево, не ограничивая его высоту.
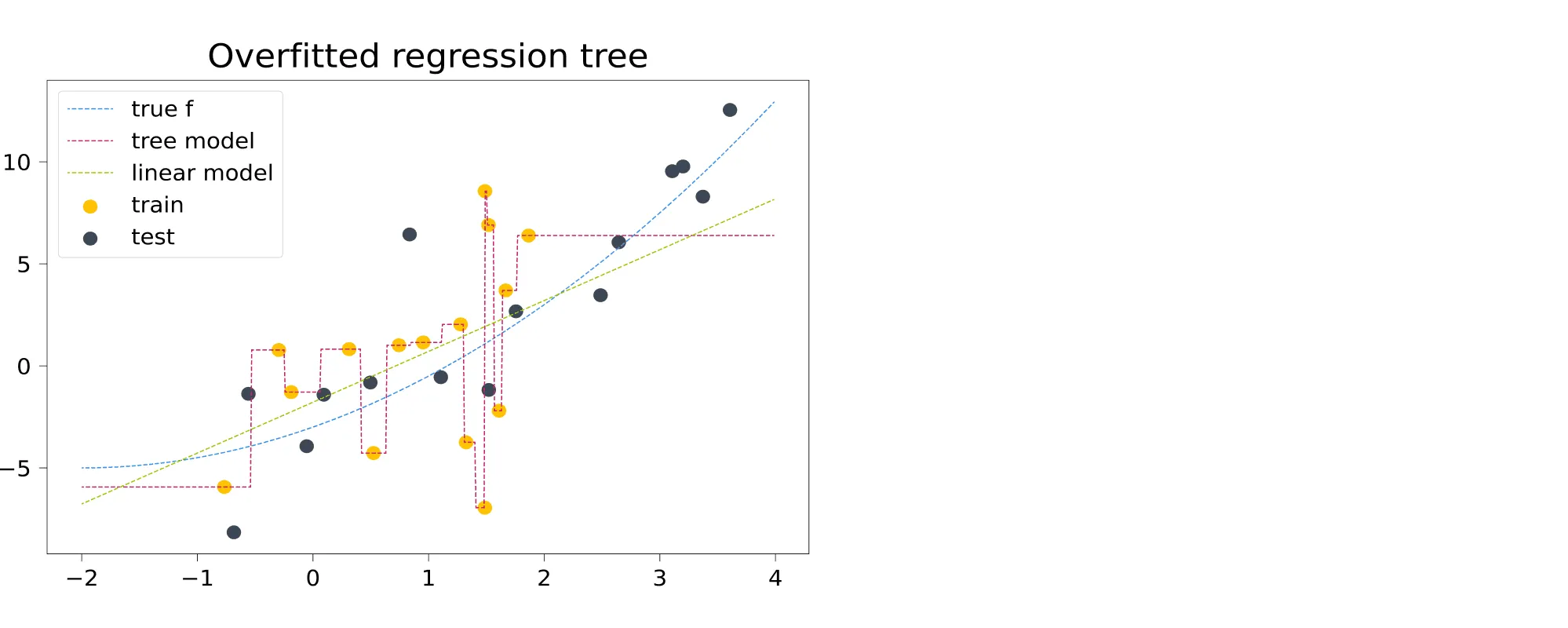
Фиолетовая ступенчатая пунктирная линия — это восстановленная деревом зависимость. На графике она мечется между точками, идеально следуя за обучающей выборкой. Кроме того (и это не лечится ограничением глубины дерева) за пределами обучающей выборки дерево делает константные предсказания. Это и имеют в виду, когда говорят, что древесные модели неспособны к экстраполяции.
Почему построение оптимального решающего дерева — сложная задача?
Пусть, как обычно, у нас задан датасет , где — вектор таргетов, а — матрица признаков, в которой -я строка — это вектор признаков -го объекта выборки. Пусть у нас также задана функция потерь , которую мы бы хотели минимизировать.
Наша задача — построить решающее дерево, наилучшим образом предсказывающее целевую зависимость. Однако, как уже было замечено выше, оптимизировать структуру дерева с помощью градиентного спуска не представляется возможным. Как ещё можно было бы решить эту задачу? Давайте начнём с простого — научимся строить решающие пни, то есть решающие деревья глубины 1.
Как и раньше, мы будем рассматривать только самые простые предикаты:
Ясно, что задачу можно решить полным перебором: существует не более предикатов такого вида. Действительно, индекс (номер признака) пробегает значения от до , а всего значений порога , при которых меняется значение предиката, может быть не более :
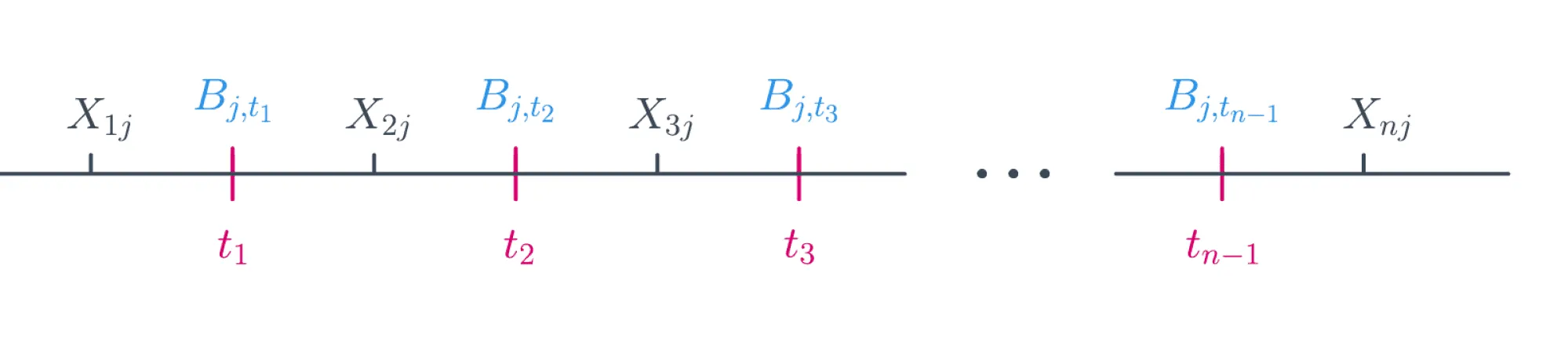
Решение, которое мы ищем, будет иметь вид:
Для каждого из предикатов нам нужно посчитать значение функции потерь на всей выборке, что, в свою очередь, тоже занимает .
Следовательно, полный алгоритм выглядит так:
1min_loss = inf
2optimal_border = None
3
4for j in range(D):
5 for t in X[:, j]: # Можно брать сами значения признаков в качестве порогов
6 loss = calculate_loss(t, j, X, y)
7 if loss < min_loss:
8 min_loss, optimal_border = loss, (j, t)
Сложность алгоритма — . Это не заоблачная сложность, хотя, конечно, не идеальная. Но это была схема возможного алгоритма поиска оптимального дерева высоты 1.
Как обобщить алгоритм для дерева произвольной глубины? Мы можем сделать наш алгоритм поиска решающего пня рекурсивным и в теле цикла вызывать исходную функцию для всех возможных разбиений. Как мы упоминали выше, так можно построить дерево, идеально запоминающее всю выборку, однако на тестовых данных такой алгоритм вряд ли покажет высокое качество.
Можно поставить другую задачу: построить оптимальное с точки зрения качества на обучающей выборке дерево минимальной глубины (чтобы снизить переобучение). Проблема в том, что поиск такого дерева — NP-полная задача, то есть человечеству пока неизвестны способы решить её за полиномиальное время. Как быть?
Идеального ответа на этот вопрос нет, но до некоторой степени ситуацию можно улучшить двумя не исключающими друг друга способами:
- Разрешить себе искать не оптимальное решение, а просто достаточно хорошее. Начать можно с того, чтобы строить дерево с помощью жадного алгоритма, то есть не искать всю структуру сразу, а строить дерево этаж за этажом. Тогда в каждой внутренней вершине дерева будет решаться задача, схожая с задачей построения решающего пня. Для того чтобы этот подход хоть как-то работал, его придётся прокачать внушительным набором эвристик.
- Заняться оптимизацией с точки зрения computer science — наивную версию алгоритма (перебор наборов возможных предикатов и порогов) можно ускорить и асимптотически, и в константу раз.
Эти две идеи мы и будем обсуждать в дальнейшем. Сначала попытаемся подробно разобраться с первой — как использовать жадный алгоритм.
Жадный алгоритм построения решающего дерева
Пусть — исходное множество объектов обучающей выборки, а — множество объектов, попавших в текущий лист (в самом начале ). Тогда жадный алгоритм можно верхнеуровнево описать следующим образом:
- Создаём вершину .
- Если выполнен критерий остановки , то останавливаемся, объявляем эту вершину листом и ставим ей в соответствие ответ , после чего возвращаем её.
- Иначе: находим предикат (иногда ещё говорят сплит) , который определит наилучшее разбиение текущего множества объектов на две подвыборки и , максимизируя критерий ветвления .
- Для и рекурсивно повторим процедуру.
Данный алгоритм содержит в себе несколько вспомогательных функций, которые надо выбрать так, чтобы итоговое дерево было способно минимизировать :
, вычисляющая ответ для листа по попавшим в него объектам из обучающей выборки, может быть, например:
- в случае задачи классификации — меткой самого частого класса или оценкой дискретного распределения вероятностей классов для объектов, попавших в этот лист;
- в случае задачи регрессии — средним, медианой или другой статистикой;
- простой моделью. К примеру, листы в дереве, задающем регрессию, могут быть линейными функциями или синусоидами, обученными на данных, попавших в лист. Впрочем, везде ниже мы будем предполагать, что в каждом листе просто предсказывается константа.
Критерий остановки — функция, которая решает, нужно ли продолжать ветвление или пора остановиться. Это может быть какое-то тривиальное правило: например, остановиться только в тот момент, когда объекты в листе получились достаточно однородными и/или их не слишком много. Более детально мы поговорим о критериях остановки в параграфе про регуляризацию деревьев.
Критерий ветвления — пожалуй, самая интересная компонента алгоритма. Это функция, измеряющая, насколько хорош предлагаемый сплит. Чаще всего эта функция оценивает, насколько улучшится некоторая финальная метрика качества дерева в случае, если получившиеся два листа будут терминальными, по сравнению с ситуацией, когда сама исходная вершина — это лист. Выбирается такой сплит, который даёт наиболее существенное улучшение.
Впрочем, есть и другие подходы. При этом строгой теории, которая бы связывала оптимальность выбора разных вариантов этих функций и разных метрик классификации и регрессии, в общем случае не существует. Однако есть набор интуитивных и хорошо себя зарекомендовавших соображений, с которыми мы вас сейчас познакомим.
Критерии ветвления: общая идея
Давайте теперь по очереди посмотрим на популярные постановки задач ML и под каждую подберём свой критерий.
Ответы дерева будем кодировать так: — для ответов регрессии и меток класса. Для случаев, когда надо ответить дискретным распределением на классах, будет вектором вероятностей:
Предположим также, что задана некоторая функция потерь . О том, что это может быть за функция, мы поговорим ниже.
В момент, когда мы ищем оптимальный сплит , мы можем вычислить для объектов из тот константный таргет , которые предсказало бы дерево, будь текущая вершина терминальной, и связанное с ними значение исходного функционала качества . А именно — константа должна минимизировать среднее значение функции потерь:
Оптимальное значение этой величины
обычно называют информативностью, или impurity. Чем она ниже, тем лучше объекты в листе можно приблизить константным значением.
Похожим образом можно определить информативность решающего пня. Пусть, как и выше, — множество объектов, попавших в левую вершину, а — в правую; пусть также и — константы, которые предсказываются в этих вершинах. Тогда функция потерь для всего пня в целом будет равна
Вопрос на подумать. Как информативность решающего пня связана с информативностью его двух листьев?
Ответ (не открывайте сразу; сначала подумайте сами!)
Преобразуем выражение:
Эта сумма будет минимальна при оптимальном выборе констант и , и информативность пня будет равна
Теперь для того чтобы принять решение о разделении, мы можем сравнить значение информативности для исходного листа и для получившегося после разделения решающего пня.
Разность информативности исходной вершины и решающего пня равна
Для симметрии её принято умножить на ; тогда получится следующий критерий ветвления:
Получившаяся величина неотрицательна: ведь, разделив объекты на две кучки и подобрав ответ для каждой, мы точно не сделаем хуже. Кроме того, она тем больше, чем лучше предлагаемый сплит.
Теперь посмотрим, какими будут критерии ветвления для типичных задач.
Информативность в задаче регрессии: MSE
Посмотрим на простой пример — регрессию с минимизацией среднеквадратичной ошибки:
Информативность листа будет выглядеть следующим образом:
Как мы уже знаем, оптимальным предсказанием константного классификатора для задачи минимизации MSE является среднее значение, то есть
Подставив в формулу информативности сплита, получаем:
То есть при жадной минимизации MSE информативность — это оценка дисперсии таргетов для объектов, попавших в лист. Получается очень стройная картинка: оценка значения в каждом листе — это среднее, а выбирать сплиты надо так, чтобы сумма дисперсий в листьях была как можно меньше.
Информативность в задаче регрессии: MAE
Случай средней абсолютной ошибки так же прост: в листе надо предсказывать медиану, ведь именно медиана таргетов для обучающих примеров минимизирует MAE констатного предсказателя (мы это обсуждали в параграфе про линейные модели).
В качестве информативности выступает абсолютное отклонение от медианы:
Критерий информативности в задаче классификации: misclassification error
Пусть в нашей задаче классов, а — доля объектов класса в текущей вершине :
Допустим, мы заботимся о доле верно угаданных классов, то есть функция потерь — это индикатор ошибки:
Пусть также предсказание модели в листе — один какой-то класс. Информативность для такой функции потерь выглядит так:
Ясно, что оптимальным предсказанием в листе будет наиболее частотный класс , а выражение для информативности упростится следующим образом:
Информативность в задаче классификации: энтропия
Если же мы собрались предсказывать вероятностное распределение классов , то к этому вопросу можно подойти так же, как мы поступали при выводе логистической регрессии: через максимизацию логарифма правдоподобия (= минимизацию минус логарифма) распределения Бернулли. А именно, пусть в вершине дерева предсказывается фиксированное распределение (не зависящее от ), тогда правдоподобие имеет вид
откуда
То, что оценка вероятностей в листе , минимизирующая , должна быть равна , то есть доле попавших в лист объектов этого класса, до некоторой степени очевидно, но это можно вывести и строго.
Доказательство для любопытных
Из-за наличия условия на нам придётся минимизировать лагранжиан
Как обычно, возьмём частную производную и решим уравнение:
откуда выражаем . Суммируя эти равенства, получим:
откуда , а значит, .
Подставляя вектор в выражение выше, мы в качестве информативности получим энтропию распределения классов:
Немного подробнее об энтропии
Величина
называется информационной энтропией Шеннона и измеряет непредсказуемость реализации случайной величины. В оригинальном определении, правда, речь шла не о значениях случайной величины, а о символах (первичного) алфавита, так как Шеннон придумал эту величину, занимаясь вопросами кодирования строк. Для данной задачи энтропия имеет вполне практический смысл — среднее количество битов, которое необходимо для кодирования одного символа сообщения при заданной частоте символов алфавита.
Так как , энтропия неотрицательна. Если случайная величина принимает только одно значение, то она абсолютно предсказуема и её энтропия равна
Наибольшего значения энтропия достигает для равномерно распределённой случайной величины — и это отражает тот факт, что среди всех величин с данной областью значений она наиболее «непредсказуема». Для равномерно распределённой на множестве случайной величины значение энтропии будет равно:
На следующем графике приведены три дискретных распределения на множестве с их энтропиями. Как и указано выше, максимальную энтропию будет иметь равномерное распределение; у двух других проявляются пики разной степени остроты — и тем самым реализации этих величин обладают меньшей неопределённостью: мы можем с большей уверенностью говорить, что будет сгенерировано.
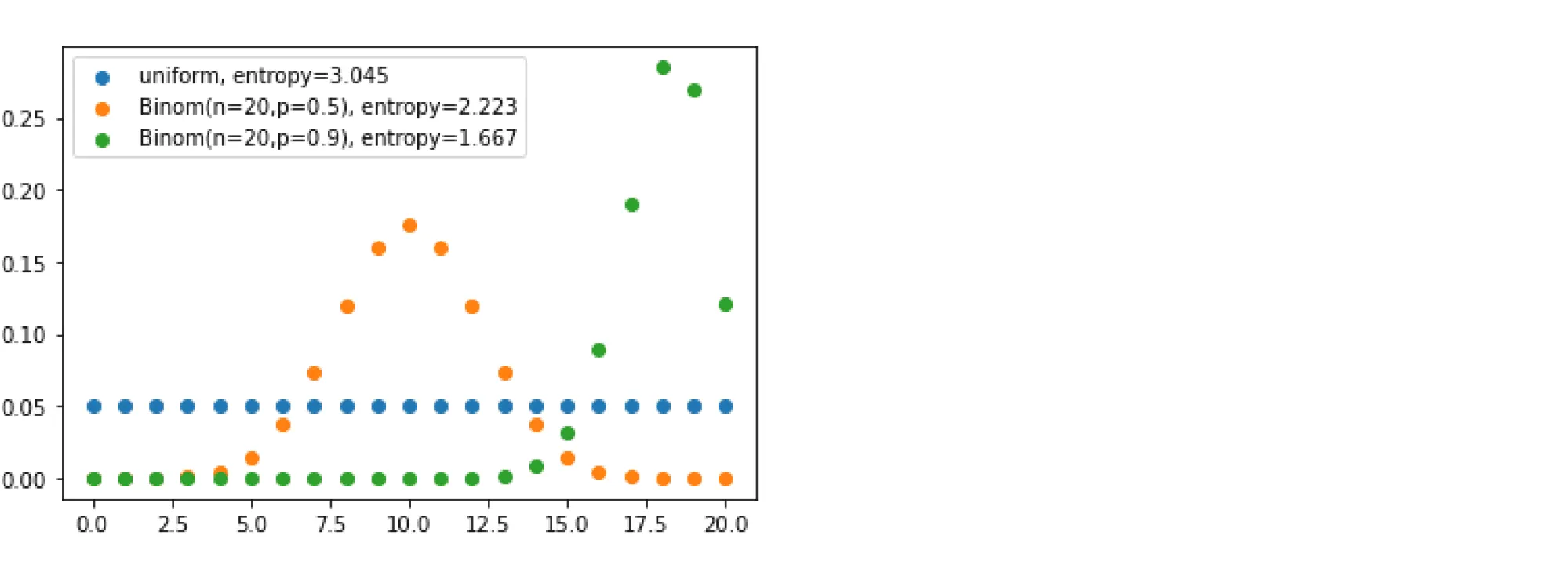
Разберём на примере игрушечной задачи классификации то, как энтропия может выступать в роли impurity. Рассмотрим три разбиения синтетического датасета и посмотрим, какие значения энтропии они дают. В подписях указано, каким становится соотношение классов в половинках.
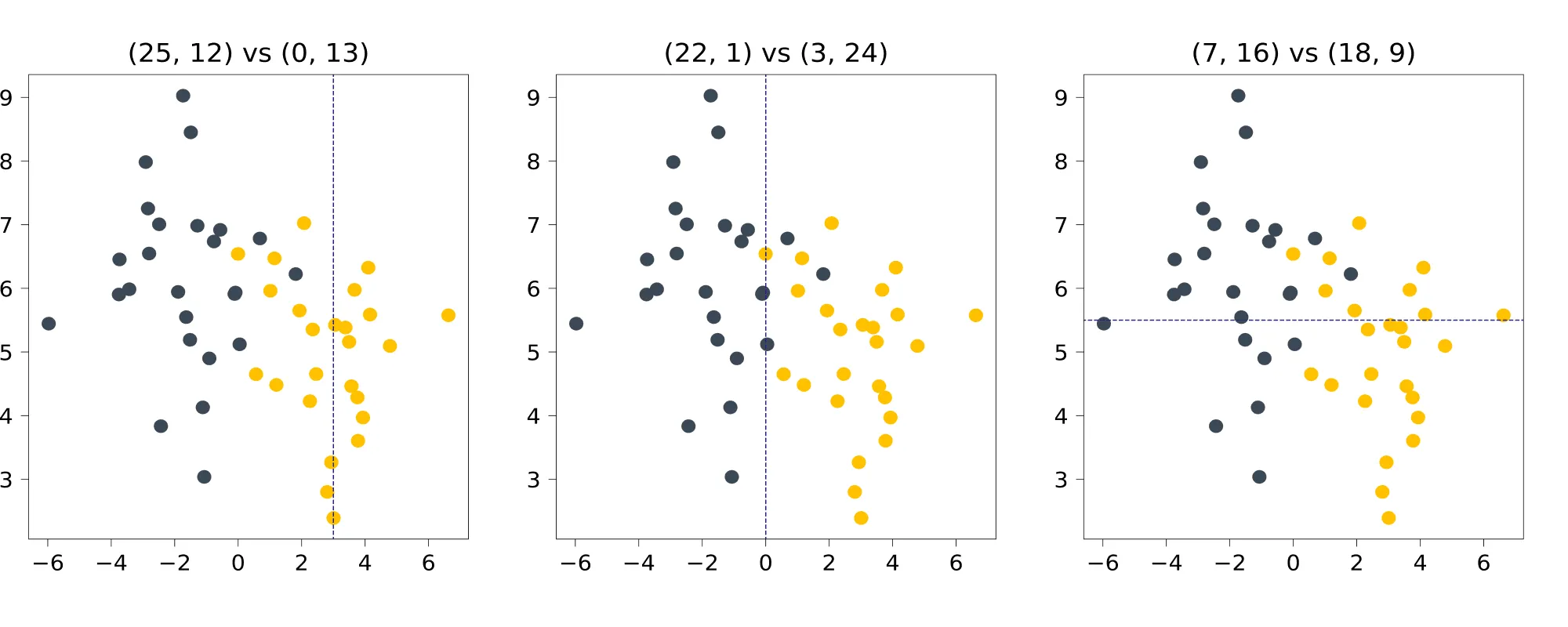
В изначальном датасете по 25 точек каждого класса; энтропия состояния равна
Для первого разбиения, по в левую часть попадают точек класса 0 и точек класса 1, а в правую — точек класса 0 и точек класса 1. Энтропия левой группы равна
Энтропия правой группы, строго говоря, не определена (под логарифмом ноль), но если заменить несуществующее значение на , то получится
Что, в принципе, логично: с вероятностью 1 выпадает единица, мы всегда уверены в результате, и энтропия у такого, вырожденного распределения тоже минимальная, равная нулю.
Как можно заметить, энтропия в обеих группах уменьшилась по сравнению с изначальной. Получается, что, разделив шарики по значению координаты, равному 3, мы уменьшили общую неопределённость системы. Но какое из разбиений даёт самое радикальное уменьшение? После несложных вычислений, мы получаем для нарисованных выше разбиений:
Ожидаемо, не так ли? Второе разбиение практически идеально разделяет классы, делая из исходного, почти равномерного распределения, два почти вырожденных. При остальных разбиениях в каждой из половинок неопределённость тоже падает, но не так сильно.
Кстати, Шеннон изначально собирался назвать информационную энтропию или «информацией», или «неопределённостью», но в итоге выбрал название «энтропия», потому что концепция со схожим смыслом в статистической механике уже была названа энтропией. Употребление термина из другой научной области выглядело убедительным преимуществом при ведении научных споров.
Информативность в задаче классификации: критерий Джини
Пусть предсказание модели — это распределение вероятностей классов . Вместо логарифма правдоподобия в качестве критерия можно выбрать, например, метрику Бриера (за которой стоит всего лишь идея посчитать MSE от вероятностей). Тогда информативность получится равной
Можно показать, что оптимальное значение этой метрики, как и в случае энтропии, достигается на векторе , состоящем из выборочных оценок частот классов , . Если подставить в выражение выше и упростить его, получится критерий Джини:
Критерий Джини допускает и следующую интерпретацию: равно математическому ожиданию числа неправильно классифицированных объектов в случае, если мы будем приписывать им случайные метки из дискретного распределения, заданного вероятностями .
Неоптимальность полученных критериев
Казалось бы, мы вывели критерии информативности для всех популярных задач, и они довольно логично следуют из их постановок, но получилось ли у нас обмануть NP-полноту и научиться строить оптимальные деревья легко и быстро?
Конечно, нет. Простейший пример — решение задачи XOR с помощью жадного алгоритма и любого критерия, который мы построили выше:
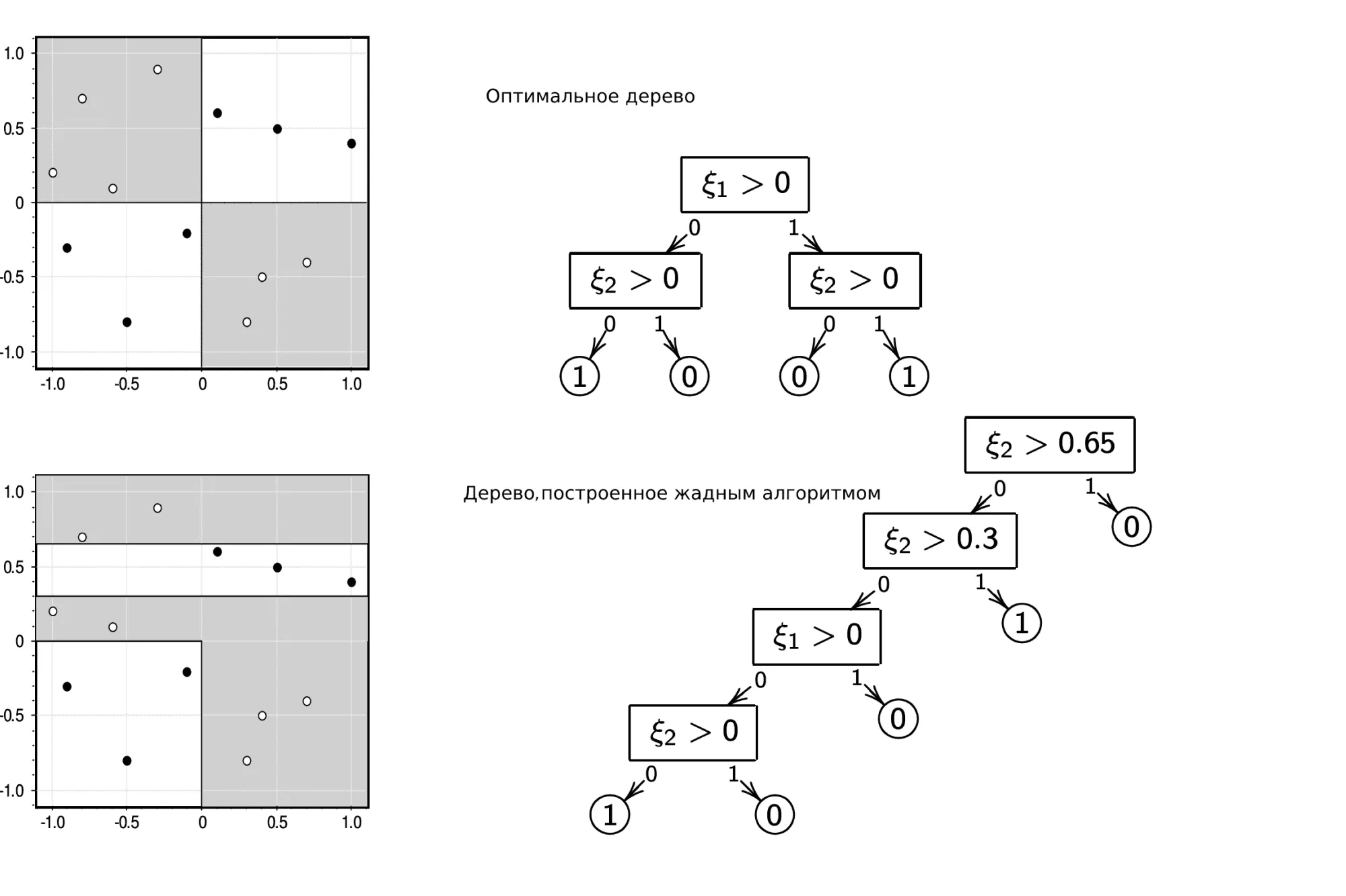
Вне зависимости от того, что вы оптимизируете, жадный алгоритм не даст оптимального решения задачи XOR. Но этим примером проблемы не исчерпываются. Скажем, бывают ситуации, когда оптимальное с точки зрения выбранной метрики дерево вы получите с критерием ветвления, построенным по другой метрике (например, MSE-критерий для MAE-задачи или Джини для misclassification error).
Особенности данных
Категориальные признаки
На первый взгляд, деревья прекрасно могут работать с категориальными переменными. А именно, если признак принимает значения из множества , то при очередном разбиении мы можем рассматривать по этому признаку произвольные сплиты вида (предикат будет иметь вид ). Это очень логично и естественно, но проблема в том, что при больших у нас будет сплитов, и перебирать их будет слишком долго. Было бы здорово уметь каким-то образом упорядочивать значения , чтобы работать с ними так же, как с обычными числами: разделяя на значения, «не превосходящие» и «большие» определённого порога.
Оказывается, что для некоторых задач такое упорядочение можно построить вполне естественным образом.
Так, для задачи бинарной классификации значения можно упорядочить по неубыванию доли объектов класса 1 с , после чего работать с ними, как со значениями вещественного признака. Показано, что в случае, если мы выбираем таким образом сплит, оптимальный с точки зрения энтропийного критерия или критерия Джини, то он будет оптимальным среди всех сплитов.
Для задачи регрессии с функцией потерь MSE значения можно упорядочивать по среднему значению таргета на подмножестве . Полученный таким образом сплит тоже будет оптимальным.
Работа с пропусками
Одна из приятных особенностей деревьев — это способность обрабатывать пропуски в данных. Разберёмся, что при этом происходит на этапе обучения и на этапе применения дерева.
Пусть у нас есть некоторый признак , значение которого пропущено у некоторых объектов. Как обычно, обозначим через множество объектов, пришедших в рассматриваемую вершину, а через — подмножество , состоящее из объектов с пропущенным значением . В момент выбора сплитов по этому признаку мы будем просто игнорировать объекты из , а когда сплит выбран, мы отправим их в оба поддерева. При этом логично присвоить им веса: для левого поддерева и для правого. Веса будут учитываться как коэффициенты при в формуле информативности.
Вопрос на подумать. Во всех критериях ветвления участвуют мощности множеств , и . Нужно ли уменьшение размера выборки учитывать в формулах для информативности? Если нужно, то как?
Ответ (не открывайте сразу; сначала подумайте сами!)
Чтобы ответить на этот вопрос, вспомним, как работают критерии ветвления. Их суть в сравнении информативности для исходной вершины с информативностью для решающего пня, порождённого рассматриваемым сплитом. Величина никак не меняется, надо понять, что будет с пнём. Для него можно посчитать информативность так, словно объектов с пропущенными значениями нет:
Тогда в критерии ветвления нужно поменять коэффициенты, иначе мы не будем адекватным образом сравнивать такой сплит со сплитами по другим признакам:
Если же мы предполагаем, что объекты из отправляются в новые листья с весами, как описано выше, то формула оказывается другой, и коэффициенты можно не менять:
Теперь рассмотрим этап применения дерева. Допустим, в вершину, где сплит идёт по -му признаку, пришёл объект с пропущенным значением этого признака. Предлагается отправить его в каждую из дальнейших веток и получить по ним предсказания и . Эти предсказания мы усредним с весами и (которые мы запомнили в ходе обучения):
Для задачи регрессии это сразу даст нам таргет, а в задаче бинарной классификации — оценку вероятности класса 1.
Замечание. Если речь идёт о категориальном признаке, может оказаться хорошей идеей ввести дополнительное значение «пропущено» для категориального признака и дальше работать с пропусками, как с обычным значением. Особенно это актуально в ситуациях, когда пропуски имеют системный характер и их наличие несёт в себе определённую информацию.
Методы регуляризации решающих деревьев
Мы уже упоминали выше, что деревья легко переобучаются и процесс ветвления надо в какой-то момент останавливать.
Для этого есть разные критерии, обычно используются все сразу:
- ограничение по максимальной глубине дерева;
- ограничение на минимальное количество объектов в листе;
- ограничение на максимальное количество листьев в дереве;
- требование, чтобы функционал качества при делении текущей подвыборки на две улучшался не менее чем на процентов.
Делать это можно на разных этапах работы алгоритма, что не меняет сути, но имеет разные устоявшиеся названия:
- можно проверять критерии прямо во время построения дерева, такой способ называется pre-pruning или early stopping;
- а можно построить дерево жадно без ограничений, а затем провести стрижку (pruning), то есть удалить некоторые вершины из дерева так, чтобы итоговое качество упало не сильно, но дерево начало подходить под условия регуляризации. При этом качество стоит измерять на отдельной, отложенной выборке.
Алгоритмические трюки
Теперь временно снимем шапочку ML-аналитика, наденем шапочку разработчика и специалиста по computer science и посмотрим, как можно сделать полученный алгоритм более вычислительно эффективным.
В базовом алгоритме мы в каждой вершине дерева для всех возможных значений сплитов вычисляем информативность. Если в вершину пришло объектов, то мы рассматриваем сплитов и для каждого тратим операций на подсчёт информативности. Отметим, что в разных вершинах, находящихся в нашем дереве на одном уровне, оказываются разные объекты, то есть сумма этих по всем вершинам заданного уровня не превосходит , а значит, выбор сплитов во всех вершинах уровня потребует операций.
Таким образом, общая сложность построения дерева — (где — высота дерева), и доминирует в ней перебор всех возможных предикатов на каждом уровне построения дерева. Посмотрим, что с этим можно сделать.
Динамическое программирование
Постараемся оптимизировать процесс выбора сплита в одной конкретной вершине.
Вместо того чтобы рассматривать все возможных сплитов, для каждого тратя на вычисление информативности, можно использовать одномерную динамику. Для этого заметим, что если отсортировать объекты по какому-то признаку, то, проходя по отсортированному массиву, можно одновременно и перебирать все значения предикатов, и поддерживать все необходимые статистики для пересчёта значений информативности за для каждого следующего варианта сплита (против изначальных ).
Давайте разберём, как это работает, на примере построения дерева для MSE. Чтобы оценить информативность для листа, нам нужно знать несколько вещей:
- дисперсию и среднее значение таргета в текущем листе;
- дисперсию и среднее значение таргета в обоих потомках для каждого потенциального значения сплита.
Дисперсию и среднее текущего листа легко посчитать за .
С дисперсией и средним для всех значений сплитов чуть сложнее, но помогут следующие оценки математического ожидания и дисперсии:
Следовательно, нам достаточно для каждого потенциального значения сплита знать количество элементов в правом и левом поддеревьях, их сумму и сумму их квадратов. Впрочем, всё это необходимо знать только для одной из половинок сплита, а для второй это можно получить, вычитая значения для первой из полных сумм. Это можно сделать за один проход по массиву, просто накапливая значения частичных сумм.
Если в вершину дерева пришло объектов, сложность построения одного сплита складывается из сортировок каждая по и одного линейного прохода с динамикой, всего , что лучше исходного . Итоговая сложность алгоритма построения дерева — (где – высота дерева) против в наивной его версии.
Какие именно статистики накапливать (средние, медианы, частоты), зависит от критерия, который вы используете.
Гистограммный метод
Если бы мощность множества значений признаков была ограничена какой-то разумной константой , то сортировку в предыдущем способе можно было бы заменить сортировкой подсчётом и за счёт этого существенно ускорить алгоритм: ведь сложность такой сортировки — .
Чтобы провернуть это с любой выборкой, мы можем искусственно дискретизировать значения всех признаков. Это приведёт к локально менее оптимальным значениям сплитов, но, учитывая, что наш алгоритм и без этого был весьма приблизительным, это не ухудшит ничего драматически, а вот ускорение получается очень неплохое.
Самый популярный и простой способ дискретизации основан на частотах значений признаков: отрезок между максимальным и минимальным значением признака разбивается на подотрезков, длины которых выбираются так, чтобы в каждый попадало примерно равное число обучающих примеров. После чего значения признака заменяются на номера отрезков, на которые они попали.
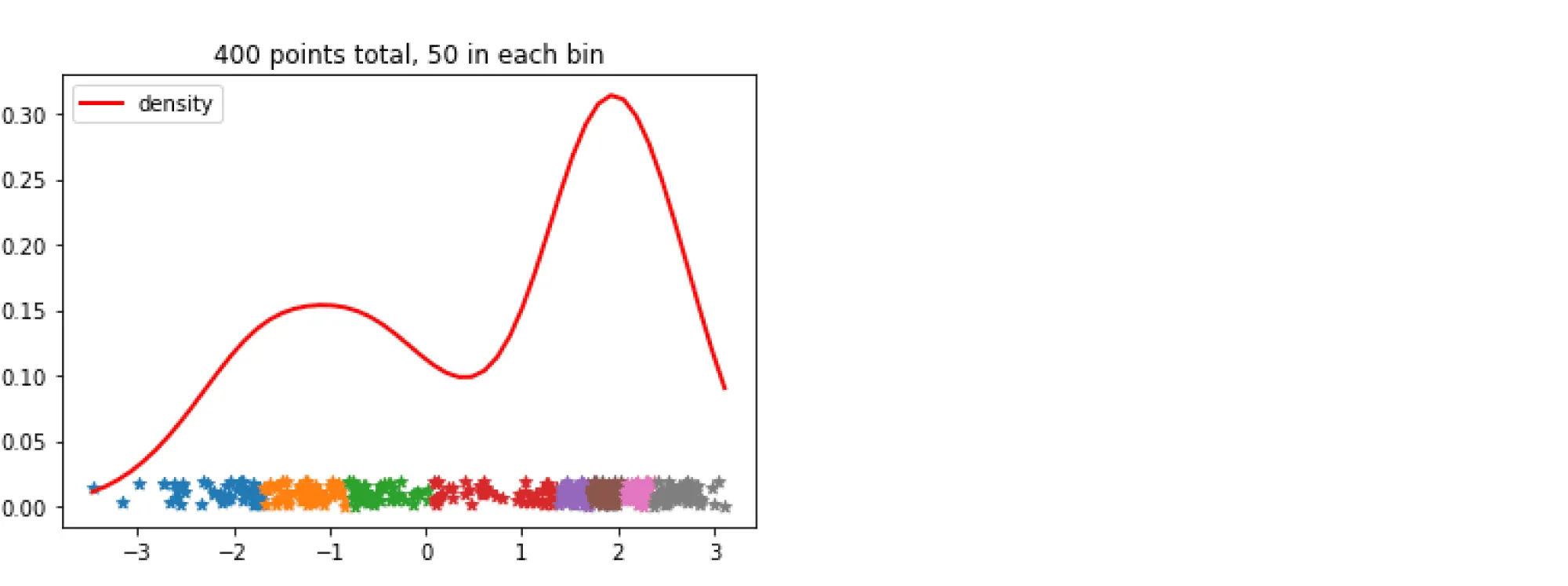
Аналогичная процедура проводится для всех признаков выборки. Полная сложность предобработки — — сортировка за для каждого из признаков.
Теперь в процедуре динамического алгоритма поиска оптимального сплита нам надо перебирать не все объектов выборки, а всего лишь подготовленных заранее границ подотрезков. Частичные суммы статистик тоже придётся поддерживать не для исходного массива данных, а для списка из возможных сплитов. А для того чтобы делать это эффективно, необходим объект, называемый гистограммой: упорядоченный словарь, сопоставляющий каждому значению дискретизированного признака сумму необходимой статистики от таргета на отрезке [B[i-1], B[i]].
Финальный вид алгоритма таков:
- Дискретизируем каждый из признаков на значений. Сложность .
- Создаём корневую вершину
root. - Вызываем
build_tree_recursive(root, data).
Функция build_tree_recursive выглядит следующим образом:
- Проверяем, не пора ли остановиться. Если пора — считаем значение в листе.
- Теперь мы снова используем динамический алгоритм, но объекты будем сортировать не по исходным значениям признаков, а по их дискретизированным версиям, упорядочивая их с помощью сортировки подсчётом (для вершины, в которую попало объектов, сложность будет равна против в стандартной динамике).
- Находим оптимальный сплит за .
- Делим данные, запускаем процедуру рекурсивно для обоих поддеревьев.
Общая сложность:
Гистограммный метод на примере
Давайте посчитаем информативность сплита для MSE на данных с одним признаком, по которому мы уже отсортировали данные:
|
x |
-3 |
-2 |
-0.05 |
1 |
1 |
2 |
6 |
8 |
|
y |
0 |
0.5 |
-1 |
0 |
1 |
2 |
1 |
4 |
Дискретизируем на три отрезка с границами
|
discretized_x |
0 |
0 |
1 |
1 |
1 |
2 |
2 |
2 |
|
y |
0 |
0.5 |
-1 |
0 |
1 |
2 |
1 |
4 |
Строим гистограмму частичных сумм, сумм квадратов и количества объектов для двух отрезков (для третьего можно посчитать, используя общую сумму):
|
b |
0 |
1 |
|
cnt |
2 |
3 |
|
sum_y |
0.5 |
0 |
|
sum_y_sq |
0.25 |
2 |
Всего объектов восемь, сумма таргетов — , сумма квадратов — .
Информативность текущего листа:
Посчитаем значение критерия ветвления для . Информативность левого листа, то есть дисперсия в нём, равна:
Информативность правого листа, то есть дисперсия в нём, равна:
Полное значение критерия для разбиения по :
Mixed integer optimization
Если вам действительно хочется построить оптимальное (или хотя бы очень близкое к оптимальному) дерево, то на сегодня для решения этой проблемы не нужно придумывать кучу эвристик самостоятельно, а можно воспользоваться специальными солверами, которые решают NP-полные задачи приближённо, но всё-таки почти точно. Так что единственной (и вполне решаемой) проблемой будет представить исходную задачу в понятном для солвера виде. По ссылке — пример построения оптимального дерева с помощью решения задачи целочисленного программирования.
Историческая справка
Как вы, может быть, уже заметили, решающие деревья — это одна большая эвристика для решения NP-полной задачи, практически лишённая какой-либо стройной теоретической подоплёки. В 1970–1990-e годы интерес к ним был весьма велик как в индустрии, где был полезен хорошо интерпретируемый классификатор, так и в науке, где учёные интересовались способами приближённого решения NP-полных задач.
В связи с этим сложилось много хорошо работающих наборов эвристик, у которых даже были имена: например, ID3 был первой реализацией дерева, минимизирующего энтропию, а CART — первым деревом для регрессии. Некоторые из них были запатентованы и распространялись коммерчески.
На сегодня это всё потеряло актуальность в связи с тем, что существуют хорошо написанные библиотеки (например, sklearn, в которой реализована оптимизированная версия CART).