
Вступление
Для обучения и проверки качества ML-модели необходимы данные, размеченные человеком. Студенты обычно получают эти данные уже в готовом виде, но в работе над реальными продуктами задачи по сбору и разметке приходится решать самостоятельно, учитывая специфику конкретного продукта.
Готовые наборы зачастую однообразны, а иногда и вовсе мешают достичь требуемых результатов: так, модели компьютерного зрения для беспилотного транспорта необходимо обучать на данных, собранных в той же среде, где используется модель. Кроме того, высокие темпы развития нейросетевых технологий провоцируют все большую необходимость в крупных объемах данных: чем лучше текущее качество модели, тем больше новых данных требуется, чтобы поднять это качество на новый уровень. Как следствие, сбор и разметка данных становится неотъемлемой частью почти любого ML-производства, а качество и количество этих данных напрямую влияет на качество конечного продукта.
Краудсорсинг зарекомендовал себя, как один из эффективных способов сбора и разметки данных в больших масштабах. Его используют в разработке новых технологий, чтобы создавать обучающие датасеты для ML-моделей беспилотных автомобилей, голосовых помощников, чат-ботов, поисковых систем и других разработок.
Качественные данные удается собрать благодаря краудсорсинговым платформам: они помогают снизить количество ошибок с помощью специальных настроек, которые можно найти на платформе, а также дают доступ к огромному количеству исполнителей, способных в любое время присоединиться к работе.
Также секрет успеха кроется в той последовательности действий, которые нужно соблюдать, создавая проект на карудсорсинговой платформе. Участникам краудсорсинговых платформ под силу выполнить не все задания, а только простые: сложные задания нужно разбивать на несколько небольших. Качество выполняемой ими работы нужно проверять с помощью доступных на платформе инструментов контроля качества. Полученные результаты в некоторых случаях нужно правильно обрабатывать (здесь полезно разобраться в способах агрегации данных). Чтобы исполнители получили оплату только за правильно выполненные задания, нужно сформулировать подходящую модель ценообразования и т. д.
Нюансов в работе с краудсорсингом достаточно много, поэтому мы подготовили этот параграф в учебник. Стоит отметить, что в ней мы уделим внимание нетехническим аспектам краудсорсинга для ML. Такой уклон связан с тем, что использование краудсорсинга в качестве инструмента работы с данными требует не только знания технических и математических методов (они пригодятся в финальной части, когда полученные данные необходимо будет обработать), но и умения правильно организовать процесс сбора данных, понимания самого феномена краудсорсинга, который сегодня используется в разных сферах для решения разных задач.
По этой причине структура этого параграфа будет выглядеть следующим образом:
- В первой части мы сделаем общий обзор краудсорсинга в ML и объясним, для каких задач он применим.
- Во второй части мы остановимся на основных этапах запуска краудсорсингового проекта: от деления проекта на небольшие задачи до обработки полученных от исполнителей данных.
- Кроме того, в этом параграфе мы разберем примеры некоторых ML-задач, которые встречаются в проектах в сфере AI и ML. Это сбор данных для поисковых сетей, разметка изображений для беспилотных автомобилей и сбор аудиозаписей для голосовых помощников.
Надеемся, что вам будет интересно погружаться в мир краудсорсинга для ML. Будем рады, если мы поможем вам разложить все по полочкам, чтобы вы смогли дальше наращивать свои знания и изучать отдельные темы более глубоко.
Что такое краудсорсинг в ML?
Существует довольно много определений краудсорсинга, а также близких к нему по значению терминов (например, «человеческие вычисления», «мудрость толпы» и «коллективный разум»). Это связано с тем, что этот метод используется в разных сферах и применяется для решения разного рода задач, в том числе поиска креативных идей, создания контента, сбора денежных средств. Например, автор термина «краудсорсинг», Джефф Хоу, в 2006 году предложил следующее определение этого метода: Краудсорсинг (от англ. crowd — «толпа», source — «использование ресурсов») — это процесс, в котором компания переносит определенные функции, ранее возлагавшиеся на сотрудников, аутсорсинговые предприятия и поставщиков, на неопределенное, достаточно большое количество людей в формате открытого запроса.
Это определение отражает основную идею краудсорсинга. Однако его недостаточно в контексте рассматриваемой нами темы. Мы говорим о краудсорсинге в машинном обучении. Это значит, что мы передаем облаку исполнителей те задачи, которые связаны со сбором и разметкой данных, а также с оценкой этих данных для разного рода проектов. Разработчики используют эти данные, чтобы обучать машины, а именно модели этих машин, выполнять требуемые задачи. Поэтому в машинном обучении краудсорсинг — это дополнительный вычислительный кластер, который помогает командам создавать и улучшать их продукты.
Один из первых проектов, который задействовал краудсорсинг в получении данных для обучения модели, — проект Distributed Proofreaders (с англ. — «Распределенные корректоры»). Его главная цель — цифровизация печатных книг с помощью программы для оптического распознавания символов (OCR). Вовлекая тысячи волонтёров, проект Distributed Proofreaders оцифровывает печатные книги и улучшает программу для распознавания текстов. Чем больше данных модель этой программы получает от волонтеров, тем лучше она считывает текст с отсканированных страниц книг. Соответственно, чем лучше становится эта модель, тем меньше времени и усилий человека требуется для того, чтобы находить и исправлять ее ошибки.
Рассмотрим этот проект подробнее:
- Добровольцам предлагают сравнить отсканированное изображение страницы и текст этой страницы, распознанный с помощью программного обеспечения для оптического распознавания символов (OCR).
- Поскольку программа оптического распознавания текста не справляется с задачей в полном объеме, в тексте часто появляются ошибки. Задача добровольца — исправить ошибки OCR и загрузить файл обратно на сайт.
- Выполненная работа передается второму добровольцу, он проверяет ее, исправляет ошибки.
- Книга аналогичным образом проходит третий этап корректуры и два этапа форматирования с использованием одного и того же веб-интерфейса.
- После того, как все страницы книги прошли через несколько этапов проверки, постпроцессор собирает их в электронную книгу и отправляет в архив проекта «Гутенберг».
- Отредактированные страницы книг в дальнейшем используются разработчиками, как данные для обучения OCR. Модель программы обучается на данных и в дальнейшем совершает меньше ошибок при распознавании текста на изображениях.
Другой пример использования краудсорсинга в ML — сервис reCaptcha. Он был запущен учеными Университета Карнеги-Меллона в 2007 году и стал продолжением проекта Captcha, появившегося в 2000 году. Напомним, что Captcha — это программа, которая защищает сайты от интернет-ботов. Посещая сайт и совершая на нем определенные действия, пользователь получает просьбу заполнить веб-форму. Его задача — вписать в эту форму буквы и цифры, которые он видит на изображении. Люди с хорошим зрением могут легко распознать эти символы, а боты не могут. Так сервис определяет, кто из посетителей сайта человек, а кто — бот. Ботам доступ к сайтам закрывается, так как они наносят вред сайтам.
Создатели проекта Captcha пошли дальше. Они подсчитали, что у каждого человека уходит примерно 10 секунд на ввод одной капчи. А у человечества (10 умножаем на 200 млн) — 500 000 часов. Тогда появилась идея о том, что время, потраченное на ввод капчи, можно использовать с пользой для людей. Это стало началом проекта reCaptcha. Отличие этого проекта от проекта Captcha состоит в том, что вы не только печатаете капчу и подтверждаете, что вы человек, но и одновременно делаете минимальное полезное усилие. В 2007 году таким усилием была оцифровка книг, а с 2012 года reCaptcha стали использовать для распознавания изображений из онлайн-карт. Мы расскажем про инициативу, вошедшую в историю под девизом Stop Spam, Read Books. В чем она заключалась?
- Каждая страница книги сканируется.
- Компьютер расшифровывает слова на каждом отсканированном изображении. Для этого используется технология OCR — та, же технология, что и в первом проекте.
- При распознавании текста OCR допускает ошибки. Их особенно много в распознанных текстах старых книг, поскольку в некоторых местах чернила выцвели и страницы пожелтели. Например, в книгах, написанных более 50 лет назад, компьютер не может распознать более 30% слов.
- Все нераспознанные слова направляются людям, чтобы они их распознали, когда вводят капчу в интернете. Задача добровольцев — ввести слова, взятые из отсканированных книг, которые компьютер не смог распознать.
- Добровольцу необходимо распознать два слова из книги. Почему именно два? Одно из слов взято из книги, и оно неизвестно компьютеру. Соответственно, проверить ответ добровольца компьютер не может. Поэтому волонтер получает второе слово — его компьютер знает. Мы не говорим, какое из слов известно компьютеру, и просим добровольца ввести оба. Если доброволец вводит известное слово правильно, система получает подтверждение, что он — человек, а также получает уверенность в правильности ввода другого слова.
- Одно и то же слово, которое неизвестно компьютеру, направляется десяти участникам проекта. Если все они вводят его одинаково, то есть их ответы совпадают, то это слово отправляется в книгу.
- Как и в случае с первым проектом, данные, полученные от добровольцев, используются для обучения технологии OCR.
Инициативой проекта reCaptcha впечатлилось множество владельцев сайтов. Новый сервис взамен традиционной Captcha установили такие сайты, как Tiketmaster, Facebook, Twitter и примерно 350 000 других сайтов. Каждый день на этих сайтах вплоть до 2012 года люди оцифровывали примерно 100 млн слов в день. Это 2,5 млн книг в год. В результате, в течение пяти лет с момента его запуска в проекте по оцифровке книг поучаствовали минимум 750 млн людей (это 10% всего населения). Книги, оцифрованные в рамках этого проекта сегодня представлены на сайте books.google.com.
Подводя итоги вышесказанного, сформулируем определение краудсорсинга в ML. Краудсорсинг в ML — это способ сбора данных, которые необходимы разработчикам, чтобы обучать машины выполнять необходимые действия. С помощью краудсорсинга разработчики вовлекают в процесс выполнения задач обычных людей, которые не владеют определенными навыками и экспертизой. В рамках четко заданных инструкций они выполняют нужное количество заданий. Результаты этих заданий — собранные, размеченные или оцененные данные — входят в те датасеты, которые используются для обучения машин.
Ключевые принципы краудсорсинга в ML
Применение краудсорсинга в машинном обучении значительно ускорило процесс развития AI продуктов. Беспилотные автомобили, голосовые помощники, поисковые системы, онлайн-карты, машинный перевод появились и развиваются во многом благодаря данным, полученным с помощью краудсорсинга. Например, чтобы поисковая система смогла точно отвечать на вопросы пользователей, нужно проделать большую работу по разметке данных: проанализировать запросы и поведение пользователя, оценить возможные результаты на соответствие запросу, сравнить разные варианты поисковых выдач и выбрать лучший. Все эти данные ложатся в основу моделей, которые учатся искать лучшие ответы, опираясь на размеченные людьми образцы. Такие задачи, на первый взгляд, кажутся трудозатратными и продолжительными по времени. Но если воспользоваться возможностями краудсорсинга и подойти к ним, как к инженерной проблеме, эти сложности будут преодолены.
В этом тезисе содержится основная идея краудсорсинга для AI и машинного обучения: чтобы решить задачу по разметке данных для обучения или оценки качества модели, нужно подойти к ней как к инженерной проблеме. Это значит, что нужно организовать выполнение задачи таким образом, чтобы конечный результат зависел от качества самого процесса, а не от добросовестности или экспертности отдельных исполнителей.
Такой подход требует соблюдения ряда правил. Прежде всего, чтобы проект был доступен максимальному количеству исполнителей и не зависел от редких компетенций, его необходимо разделить на сценарии или небольшие задачи. Принцип деления сложной задачи на несколько микрозадач называется декомпозицией. Это основополагающий принцип для каждого краудсорсингового проекта, создаваемого для задач машинного обучения.
Каждую микрозадачу необходимо детально продумать. Определить элементы, которые будут ее сопровождать. Некоторые из них (например, инструкции или интерфейсы) обязательно должны присутствовать в проекте. Другие — такие как предварительная фильтрация исполнителей или отслеживание их поведения в проекте — используются в случае необходимости. Все эти элементы решают вопрос качества данных: чем лучше продуман проект, чем эффективнее он «сопровождает» исполнителя во время разметки, тем меньше остается пространства для ошибок или недобросовестного поведения.
Детальную схему проекта, состоящую из цепочки микрозадач и сопровождающих их элементов, называют пайплайном (от англ. pipeline — «линия, очередь»). Его создают на этапе планирования проекта и обращаются к нему как к «дорожной карте».
ML-задачи, где используется разметка
Краудсорсинг помогает решить разнообразный спектр ML-задач. Разделим их на две основные группы — разметка и сбор данных.
Разметка данных
К этой группе относится целый ряд задач, в рамках которых пользователю краудсорсинговой платформы необходимо выполнить некоторое действие с уже полученными данными. Например, его могут попросить перевести записи из аудио в текст (транскрипция аудио) или выделить в запросе пользователя в поисковой системе определенные смысловые части, такие как тип продукта, цвет, бренд (NLP-задания). Также в эту группу входят задачи по проверке автоматического перевода, модерации контента, разметке видео или сегментации объектов на изображениях.
В качестве примера рассмотрим задачи по сегментации изображений. Как правило, они нужны для обучения алгоритмов компьютерного зрения. Они используются, например, для создания беспилотного транспорта, который должен распознавать всевозможные препятствия на дорогах: людей, светофоры, разметку, дорожные знаки, дома, заборы, искусственные неровности и т. д. Чтобы эти модели были качественными и могли без труда распознавать любые объекты на своем пути, им нужно показать большое количество изображений и в, более сложных случаях, видео с выделенными на них объектами разных классов.
Выделением этих объектов занимаются пользователи краудсорсинговых платформ. На 2D и 3D изображениях, а также видео, снятых во время движения с помощью камер, радаров и лидаров, они находят нужные объекты и обводят их. Изображения и видео, размеченные по требованиям инструкции, используются для обучения моделей компьютерного зрения.
Самый простой пайплайн задачи по сегментации изображений для беспилотных автомобилей состоит из трех проектов (рис. 1). В первом проекте исполнители отвечают на вопрос, есть ли на фото нужные объекты (например, дорожные знаки). Те изображения, на которых эти объекты есть, перенаправляются в проект номер два. В нем вторая группа исполнителей обводит дорожные знаки с помощью прямоугольников. Эту разметку проверяет еще одна группа исполнителей в следующем проекте, третьем по счету. Далее включается схема так называемой отложенной приёмки заданий. В случае отклонения задание отправляется на повторную разметку. Верно выполненная работа включается в итоговый датасет.
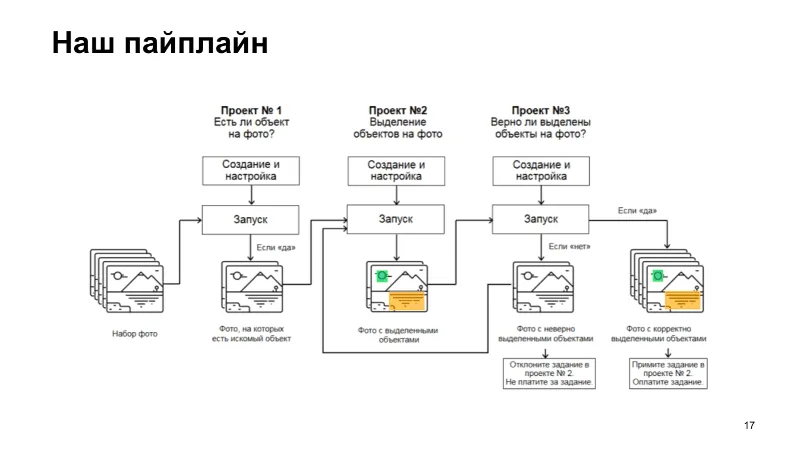
Подобные пайплайны, но еще более многоступенчатые, используются для обучения моделей компьютерного зрения Яндекса. В январе 2020 года инженерам компании удалось продемонстрировать одну из моделей на конференции Consumer Electronics в Лас-Вегасе. Беспилотные автомобили со встроенной моделью проследовали по маршруту с разными дорожными сценариями: нерегулируемыми перекрестками, сложными поворотами со встречным разъездом, пешеходными переходами и многополосными участками. Всего эти автомобили преодолели более 7 тысяч км.
Сбор данных
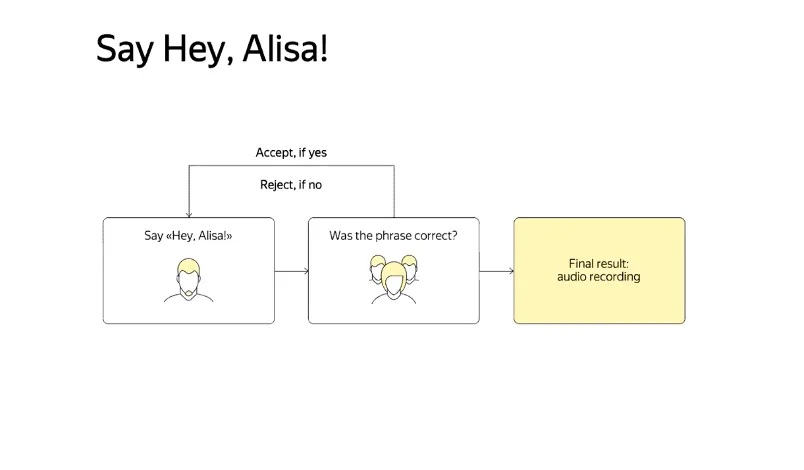
Суть задач, связанных со сбором контента, заключается в поиске материалов (изображений, фотографий, фактов), необходимых для решения проблемы. Например, используя краудсорсинг, инженеры собирают фразы для обучения голосового помощника (рис. 2).
Пайплайн такого проекта выглядит довольно просто: исполнители записывают необходимую фразу, например, «Привет, Алиса», и загружают ее в интерфейс задания на краудсорсинговой платформе. Далее другая группа исполнителей проверяет эти записи на предмет ошибок и других требований: если запись соответствует инструкции, вторая группа подтверждает ее, а если в записи допущены ошибки, отклоняет. В следующем проекте еще одна группа исполнителей записывает недостающие фразы, затем они вновь проходят проверку. Этот процесс повторяется по кругу, пока не будет собрано достаточное количество фраз нужного качества.
Краудсорсинговые платформы
Масштабируемость и скорость выполнения задач по разметке данных напрямую зависят от доступа заказчика к большому облаку исполнителей. Залог успеха здесь — использование открытых краудсорсинговых платформ, которые позволяют постоянно пополнять это облако и, следовательно, масштабировать процессы сбора или разметки данных.
Открытые краудсорсинговые платформы — например, Amazon Mechanical Turk или Толока — работают по принципу маркетплейсов. Заказчик может создать на такой платформе свой проект, найти для него нужных исполнителей, обучить их и поручить им выполнение задания, контролируя качество результата. Пользователи открытой платформы, в свою очередь, могут выбрать интересующий их проект, выполнить задания и получить за проделанную работу вознаграждение. Свой выбор проекта они могут сделать как на основе рейтинга проекта, так и с учетом итогового вознаграждения — либо просто потому, что какая-то задача им интересна больше других.
Открытые краудсорсинговые платформы — инструмент для тех, кто планирует самостоятельно контролировать разметку данных. А это, как правило, большинство проектов в сфере AI и машинного обучения. Для ML-разработчиков крайне важно, чтобы кропотливая работа по написанию инструкций, проектированию интерфейсов, отбору и обучению участников, настройке контроля качества была выполнена в точности так, как это запланировано в пайплайне проекта. Все эти шаги напрямую влияют на качество тренировочных данных, а от них в немалой степени зависит успех продукта.
При выборе краудсорсинговой платформы важно учесть и то, какими инструментами они располагают. Например, с готовыми шаблонами можно быстрее спроектировать интерфейс задания, а инструменты контроля качества помогут отсеять роботов и недобросовестных исполнителей. Кроме того, выбор платформы во многом определит то, с какими исполнителями будет вестись работа. Изучение их характеристик даст понимание, в каких странах они проживают, на каких языках разговаривают и, что немаловажно, сталкивались ли они с проектами, подобными тому, над которым планируется работа.
Альтернативой платформам-маркетплейсам могут стать проекты, которые предлагают готовые датасеты и помощь в разметке данных для проекта. Это, например, Scale AI, Hive Data, Alegion. Такие платформы подойдут не всем — выше уже шла речь о том, что некоторые проекты (как, например, обучение алгоритмов компьютерного зрения) нуждаются в специфическом контексте для сбора датасета.
Кроме того, построенные по общим принципам краудсорсинга проекты могут запускаться и на внутреннее облако исполнителей, связанных с компанией какими-либо договорными отношениями. Это важно в случаях, если речь идет о разметке чувствительных данных. Однако такой процесс тяжело поддается масштабированию, потому что требует больших ресурсов для сопровождения сотрудников.
Границы применимости краудсорсинга
Несмотря на все многообразие задач, которые можно решить с помощью краудсорсинга, есть случаи, когда его применение затруднено либо просто нецелесообразно.
Во-первых, необходимо оценить затраты, сопутствующие запуску проекта. Создание и настройка эффективного пайплайна для сбора или обработки данных требуют времени и квалификации высокоуровневого специалиста. Потраченный им ресурс может не окупиться, если требуется лишь один раз разметить небольшое количество данных.
Облаку исполнителей с трудом поддаются задачи, требующие серьезного включения и поддержания контекста. Секрет краудсорсинга — в создании небольших автономных заданий, каждое из которых может быть решено согласно несложной инструкции. Если исполнителю требуется учитывать большой объем сопутствующей информации, чтобы выполнить задачу верно — скорее всего, ее лучше выполнять без использования краудсорсинга. Например, облако исполнителей вряд ли сможет осуществить перевод книги: ее не стоит разбивать на отдельные предложения, ведь перевод должен быть последовательным и согласованным. В то же время, краудсорсинг может помочь при переводе отдельных фраз в конечном контексте, например, отдельных реплик для голосового ассистента.
Наконец, если задача требует крайне специфических навыков, то поиск или обучение подходящего исполнителя на краудсорсинговой платформе сравнится с наймом эксперта. В таких случаях стоит оценить возможность декомпозиции задачи так, чтобы она оказалась разбита на ряд менее сложных действий. Если сделать это невозможно (например, для выполнения задания требуется знание редкого языка), оптимальным способом поиска исполнителя могут стать профессиональные сообщества.
Этапы создания краудсорсингового проекта
Типичная краудсорсинговая задача состоит из шести этапов:
- Декомпозиция;
- Инструкция и интерфейс;
- Контроль качества;
- Отбор и обучение исполнителей;
- Выбор схемы оплаты и бонусирования;
- Агрегация ответов.
Разберем каждый из этапов на примере уже упомянутого проекта по сбору данных для обучения беспилотных автомобилей. Мы запустим этот проект на краудсорсинговой платформе «Толока».
Декомпозиция
В качестве исходных данных возьмем объемный набор фотографий с изображением улиц. После запуска краудсорсингового проекта мы должны получить те же изображения, но с выделенными на них дорожными знаками. Наша задача — выделить прямоугольниками дорожные знаки на каждой фотографии.
Пример того, как должен выглядеть итоговый датасет с выделенными на них объектами приведен на рисунке 3.

Можем ли мы поручить нашу задачу участникам краудсорсинговой платформы напрямую? В данном случае — нет. Изображения для разметки могут полностью не соответствовать нашему запросу. Например, на изображениях может не быть нужных объектов. Некоторые фотографии могут не загрузиться в интерфейсе (появится ошибка). Чтобы избежать подобных ситуаций, нам нужно отобрать фотографии с подходящими объектами. Отбор фото или их фильтрация станет первой микрозадачей или первым пулом (так называется набор заданий в рамках проекта на платформе «Толока») нашего проекта.
Что дальше? Когда мы получили фотографии с дорожными знаками, мы сможем запустить проект по выделению объектов на изображениях. Наша задача — выделить на фотографиях все дорожные знаки прямоугольниками. Чтобы создать подобное задание на краудсорсинговой платформе «Толока», можно воспользоваться готовым шаблоном. Он предусматривает специальный инструмент, «полигон», который с легкостью позволяет выполнять подобные задания.
На этом мы могли бы остановиться. Получили изображения с выделенными объектами — задача выполнена. Однако для данного проекта потребуется запустить еще одно микрозадание. Фотографии с выделенными объектами необходимо проверить. Кто-то из исполнителей может пропустить некоторые знаки или выделить их неверно. Таким образом, проверка размеченных изображений в конкретном проекте необходима. Но специфика задачи такова, что мы не можем просто сравнить работу отдельного исполнителя с заведомо верным примером: выделенные области могут отличаться на несколько пикселей, но это не будет означать, что ответ неверен.
Итак, что мы делаем? Мы создаем новый пул заданий, в котором спрашиваем «Верно ли выделены объекты на фото?». Участники отвечают на вопрос, после чего фото с верно отмеченными объектами отправляются в итоговый датасет и оплачиваются. Фото с неверно выделенными объектами отклоняются и не оплачиваются. Все фотографии, которые не проходят проверку, отправляются на переразметку (т. е. размечаются повторно).
Какие выводы мы можем сделать по итогу разбора декомпозиции проекта? Самый главный вывод — решение о декомпозиции задачи следует принимать, исходя из типа задачи и данных, которые есть на входе — это могут быть изображения, видео, ссылки, точки на карте, координаты этих точек. Также следует различать типичные случаи, в которых декомпозиция особенно рекомендована для проекта. Речь идет об объемных проектах, многослойных задачах, задачах со множеством вариантов ответов и объемных процессах:
- Объемные проекты. Если в рамках проекта нужно ответить на несколько вопросов, то лучше сделать это поочередно или в выбранной последовательности.
- Многослойные задачи. Если в рамках одной задачи нужно выполнить более одного действия (например, отнести объект к определенной группе и ответить на вопрос, предназначен ли он только для взрослых), то лучше сделать это поочередно или в выбранной последовательности.
- Задачи со множеством вариантов ответов. Если в задании есть один вопрос и 10 и более вариантов ответа, то лучшим решением будет группировка ответов по темам, а затем создание отдельного проекта для каждой группы ответов.
- Объемные процессы. Если задача включает сложные механизмы контроля качества и отложенную проверку, необходимо создать отдельный проект, в котором одна группа исполнителей будет проверять другую.
Есть ли случаи, когда декомпозировать задачу не нужно? Да. Нет необходимости разбивать задачу на части, если соблюдаются два критерия: инструкции к задаче помещаются на половине листа бумаги формата А4, или задача выполнена с помощью одного действия, например, выбора из нескольких категорий.
Инструкция
После декомпозиции нашего проекта нам необходимо создать для него инструкцию. Инструкция потребуется для каждой микрозадачи. В нашем случае нам необходимо создать три инструкции.
Какие пункты мы обязательно в них укажем?
Первым пунктом инструкции станет описание задачи. В нем мы объясним участнику, что предстоит сделать и где будет использован результат этой работы. Например:
Вашему вниманию представлен проект, результаты которого помогут сделать беспилотные автомобили безопасным транспортом. Ваша задача — определить, есть ли дорожные знаки на изображении. Выберите ответ «Да», если изображение содержит дорожные знаки. Выберите ответ «Нет», если на изображении дорожных знаков нет. На изображении, представленном ниже, есть несколько дорожных знаков. Значит, правильный ответ — «Да».
Далее, мы подробно опишем условия входа в задание: расскажем, будет ли обучение и экзамен, с каким качеством его нужно пройти, есть ли в проекте повторный экзамен для тех, кто не прошел испытание с первого раза. Также опишем ценообразование. Например:
Чтобы выполнить это задание, вам потребуется пройти обучение на тренировочном пуле. В тренировочный пул войдут задания аналогичные тем, что будут в основном проекте. После обучения мы предложим вам пройти экзамен. В экзамен войдут 5 изображений.
Следующий элемент инструкции — технические нюансы. Здесь мы расскажем, с какого устройства потребуется выполнить задание — со смартфона или с компьютера — и какие дополнительные настройки браузера будут необходимы. Этот пункт в особенности важен для второго задания в рамках нашего проекта. Разметить дорожные знаки прямоугольниками участники смогут только с компьютера:
Мы рекомендуем выполнять это задание с персонального компьютера. Это необходимо, чтобы вы смогли корректно выделить все необходимые объекты на изображении.
Краткое описание интерфейса задания — еще один важный пункт в инструкции. Для большей наглядности мы сделаем скриншот с комментариями о том, для чего нужны те или иные блоки и кнопки. Если в задании простой интерфейс, эту часть можно пропустить. Например:
Используйте желтый квадрат («полигон») в левой части экрана, чтобы выделять дорожные знаки на изображении.
Теперь о самом задании. Чтобы избежать ошибок, мы пошагово опишем все частые сценарии, которые могут случиться при выполнении наших задач. Также мы укажем, что делать с нестандартными случаями. Добавим примеры: несколько кейсов сделают теорию намного понятнее. Справочные материалы — глоссарий, faq — важное дополнение к этим сценариям. Наконец, мы расскажем, куда направлять вопросы по заданию или проекту в целом.
На что мы обратим внимание при написании текста?
Первое, за чем стоит проследить — сам язык, которым написана инструкция. Мы откажемся от профессионального сленга и не будем использовать терминологию. Некоторые термины, например, «полигоны», мы объясним или заменим синонимами — «прямоугольники». Наша задача — сделать инструкцию простой и понятной для большого числа участников. Следуя этой же задаче, мы упростим стиль и синтаксис (одна мысль = одно предложение; одна тема = один абзац), не будем использовать пояснения в скобках и сделаем форматирование единообразным.
Готовый текст инструкции мы обязательно проверим, выполнив некоторое количество заданий. Такое упражнение быстро покажет, какие случаи еще не описаны в инструкции, а какие описаны мало. Кроме того, оно позволит проверить как выглядит наше задание на разных устройствах: умещаются ли все картинки и скриншоты на экранах мобильного телефона, планшета и компьютера.
В итоге каждая инструкция не займет больше двух экранов. Это максимальное количество пространства для инструкции, за пределы которого лучше не выходить. Если инструкция все же не вписывается в такой объем, вероятно, задача слишком многосоставная и ее нужно декомпозировать.
Агрегация результатов
Представим, что мы запустили наш проект и получили необходимые данные. В краудсорсинговых проектах данные обычно собираются в перекрытии (мнения большинства) — это один из распространенных механизмов контроля качества исполнителей и улучшения качества итогового набора данных. Но как выбрать из нескольких оценок финальную?
В данном случае нам помогут механизмы агрегации данных. Что они делают? Они обрабатывают файлы с ответами исполнителей и выбирают из нескольких ответов тот, который с наибольшей вероятностью окажется верным. Рассмотрим принцип работы механизмов агрегации данных на примере первого пула с заданиями (см. рис. 4).
У нас есть набор изображений, и наша цель — отнести каждое изображение к группе «изображения с дорожными знаками» или к группе «изображения без дорожных знаков». В соответствии с принципом краудсорсинга задание должно быть распределено между несколькими исполнителями, каждый из которых размечает некое подмножество изображений. В результате для каждого изображения у нас есть несколько результатов разметки. Цель метода агрегации — объединить эти результаты в один качественный ответ.
Мнение большинства
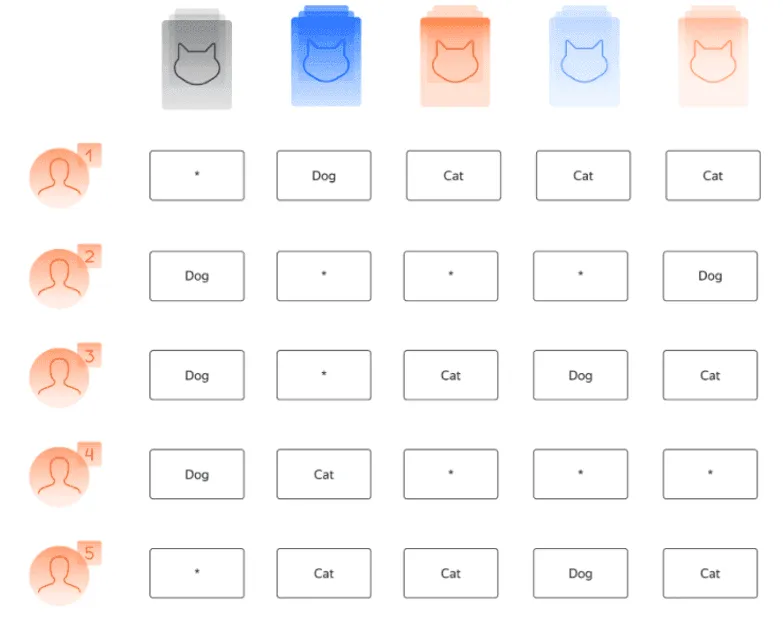
Алгоритм агрегации данных «Мнение большинства» основан на предположении, что правильный ответ — этот тот, который выбирают большинство исполнителей (рис. 5). Самый популярный ответ становится финальным ответом.
Практика показывает, что при помощи метода, основанного на мнении большинства, можно получить достойные результаты. Поэтому этот метод с успехом применяется во многих проектах. Также одно из преимуществ этого метода заключается в том, что он весьма нагляден и логика его работы понятна. Однако в проектах краудсорсинга существуют определенные временные и бюджетные ограничения. Наша цель в том, чтобы собрать минимальный объем данных, необходимый для достижения желаемой точности. С этой точки зрения, метод, основанный на мнении большинства, далеко не всегда будет оптимальным выбором. Чтобы осознать слабые стороны метода, рассмотрим его модель.
Модель
Модель, лежащая в основе метода, проста. Есть N изображений и M исполнителей. Каждое изображение подразумевает некий неизвестный ответ («изображения с дорожными знаками» или «изображения без дорожных знаков» в нашем случае). При использовании модели, основанной на мнении большинства, предполагается, что если исполнитель разметил изображение , его ответ является правильным с некоторой вероятностью
При этом вероятность правильного ответа полагается одинаковой для каждого исполнителя и вопроса. Допущение, что учитывает, что для каждого исполнителя вероятность правильного ответа выше, чем неправильного. В таком случае, поскольку число разметок для каждого изображения достаточно велико, мнение большинства с высокой вероятностью даст истинные ответы.
Ограничения
В силу своей простоты, метод основанный на мнении большинства имеет ряд ограничений:
- **Однородность исполнителей.**Во-первых, данный метод предполагает, что все исполнители обладают одинаковыми способностями. Иными словами,для каждого конкретного вопроса вероятность того, что исполнитель правильно ответит на вопрос, одинакова для всех исполнителей. Однако на практике пул исполнителей на краудсорсинговых платформах чрезвычайно разнообразен: кто-то из них очень аккуратно и скрупулезно выполняет задачи, а кто-то небрежен и чаще допускает ошибки. Таким образом, одно из направлений совершенствования модели, основанной на мнении большинства, — это учет различия в способностях исполнителей в рамках модели.
- **Однородность вопросов.**Во-вторых, модель, основанная на мнении большинства, предполагает, что вопросы имеют одинаковую сложность. Другими словами, вероятность того, что исполнитель правильно ответит на вопрос, одинакова для всех вопросов. Однако некоторые вопросы в рамках проекта могут быть сложнее других. Таким образом, еще одно направление по улучшению модели на основании мнения большинства — это учесть в модели разную степень сложности вопросов.
Далее мы рассмотрим оба направления развития модели и расскажем о других алгоритмах, учитывающих особенности краудсорсинговых заданий.
Агрегация с учетом способностей исполнителей
Рассмотрим модель, которая учитывает неоднородность исполнителей при агрегации ответов.
Модель
Естественный способ учесть различия в способностях исполнителей — ввести параметр качества для каждого исполнителя. Если есть исполнителей, то мы можем связать каждого исполнителя с неизвестным параметром качества . Чем выше параметр качества исполнителя, тем больше вероятность того, что исполнитель ответит на вопрос правильно:
Другими словами, вероятность того, что исполнитель правильно ответит на вопрос, своя для каждого исполнителя (но от вопроса она все еще не зависит).
Методы
В ситуации, когда у исполнителей разные способности, логично присваивать больший вес ответам более сильных исполнителей и меньший вес — ответам более слабых. Однако проблема в том, что параметры качества для исполнителей априори нам не известны. Основная идея двух методов модели агрегации данных с учетом способностей исполнителей заключается том, чтобы одновременно оценить параметры качества для исполнителей и ответы на поставленные вопросы. Рассмотрим каждый их них.
Использование большого объема контрольных заданий
Контрольные вопросы (также honeypots, golden sets) — это задания, на которые заказчик заранее знает правильные ответы. На практике мы часто добавляем в набор данных определенное количество контрольных вопросов, чтобы контролировать качество работы исполнителей. Когда этих вопросов достаточно много, мы можем использовать их для оценки качества работы. Предположим, что у нас есть контрольных вопросов и некий исполнитель , который правильно ответил на вопросов из контрольных вопросов. Тогда мы можем оценить параметр качества для исполнителя следующим образом:
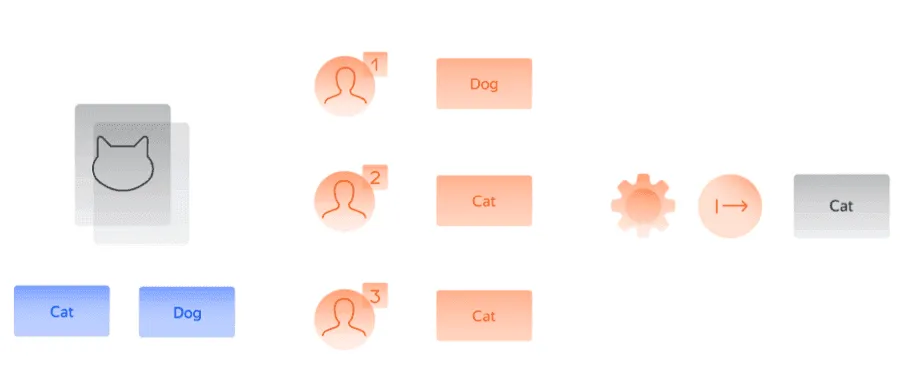
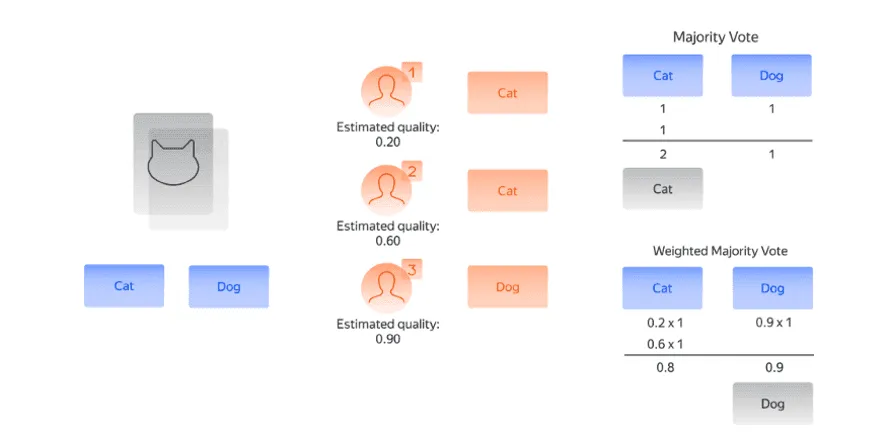
Теперь, когда у нас есть оценка параметра качества, мы можем оценить ответ каждого исполнителя по-разному. Эта идея подводит нас к концепции взвешенного мнения большинства (от англ. Weighted majority vote).
Идея этого метода проиллюстрирована на рисунке ниже (рис. 6). Предположим, что у нас есть нестандартное изображение, на котором столб похож на дорожный знак. В этом случае модель, основанная на простом мнении большинства, не делает отличия между ответами исполнителей с меньшими способностями (первых двух исполнителей) и ответами исполнителя-эксперта (последнего исполнителя) и допускает ошибку. Напротив, модель взвешенного мнения большинства дополнительно взвешивает каждый ответ полученным коэффициентом качества исполнителя. Такая модель приводит к правильному ответу, поскольку мнение исполнителя-эксперта в таком случае перевешивает мнения двух других исполнителей.
Когда контрольных вопросов не так много
Метод взвешенного мнения большинства подходит для тех случаев, когда в проекте есть достаточное количество контрольных заданий, необходимых для оценки качества работы исполнителя. Однако зачастую контрольных заданий в проекте не хватает, в связи с чем оценки могут быть довольно неточными. Кроме того, исполнители могут коллективно выявить контрольные вопросы и начать обманывать систему, давая правильные ответы на контрольные вопросы и случайные ответы на другие. В этом случае, чтобы оценить параметры качества исполнителей при ответе на неизвестные вопросы, мы можем использовать метод Дэвида — Скина:
Метод Дэвида-Скина (Dawid, Skene, 1979)
Метод Дэвида-Скина одновременно находит значения качества исполнителей и ответы на вопросы, которые согласуются с наблюдаемыми данными в наибольшей степени.
Мы имеем в качестве данных — количество раз, при которых разметчик поставил класс объекту (возможно, разметчик видел этот объект несколько раз). Обозначим через
это наши латентные величины.
В качестве параметров имеем
- — вероятность того, что разметчик поставил класс вместо правильного класса .
- — вероятность класса .
Примем также обозначения:
- ,
- ,
- .
Поймём, какой будет функция неполного правдоподобия в этой задаче. Прежде всего,
Если – номер класса -го объекта, то
(значения однозначно определяются номером истинного класса, поэтому справа пропадает). Далее, мы считаем, что разметчики действуют независимо, поэтому
Разберёмся с величиной . Она отвечает за то, какие классы -й разметчик ставил -му объекту. Мы считаем, что встречи разметчика с объектом упорядочены по времени, тогда
Эту вероятность можно переписать в виде
а итоговое неполное правдоподобие предстаёт в виде
Его нам нужно максимизировать по и
Пояснение к формуле:
Вне больших скобок фиксируются объект и его класс, сама скобка возводится в степень 1, если рассматривается правильный класс объекта, и в степень 0 иначе. Внутри сначала записана вероятность того, что объект имеет данный класс, а затем — перебор по всем пользователям и всем классам, которые мог поставить данный пользователь. Наконец, записывается вероятность того, что пользователь нашему объекту поставил некоторый класс, которая возводится в степень того, сколько раз он поставил этот класс. Например, если пользователь видел изображение котика 5 раз, при этом 3 раза он сказал, что котик, а два раза — песик, то вероятность для данного котика учтется 3 раза, а вероятность — 2 раза.
Рассмотрим концепцию метода Дэвида-Скина на простом примере (рис. 7).
Предположим, что у нас есть только вопросов и исполнителей. Каждый исполнитель отвечает на все вопросы. В этом случае наблюдаемые данные — это ответы исполнителей на вопросы.
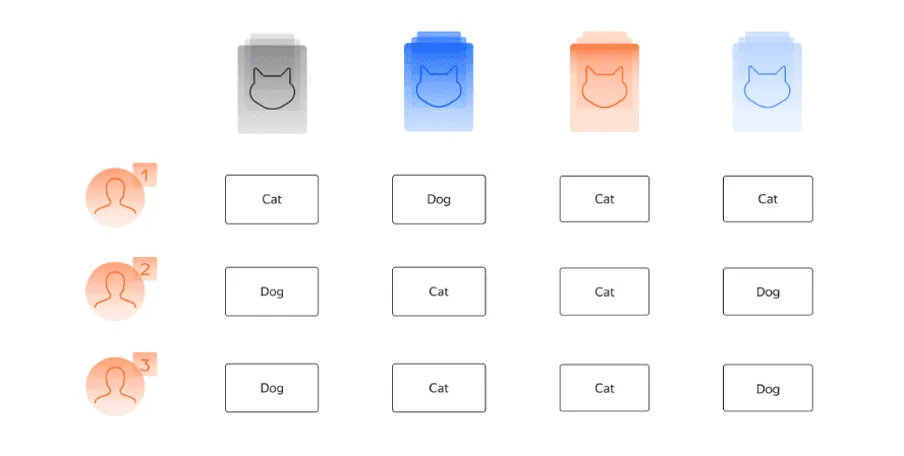
Давайте разберемся в том, каким образом метод Дэвида — Скина позволяет найти параметры качества для исполнителей и те ответы на вопросы, которые лучше всего соответствуют наблюдаемым данным. Для этого рассмотрим два варианта, показанные на картинках ниже (см. рис. 7.1). Каждая картинка предполагает свой набор параметров. Посмотрим, какой из предложенных вариантов лучше соответствует наблюдаемым данным.
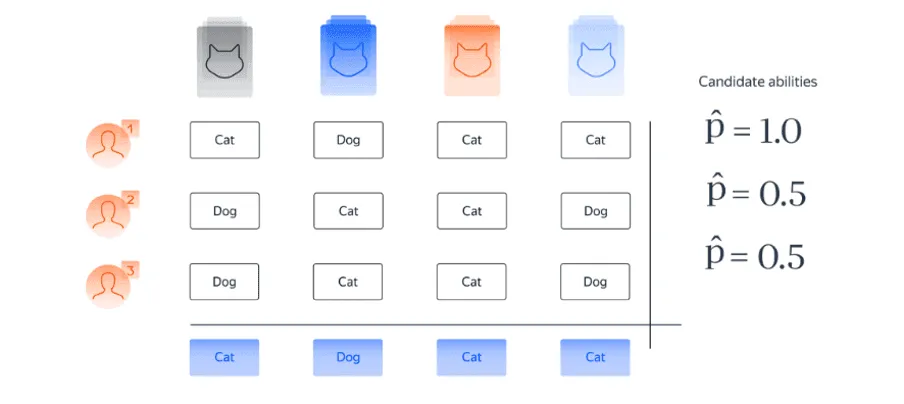
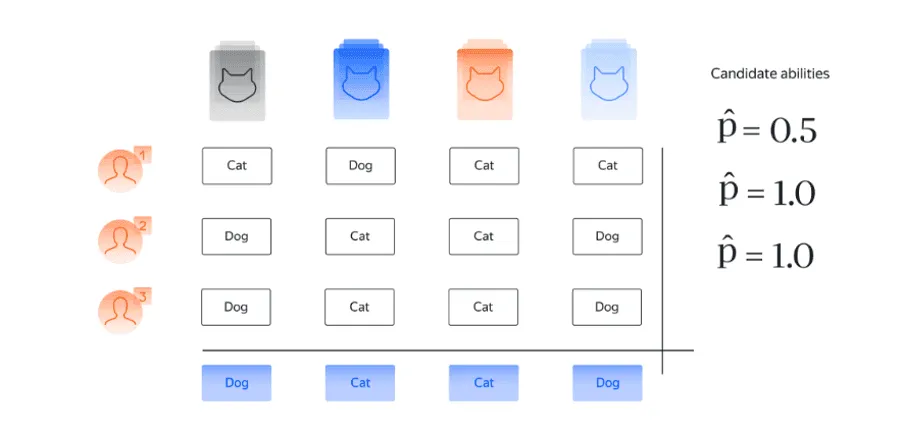
Во-первых, обратите внимание, что на обоих изображениях предложенные ответы согласуются с ответами исполнителя, у которого, по оценкам, высокий параметр качества. Но какой выбор параметров подходит данным лучше всего? Чтобы ответить на этот вопрос, обратите внимание, что ответы второго и третьего исполнителей полностью совпадают. Если параметры качества для этих исполнителей соответствуют первой картинке , тогда, если верить этой модели, эти два исполнителя отвечают наугад. В таком случае высокая степень согласия между исполнителями нас бы скорее удивила, поскольку отвечая наугад, они должны время от времени расходиться в своих ответах. Напротив, если исполнители 2 и 3 — эксперты, как на втором изображении , тогда мы ожидаем, что у них будет высокая степень согласия, и это то, что мы видим в данных. Интуитивно, второй набор параметров лучше согласуется с наблюдаемыми данными. Приведенный простой пример показывает, что концепция согласованности между потенциальными параметрами и наблюдаемыми данными позволяет нам исключить те варианты, которые плохо согласуются с наблюдаемыми данными.
Оба метода — взвешенное мнение большинства и агрегация по методу Дэвида — Скина — входят в стандартный функционал Толоки. В двух наших пулах, в первом и третьем, мы будем использовать метод Дэвида — Скина. Он позволит нам получить наиболее точные данные для нашего проекта. Подробнее узнать о том, как получить агрегированные результаты из размеченного пула, можно в документации.
Агрегация с учетом сложности вопросов
Метод Дэвида-Скина и метод, основанный на мнении взвешенного большинства, — основа современного краудсорсинга. Многие создатели проектов повышают качество данных, используя эти методы агрегации. Однако существуют и другие современные подходы. Например, есть группа подходов, которые учитывают сложность вопроса при агрегировании ответов.
Параметрический подход
Аналогично тому, как мы замеряли качество для каждого исполнителя, вводя параметр качества , точно так же для каждого исполнителя мы можем ввести параметр сложности для каждого вопроса. Тем не менее, главная проблема заключается в том, как описать взаимодействие между качеством исполнителя и сложностью вопроса, и в результате рассчитать вероятность того, что конкретный исполнитель правильно ответит на выбранный вопрос. В работе Уайтхилла с соавторами (2009) предлагается следующее решение.
- Во-первых, параметр качества для исполнителя, который раньше мерился в диапазоне , теперь задается в интервале . В частности, возможно нулевое качество , которое соответствует ситуации, когда исполнитель отвечает на все вопросы наугад. Положительные значения качества подразумевают, что работник с большей вероятностью даст правильный ответ, а отрицательные значения означают, что исполнитель настроен враждебно и с большей вероятностью даст неправильный ответ.
- Во-вторых, для параметра сложности каждого вопроса также может быть дана интуитивная интерпретация: низкая сложность вопроса означает что вопрос настолько прост, что любой исполнитель ответит на него правильно с вероятностью, близкой к 1. Чем выше уровень сложности, тем меньше вероятность того, что конкретный исполнитель ответит на вопрос правильно.
Объединив эти параметры, модель предполагает, что вероятность для конкретного исполнителя при ответе на конкретный вопрос может быть корректно описана следующим параметрическим выражением:
Следует заметить, что в таком случае вероятность является функцией и самого исполнителя, и вопроса, на который исполнитель отвечает. Как только мы выбрали параметрическое уравнение для описания взаимосвязи между уровнем качества исполнителя и сложностью вопроса, с одной стороны, и вероятностью правильного ответа, с другой, мы можем применять все те же принципы, что и для расчета параметров по модели Дэвида – Скина. Таким образом мы можем оценить не только параметры модели, но и полученные ответы на вопросы. Более подробно об этом можно почитать в статье.
Несмотря на то, что параметрические модели позволяют делать весьма эффективные выводы, в них неизбежно заложены сильные допущения о когнитивных процессах, присущих исполнителям при ответе на вопросы. Эти допущения обычно невозможно проверить, поэтому неясно, насколько хорошо они согласуются с реальностью. Соответственно, если допущения параметрической модели неверны, то и методы, используемые такой моделью, могут дать неожиданные результаты. Это подводит нас к идее непараметрического подхода, где можно попробовать избежать сильных допущений о мыслительных процессах.
Непараметрический подход
Непараметрический подход предложил Нихар Б. Шах с коллегами в 2016 году. Вместо моделирования вероятностей, что исполнитель верно ответит на вопрос , считается, что между этими вероятностями есть взаимосвязь. При этом модель использует два ключевых допущения:
- Во-первых, предполагается, что исполнителей можно выстроить в ряд в порядке возрастания способностей. Если исполнитель занимает в этом ряду более высокую позицию, чем исполнитель , то при ответе на каждый вопрос исполнитель с большей вероятностью даст правильный ответ, чем исполнитель .
- Во-вторых, предполагается, что вопросы можно выстроить в ряд в зависимости от их сложности. Если вопрос сложнее вопроса , то любой исполнитель совершит ошибку при ответе на вопрос с не меньшей вероятностью, что и отвечая на вопрос .
Стоит заметить, что эти допущения гораздо слабее, чем в параметрической модели. В самом деле, параметрическая модель не только предполагает существование таких упорядоченных рядов, но и задает все вероятности. С другой стороны, непараметрический подход делает всего лишь естественное предположение о существовании последовательных рядов, но не ограничивает набор когнитивных механизмов, характерных для исполнителей. Было показано, что в некоторых случаях непараметрическая модель позволяет лучше делать выводы. Более подробно об этом можно почитать в полном тексте статьи.
Как мы уже говорили, эти подходы еще достаточно новые и не успели стать классикой краудсорсинга. Если сложность вопросов в вашем проекте существенно варьируется, мы рекомендуем более основательно изучить упомянутые методы и лежащие в их основе допущения, а затем опробовать их на практике.
Использованная литература
- Jeff Howe, The Rise of Crowdsourcing, The Wired, 2006.
- Джефф Хау, Краудсорсинг: Коллективный разум как инструмент развития бизнеса, Альпина Паблишер, 2012.
- Omar Alonso, The Practice of Crowdsourcing, 2019.
- «Cамая богатая часть планеты работает бесплатно во время перерывов на кофе»: редактор Wired Джефф Хау о краудсорсинге, T&P, 2012.
- Р. А. Долженко, А. В. Бакаленко, Краудсорсинг как инструмент мобилизации интеллектуальных ресурсов: опыт использования в Сбербанке России, Российский журнал менеджмента, Том 14, №3, 2016, С. 77–102.
- Беспилотные автомобили Яндекса на CES 2020: 7 тысяч км без водителя за рулём по улицам Лас-Вегаса, Новости Яндекса, 2020.
- Метод Дэвида и Скина