
Если наш датасет таков, что все признаки целочисленные и вещественные, нет пропущенных значений и других приятных сюрпризов, то матрица объекты-признаки — это просто матрица, к которой можно пробовать применять инструменты из линейной алгебры, а среди таковых весьма полезными оказываются матричные разложения, то есть различные способы представить матрицу в виде произведения двух или более матриц, обычно специального вида. Такие разновидности, как LU-разложение, QR-разложение, разложение Холецкого вы несомненно встретите, если откроете код любой библиотеки численной линейной алгебры, но суждено ли матричным разложениям играть роль только лишь винтиков и шестерёнок, запрятанных внутри инструментов машинного обучения, или какие-то из них и сами по себе могут помочь вам анализировать данные? На этот вопрос мы попробуем ответить в данном разделе. Но прежде, чем переходить к конкретным методам, мы разберёмся, к каким моделям данных можно прийти, разложив матрицу в произведение.
Итак, я разложил матрицу в произведения — и что же?
Предположим, что нашу матрицу объекты-признаки мы представили в виде произведения (или, более общно, приблизили в каком-либо смысле таким произведением):
где внизу указаны размеры матриц (то есть в нашем датасете объектов и признаков). Что это может означать?
Смесь признаков
Мы считаем, что каждый из признаков нашего исходного датасета — это смесь (то есть линейная комбинация) скрытых (латентных) признаков:

По сути это одна из самых простых моделей с латентными переменными, в которой исходные признаки выражаются через латентные линейным образом. Если , то мы получаем приближённое описание нашего датасета с помощью меньшего количества признаков. На уровне объектов каждый объект (-мерная строка) приобретает латентное представление (-мерная строка), с которой он связан соотношением . Мы можем представлять, что наши объекты представляют из себя не -мерное облако, а лежат на некоторой -мерной плоскости; переходя к -мерным представлениям , мы обнажаем эту структуру.
Точность аппроксимации можно измерять по-разному; наиболее популярной (в силу вычислительной простоты) является норма Фробениуса — соответствующую модель называют анализом главных компонент, или PCA (Principal Component Analysis).
Понижение размерности признакового пространства
Мы можем захотеть описать наш датасет меньшим чем количеством признаков (а может быть, и вообще каким-то весьма маленьким). У нас может быть несколько причин для этого, например:
-
Признаков очень много, и мы боимся, что обучение на них будет занимать очень много времени или что в процессе обучения нам потребуется слишком много оперативной памяти;
-
Мы считаем, что в данных есть шум или что часть признаков связаны соотношением приближённой линейной зависимости — иными словами, мы уверены, что значительную часть информации можно закодировать меньшим числом признаков
Мы уже обсуждали, что это можно получить, построив приближённое разложение:
Математика помогает. Матрица имеет ранг тогда и только тогда, когда она представляется в виде
для
и не представляется в таком виде для меньших .
Доказывать это мы не будем, но подметим, что приблизить датасет линейной смесью признаков — это то же самое, что приблизить матрицу матрицей ранга .
Качество приближения. Нам, конечно же, хочется, чтобы приближение было наилучшим — скажем, в том смысле, чтобы разность была минимальной в каком-либо смысле. Можно предложить много разных метрик; остановимся на двух:
-
Норма Фробениуса.
Представим, что матрица — это просто вектор из чисел, который зачем-то записали в виде прямоугольной таблицы. Тогда его норму можно записать в видеЭту норму (а точнее, её квадрат) легко оптимизировать.
-
Операторная -норма.
Вычислять её тяжко, а уж оптимизировать вообще непонятно как, зато звучит круто. Идея в том, что отображения можно сравнивать в зависимости от того, как оно действует на векторы: чем больше оно умеет удлинять векторы — тем оно «больше»:Поскольку , достаточно брать супремум только по векторам единичной длины, то есть по единичной сфере. Так как это компакт, непрерывная функция достигает на нём своего максимального значения, то есть мы можем переписать
Смесь объектов
Мы считаем, что каждый из объектов нашего исходного датасета — смесь (то есть линейная комбинация) скрытых объектов:

Такая интерпретация может быть полезна, например, в ситуации, когда объекты — это записи с каждого из нескольких микрофонов в помещении, признаки — фреймы, а скрытые объекты — это голоса отдельных людей.
Также данную модель можно интерпретировать как что-то вроде поиска типичных объектов.
Отдельные представления для объектов и признаков
Эту интерпретацию лучше всего пояснить на примере. Пусть объекты нашего датасета соответствуют пользователям интернет-магазина, а признаки — товарам, причём в клетке с индексом записана единица, если пользователь интересовался товаром, и ноль — если нет (или, в более общей ситуации, рейтинги, которые пользователи ставят товарам).

При перемножении матриц и на -м месте произведении стоит скалярное произведение -й строки и -го столбца . Таким образом, степень релевантности товара пользователю моделируется скалярным произведением (напрашивается сравнение с косинусным расстоянием) вектора, представляющего -го пользователя, и вектора, представляющего -й товар.
Заметим ещё, что координат вектора, ответчающего пользователю, равно как и координат вектора, отвечающего товару, можно рассматривать как латентных признаков, которые в идеальном мире являются интерпретируемыми и характеризуют «сродство» пользователя и товара с некоторым аспектом бытия:

Матрицы в разложении: физический смысл
Но матрицы в разложении обычно не абы какие — так какие из разновидностей могут быть полезны?
Во всех известных вам матричных разложениях к отдельным сомножителям предъявляются определённые требования: симметричность, треугольность, ортогональность — некоторые из них (скажем, симметричность) не имеют физического смысла ни в одной из указанных выше интерпретаций. Но одно оказывается полезным.
Ковариация и дисперсия признаков
Для начала — и это важно — предположим, что матрица центрирована по столбцам, то есть среднее в каждом из столбцов (= признаков) равно нулю (если это не так, то вычтем из каждого столбца его среднее).
Теперь матрица ковариации признаков может быть с точностью до константы оценена как :

И мы видим: -й и -й столбцы матрицы ортогональны тогда и только тогда, когда соответствующие признаки не коррелированы.
При этом -й диагональный элемент матрицы — это дисперсия -го признака.
Вывод: матрица, ортонормированная по столбцам, отвечает датасету, в котором признаки не коррелированы и имеют единичную дисперсию
Сингулярное разложение
С помощью сингулярного разложения можно перейти от исходных признаков к потенциально небольшому количеству «самых важных» , по-быстрому визуализовать данные или построить простенькую рекомендательную систему. Конечно, глубинные автоэнкодеры, TSNE или DSSM справятся с этим гораздо лучше, но если данных относительно немного или если хочется что-нибудь быстро попробовать «на коленке», старое доброе сингулярное разложение всегда подставит плечо.
Математическое определение
Сингулярным разложением матрицы называется разложение
где и — матрицы, ортонормированные по столбцам, а — диагональная матрица, у которой .
Числа называются , а столбцы и — и сингулярными векторами соответственно (их алгебраический смысл станет ясен чуть ниже).
Сингулярное разложение можно записать в полном или в усечённом виде:

Пара предостережений по поводу ортогональности по столбцам:
ортогональна по столбцам
(элементы — скалярные произведения столбцов )
но (не обязательно равно; элементы — скалярные произведения строк )
Ясно, что хранить полное разложение нет смысла: ведь бесполезные, умножающиеся на нули, блоки будут лишь занимать память.
По-английски сингулярное разложение называется SVD (singular value decomposition), и мы будем активно использовать эту аббревиатуру.
Если вы не любите математику, можете пропустить. С точки зрения математики сингулярное разложение говорит следующее. Пусть — матрица линейного отображения .
Тогда найдётся ортонормированый базис в пространстве и ортонормированый базис в пространстве , в которых действие оператора записывается следующим образом:
(знатоки функционального анализа могут узнать в этом частный случай теоремы Гильберта-Шмидта).
Сингулярное разложение и операторная l2-норма.
Можно показать, что , эта самая операторная l2-норма матрицы, равна — квадрату наибольшего сингулярного числа.
Сингулярное разложение и норма Фробениуса. Можно показать, что
Контрольный вопрос.
Единственно ли сингулярное разложение матрицы? Давайте сразу считать, что речь об усечённом разложении.
Есть очень простой источник неоднозначности: если , то и ; при этом умножение вектора на не попортит ортонормированности базиса. Иными словами, мы можем одновременно поменять знаки -х столбцов матриц и (без транспонирования!) без ущерба для разложения.
Есть и более тонкие, хотя и весьма частные, ситуации. Можете ли вы, например, указать несколько различных сингулярных разложений матрицы ? Да-да, для неё сингулярное разложение максимально неоднозначно. Можете ли вы теперь придумать не скалярную матрицу, у которой были бы различные SVD, отличающиеся не только знаками столбцов матриц и ?
Теоретико-вероятностная интерпретация SVD
Если (рассмотрим сейчас не усечённое, а полное разложение, в котором матрицы и квадратные ортогональные), то
Отметим, что в рассматриваемой ситуации не обязательно квадратная, и поэтому нельзя написать, что ; тем не менее, — это квадратная матрица с числами на диагонали.
Контрольный вопрос
Точно так же мы можем вычислить , где опять-таки — квадратная матрица с числами на диагонали. И всё бы хорошо, но если не квадратная, матрицы и имеют разные размеры. Так в чём же подвох?
Как бы то ни было, в (ортогональном!) базисе из (ортогональных!) столбцов матрица приводится к диагональному виду с числами на диагонали.
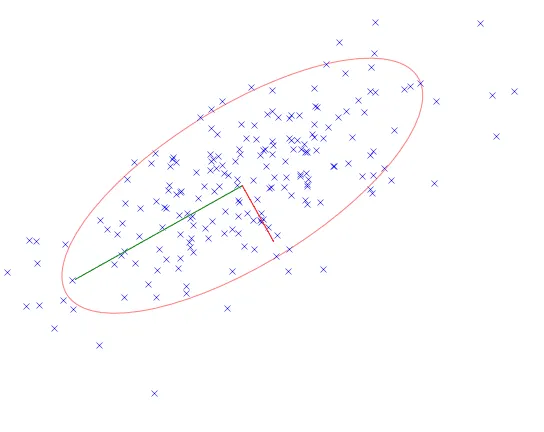
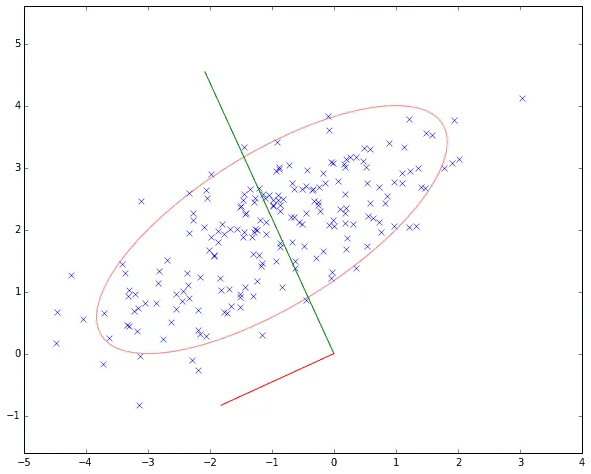
Теперь представим, что наши объекты выбраны из -мерного нормального распределения
где — вектор средних, а — матрица ковариации. Это, в частности, значит, что облако точек представляет из себя нечто вроде эллипсоида в -мерном пространстве с центром .
Предположим, что (все признаки центрированы); тогда оценкой матрицы ковариации признаков является матрица . Допустим, что эта оценка точная, тогда разложение даёт нам аналогичное разложение . Теперь замена координат (с матрицей замены — то есть переход происходит в базис из столбцов матрицы ) даёт нам
Обратите внимание, что и стоят в формуле на непривычных местах, как будто их перепутали, но нет — просто у нас является строкой, а не столбцом.
Итак, если наши данные взяты из многомерного нормального распределения, после перехода к базису из столбцов новые координаты становятся независимыми; вместе с тем это соответствует переходу к главным осям ковариационной матрицы — и геометрически столбцы соответствуют главным осям эллипсоида-облака точек.
Использование SVD: латентные признаки
Запишем
и вспомним самую первую интерпретацию матричного разложения.

Столбцы ортогональны (так как они пропорциональны столбцам ортогональной по столбцам матрицы ) — то есть латентные признаки не коррелированы. При этом, поскольку длина каждого из столбцов равна 1, длины столбцов порпорциональны — а, значит, латентные признаки упорядочены по невозрастанию дисперсии (ведь с точностью до константы оценка дисперсии признака — это квадрат длины вектора его значений).
Заметим, что перед применением SVD признаки лучше центрировать, иначе первая компонента будет указывать в сторону центра масс облака точек (зачем нам это?), а остальные вынуждены будут ей быть ортогональны:
Понижение размерности признакового пространства
Мы уже обсуждали, что это можно получить, построив приближение ранга или, что то же самое, приближённое разложение
для некоторого и желательно небольшого . И тут SVD приходится более чем кстати.
Теорема Эккарта-Янга
Наилучшее по норме Фробениуса приближение ранга — это

Таким образом, если вы хотите получить «самых важных» признаков, то вы можете использовать SVD. Но что это за признаки? Что именно означают эти слова «самые важные»? Давайте обратимся к геометрии, которая, как мы помним, тесно связана с теорией вероятностей:

Если применить SVD к датасету, изображённому на последней картинке, и взять два первых латентных признака, то эллипсоид превратится в эллипс; меньшая из полуосей, похожая на шум, будет забыта, останется две бOльших. Видим: самое важное для SVD — это самое масштабное.
А правда ли у нас получится хорошее приближение с помощью новых признаков? Посчитаем норму разности. Везде ниже и — квадратные ортогональные матрицы; в частности не обязательно квадратная матрица размера .

Аналогичным образом
потому что умножение на ортогональную матрицу не меняет операторную -норму. Таким образом, если сингулярные значения убывают достаточно медленно (например, линейно), то мы вряд ли сможем приблизить исходную матрицу матрицей маленького ранга с очень хорошей точностью.
Как избавиться от иллюзий.
Сгенерируйте матрицу с помощью np.random.rand или np.random.randn. Для какого вы сможете найти матрицу ранга , приближающую исходную с относительной точностью ?
К счастью, в реальных датасетах сингулярные значения убывают достаточно быстро или же нам хватает довольно грубого приближения.
Переход из исходного признакового пространства в новое и обратно
Допустим, мы построили приближённое разложение ранга :
Матрица — это первые столбцов матрицы , и они же первые столбцов матрицы . Таким образом, для перевода объекта в новое признаковое пространство нужно произвести и взять первые столбцов или, что то же самое, .
Теперь пусть задана вектор-строка длины — латентное представление, соответствующего некоторому объекту, то есть одна из строк матрицы . Тогда точно восстановить исходный мы не сможем: ведь равенство не точное, но для приближённого восстановления мы должны произвести .
На что не способно сингулярное разложение
Сингулярное разложение умеет находить дающие самый существенный вклад в дисперсию линейные комбинации признаков, притом некоррелированные; в случае нормально распределённых данных эти направления оказываются главными осями эллипсоида, которым является облако данных. К сожалению, эта суперспособность SVD столь же охотно превращается в слабость, ведь:
- Данные не всегда распределены нормально, они могут обладать сложной геометрией, но SVD будет упрямо искать эллипсоид.
- Самое важное не всегда самое масштабное. Забыть привести признаки к одному масштабу — хороший способ выстрелить себе в ногу при работе с сингулярным разложением.
- Новые признаки не обязаны быть хорошо интерпретируемыми. Линейная комбинация возраста, стажа работы и зарплаты — это не то, что хотелось бы показывать банковскому регулятору.
- Выбросы почти наверняка усложнят вам жизнь, хотя, возможно, SVD поможет вам их увидеть.
Практические кейсы
MNIST и путешествие по латентному пространству
Возьмём большой датасет MNIST, состоящий из чёрно-белых изображений рукописных цифр размера пикселей (его можно загрузить, к примеру, отсюда), вытянем каждое из изображений в вектор, получив тем самым матрицу размера , и применим к этой матрице SVD. Теперь возьмём первые два латентных признака (то есть первые два столбца матрицы ) — получается, что каждая рукописная цифра у нас теперь кодируется вектором из двух чисел. Нарисуем на плоскости точки, соответствующие этим векторам (скажем, по 100 из каждого класса, чтобы хоть что-нибудь было понятно):
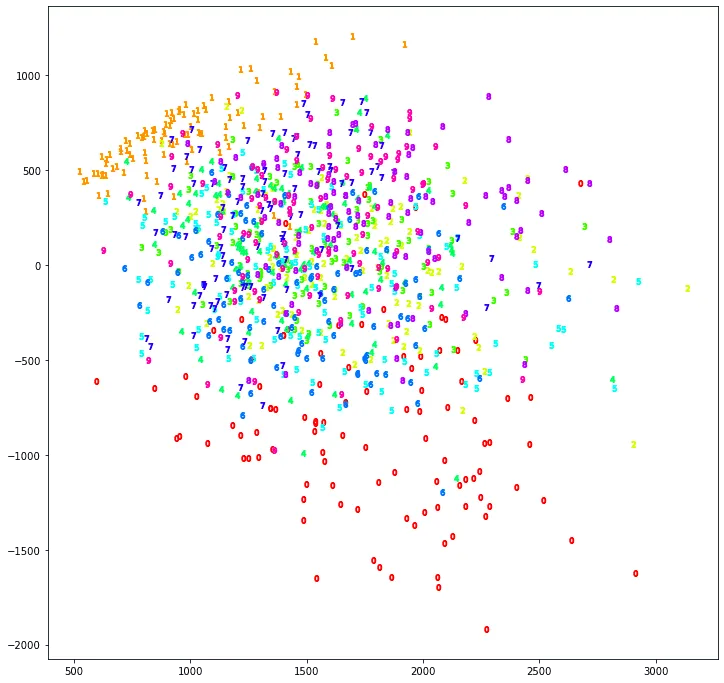
Что же мы видим? Единицы и нули оказались особенными, то есть уже первые два латентных признака хорошо их различают, правда, с середине какая-то каша. А почему? Да потому, что мы забыли центрировать данные. Давайте перед применением SVD вычтем из каждого признака (то есть из каждого пикселя) его среднее по всем картинкам, а потом нарисуем всё заново:
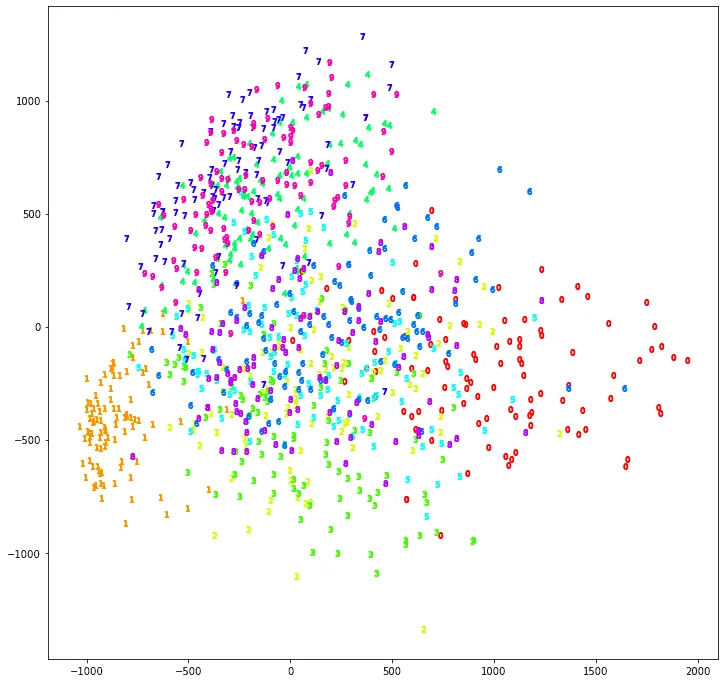
Теперь стало получше: например, семёрки, девятки и четвёрки сгуппировались вместе с другой стороны от восьмёрок и троек (собственно говоря, это отражает тот факт, что рукописные написания семёрок, девяток и четвёрок могут быть похожи друг на друга, так и человек не сразу отличит — а вот с тройкой их спутать намного труднее).
Заметим ещё вот что. В -мерном пространстве наборов пикселей совсем не каждая точка соответствует какой-то рукописной цифре — то, что может приходить из реального мира, лежит на некоторой хитрой поверхности в этом пространстве (если выражаться корректнее, то на подмногообразии). Если же мы попробуем нарисовать «изображения», лежащие на отрезке, соединяющем два изображения цифр, то получим нечто не слишком интересное:

Одно изображение просто наложилось и затем сменило другое — скучно! Но если мы сделаем то же самое в двумерном пространстве, образованном первыми двумя латентными признаками SVD, то мы будем получать, может быть, не совсем реалистичные изображения цифр, но что-то явно из мира рукописных символов:

Контрольный вопрос
Если — вектор-строка длины , отвечающая первой картинке, — второй, а , , — матрицы из сингулярного разложения, то как получить картинку, соответствующую середине отрезка, соединяющего в пространстве двух первых латентных признаков SVD точки и , отвечающие этим картинкам?
Химический состав рек
Посмотрим на небольшой кусок вот этого датасета, который доступен для скачивания нигде (ха-ха), и попробуем что-нибудь понять про химических состав рек европейского союза, а заодно соберём шишки, которые могут попасться при визуализации с помощью SVD.
Конечно, сразу хочется нарисовать все объекты датасета в виде точек на плоскости. Мы знаем, что в этом может помочь SVD — попробуем же! Центрируем признаки — и рисуем:

Ой, что-то пошло не так. Но почему же?! Наверное, надо хотя бы посмотреть на данные...
- Объекты имеют вид «GBPKER0059», «GB20227», «LVV0120100» и так далее — это коды станций, измеряющих состав воды;
- Признаки имеют вид «1985 BOD5», «1985 Chlorophyll a», «1985 Orthophosphates» и так далее — тут указан год измерения и показатель;
- Посмотрев статистики, убеждаемся, что все показатели неотрицательны (то есть уж точно распределены не нормально — но может, и так сработает); при этом почти все элементы нашей матрицы находятся в пределах 1000, но три значения космически огромны, причём в одном столбце «2008 Total oxidised nitrogen» (а строки соответствуют каким-то греческим станциям, с которыми вообще всё странно), и ещё одно тоже очень большое («2005 Total organic carbon (TOC)») — вот они-то и дали нам четыре точки на графике, отличных от начала координат.
Кстати говоря, если космически большие значения, по-видимому, являются результатам поломки, то по поводу четвёртого, не столь злостного, выброса есть подозрение, что это реальные значения. Посмотрев в данные, мы видим, что показатель был измерен на станции Zidlochovice, на реке Srvatka ниже Брно — а, как говорит нам википедия: As a result of water pollution by communal sewage, the reservoir suffered from an extensive amount of cyanobacteria for a long time. Так или иначе, все четыре станции мы уберём, чтобы они не портили нам SVD. - Один из признаков «2002 Kjeldahl Nitrogen» принимает только нулевые значения. Уберём его, чтобы не мешался.
Почистив выбросы в исходных данных, опять центрируем и рисуем:
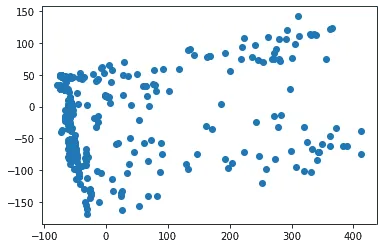
Уже лучше. Попробуем понять, что за вещества внесли вклад в первые два латентных признака. Как это сделать? Латентные признаки — это столбцы матрицы ; линейная алгебра говорит нам, что -й столбец произведения — это линейная комбинация столбцов с коэффициентами из -го столбца . Находим номера самых больших по модулю координат — и оказывается, что первые два латентных признака складываются почти сплошь из насыщения воды кислородом, только за разные годы (первый за более старые, второй за чуть более свежие):
First latent feature
|
Признак |
элемент |
|
2001 Oxygen saturation |
0.27 |
|
2002 Oxygen saturation |
0.27 |
|
2000 Oxygen saturation |
0.26 |
|
2004 Oxygen saturation |
0.26 |
|
|
|
Second latent feature
|
Признак |
элемент |
|
2001 Oxygen saturation |
-0.62 |
|
2002 Oxygen saturation |
-0.49 |
|
2000 Oxygen saturation |
-0.45 |
|
2004 Oxygen saturation |
-0.26 |
|
|
|
Неужели насыщение кислородом действительно так важно? Нет, просто мы не отмасштабировали признаки. Оказывается, что насыщение кислородом имеет на порядок больший масштаб, чем многое другое, и потому забивает все остальные признаки. Тем не менее, мы можем попробовать сделать вывод и из имеющейся картинки. По оси "у" что-то не очень интересное, а по оси "х" видим большой кластер (напомним, это меньшие значения насыщения воды кислородом в начале 2000-х), содержащий, если проверить, примерно три четверти всех точек, и ещё некоторой размазанный шлейф.
Итак, на многих станциях насыщение воды кислородом в начале 2000-х было примерно в одинаковой степени мало — проверив глазами, обнаруживаем, что там просто нули. Поскольку вряд ли это так на самом деле, видимо, стоит сделать вывод, что в первой половине 2000-х насыщение кислородом измерялось из рук вон плохо.
Теперь вдобавок к центрированию поделим каждый признак на его стандартное отклонение и снова нарисуем:
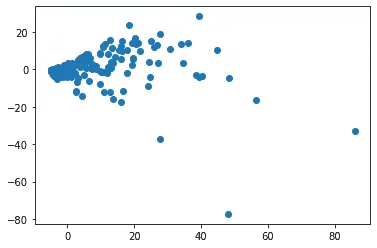
Опять видим тесный кластер. При этом первый латентный признак складывается в основном из «Nitrate» , «pH» и «Dissolved oxygen» за разные годы, все с положительными коэффициентами, а второй — из «Total ammonium», «Total phosphorus» и «Kjeldahl Nitrogen» за разные годы, причём с отрицательными коэффициентами. В частности, справа у нас точки с высоким содержанием нитратов и высокой кислотностью. Среди этих точек:
- Река Тейм, про которую Википедия пишет: The Tame was once one of Britain's dirtiest rivers.
- Река Кёрёш, про которую тоже можно найти вот такую информацию: For some time the municipal government of Kanjiža (to which the mouth of the river belongs) protests about the extreme pollution of the Kereš's water, as it represents the single largest polluter of the Tisa river
- Темза (станция немного выше Лондона).
Что ещё можно было бы сделать? Например, мы можем посмотреть распределения признаков и увидеть, что многие из них далеки от нормальных и в целом выиграли бы от логарифмирования — тогда, возможно, итоговая картинка стала бы красноречивей.
Использование SVD: разделённые представления и рекомендательная система для бедных
Мы уже обсуждали, что, вообще говоря, любое матричное разложение можно с той или иной степенью успеха использовать для построения рекомендательной системы. Основанные на этом модели называются моделями латентных факторов (Latent factor models). В 2006 году SVD-подобный алгоритм даже помог Саймону Фанку (Simon Funk; под этим псевдонимом скрывался Brandyn Webb) занять высокое место на соревновании Netflix Prize.
Подход на чистом SVD
Вернёмся к примеру из пункта 1.3. Пусть вновь объекты нашего датасета соответствуют пользователям интернет-магазина, а признаки — товарам, причём в клетке с индексом записаны рейтинги , которые пользователи ставят товарам. На основе этих данных мы хотим порекомендовать некоторому -му пользователю очередных товаров. Если бы нам были известны для всех индексов товаров , задача не стоила бы выеденного яйца: мы бы просто взяли товаров с максимальными значениями рейтингов. Более того, мы могли бы с помощью матричного разложения построить модель и надеяться, что координаты латентных представлений пользователей и товаров окажутся интерпретируемыми (нет).

А именно, если бы мы знали все , построить отдельные представления для пользователей и для товаров некоторой (подбираемой; это гиперпараметр модели) длины мы могли бы с помощью SVD и приближения из теоремы Эккарта-Янга:
Но на деле матрица обычно разреженная: в ней лишь сравнительно немного известных рейтингов, а в остальных ячейках стоят пропуски. Что же делать?
Наивный вариант — заменить все пропуски нулями (то есть положить, что если пользователь не ставил рейтинг товару, то он ему вдребезги не интересен, что не всегда правдоподобно) или средними по строке/столбцу, после чего сделать SVD и радоваться жизни. В этой ситуации наша приближённая модель предсказывает рейтинг, выставленный -м пользователем -му товару, как скалярное произведение представлений пользователя и товара — то есть -й строки матрицы и -го столбца матрицы
Теперь чтобы порекомендовать n-му пользователю k очередных товаров, мы просто берём n-ю строку матрицы и находим номера её наибольших элементов.
К сожалению, у этого метода есть как минимум две проблемы:
- Пропусков обычно очень много; если их все заменить какими попало значениями, оценка будет очень шумной;
- При таком подходе нет простого способа обновить рекомендации при добавлении новых данных — SVD придётся переучивать заново.
Развиваем идею: как побороть разреженность
К счастью, есть и другой путь. Давайте подумаем: чего вообще мы требуем от матриц и ? По сути нам нужны две вещи:
- ;
- Обе матрицы ортогональны по столбцам.
Последнее можно опустить. Ясной пользы для рекомендательной системы от этого нет; да, это давало бы нам некоррелированность латентных признаков, но мы уже видели, что интерпретируемости это не влечёт. Первое же условие удобно сформулировать в терминах векторов латентных представлений пользователей (обозначим их ; это строки ) и товаров (обозначим их — это строки ). А именно, нам нужно, чтобы скалярное произведение было как можно ближе к для всех пар , для которых нам известно.
Вот именно! Мы можем просто не обращать внимания на неизвестные значения, оптимизируя только по тем клеткам , для которых нам что-то известно:
Но как решить эту оптимизационную задачу? Разумеется, с помощью стохастического градиентного спуска. В базовом варианте мы случайным образом перебираем пары , для которых нам известно, и обновляем координаты векторов и следующим образом:
где — гиперпараметр, отвечающий за темп обучения.
Приятное свойство такого подхода: в нём легко добавлять новые товары/пользователей (дообучаем их векторы, заморозив остальные), а также новые оценки (добавляем в оптимизируемый функционал и проводим дооптимизацию).
Отметим, что в ходе оптимизации мы попеременно осуществляем градиентный спуск, обновляя то , то . Эту идею можно развить следующим образом. Заметим, что при фиксированной матрице задача минимизации по выражения
превращается по сути в обычный метод наименьших квадратов, для которого можно даже выписать «точное» решение (а вы можете это сделать?). Точно так же и при фиксированном легко находится минимум по . Чередуя эти два шага, мы будем сходиться к решению быстрее и надёжнее, чем с помощью SGD. Данный алгоритм носит название Alternating Least Squares (ALS).
Развиваем идею: как ещё усовершенствовать модель
Можно ввести много дополнительных эвристик и предположений, которые уведут нас совсем далеко от старого доброго SVD. Например:
- Рейтинг не всегда является продуктом чистого взаимодействия пользователя с товаром. Бывают товары, которые сами по себе ужасно популярны (скажем, человек купит туалетную бумагу даже если не очень интересуется товарами для дома) или так ужасны, что даже интересующийся данной «латентной категорией» покупатель не станет их высоко оценивать. Это можно промоделировать, добавив к скалярному произведению члены, зависящие только от пользователя и только от товара соответственно:
Тогда наша задача оптимизации примет вид:
- Можно добавлять регуляризационные члены. Например:
- Мы можем не игнорировать неизвестные нам элементы матрицы , а присвоить им нулевые значения и ставить более низкие веса соответствующим слагаемым функции потерь:
где маленькое, если , и большое в противном случае. Это имеет смысл, например, если отсутствие данных в самом деле может быть логично интерпретировать, как отсутствие интереса.
- Можно ввести требования неотрицательности: , . Подробнее об этом в параграфе про неотрицательное матричное разложение.
- Или даже всё это вместе 😄
Контрольный вопрос
Предположим, что каждый рейтинг имеет также временную метку . Можете ли вы придумать, как их использовать?
Вероятностное обличье модели латентных факторов
Вы могли заметить, что задача
подозрительно напоминает задачу наименьших квадратов, и неспроста. В базовой формулировке мы предполагаем, что
Иными словами,
По крайней мере, те из них, которые нам известны. Нахождение и методом максимального правдоподобия как раз и приводит к описанной выше оптимизационной задаче.
Как обычно, мы можем добавить априорную информацию о распределении латентных векторов и . Например, такую:
Расписывая логарифм правдоподобия
и убирая константные члены, которые содержат только сигмы, приводим задачу максимизации логарифма правдоподобия к виду
вполне объясняющему, почему в предыдущем пункте у нас могла появляться L2-регуляризация.
Анализ независимых компонент (ICA)
ICA изначально был придуман для задачи разделения сигналов («blind source separation»). Рассмотрим пример из sklearn
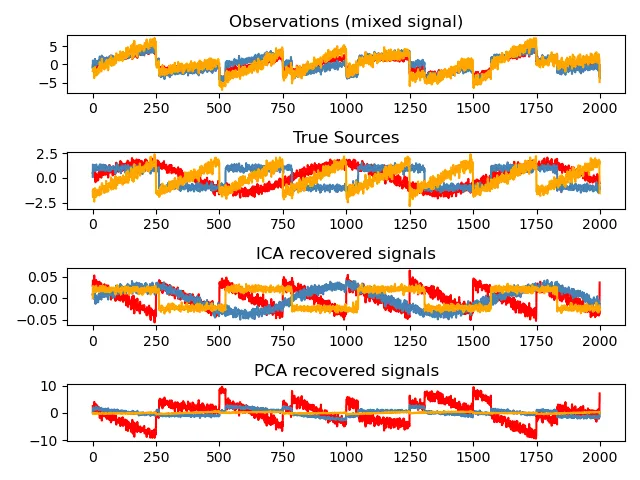
Изначально были три сигнала (красный, рыжий и синий на второй сверху картинке), их смешали, получив три линейных комбинации (на верхней картинке). Теперь попробуем их разделить. Первая мысль, которая нам приходит в голову: воспользуемся SVD (проинтерпретировав моменты времени как объекты, а сигналы из смеси как признаки — то есть взяв матрицу )! Но на нижней картинке мы видим результат, который не радует, но не радует ожидаемо, и вот почему:
- В первый латентный признак SVD старается собрать максимально возможную дисперсию — мы видим, что красный график на нижней картинке действительно ловит самые значительные колебания сигналов из смеси; при этом в третий (рыжий) сигнал уже попадает более или менее случайный шум.
- Если посмотреть на значения исходных сигналов, то они распределены не нормально (распределения значений синего и красного имеют две моды, а у рыжего близко к равномерному), а мы помним, что SVD плохо приспособлено к работе с не гауссовскими данными.
Анализ независимых компонент (ICA) состоит в аппроксимации наблюдаемых признаков линейной смесью латентных, которые являются независимыми как случайные величины.
Замечание. Оригинальная формулировка несколько другая: изначально ICA — это аппроксимация наблюдаемых сигналов линейной смесью некоторого числа независимых сигналов, то есть речь шла о смеси объектов. Описываемые далее методы можно точно также использовать и для разделения смеси объектов, конечно.
Важно, что в данном случае предъявляется требование независимости, а не просто некоррелированности — более сильное, впрочем, труднодостижимое и столь же трудно проверяемое.
Как построить ICA? Путешествие в мир удивительных эвристик
Мы будем излагать алгоритм FastICA по статье его создателей, она же реализована в библиотеке sklearn; в статье вас ждёт гораздо больше подробностей и тонкостей реализации.
Алгоритм базируется на следующем эвристическом соображении: линейная комбинация нескольких независимых негауссовских величин в большей степени гауссовская, чем сами эти величины — довольно смелый вывод из Центральной предельной теоремы. Таким образом, мы будем искать линейную комбинацию исходных признаков, которая была бы в наименьшей степени гауссовской — это и будет первая из независимых компонент. Но как померить близость к нормальности?
Пусть — некоторая (одномерная) случайная величина с плотностью . Рассмотрим её энтропию
Имеет место теорема: гауссовская случайная величина имеет максимальную энтропию среди всех случайных величин с заданной дисперсией. Рассмотрим теперь
где — гауссовская случайная величина с той же дисперсией, что и у . Величина всегда неотрицательна и равна нулю в том случае, если гауссовская. Решая задачу
мы могли бы найти самую негауссовскую линейную комбинацию наших признаков. Проблема в том, что трудно посчитать. Авторы статьи предлагают использовать приближение
где , а неквадратичная функция (в статье предлагаются конкретные варианты). Последующие независимые компоненты можно искать в ортогональном подпространстве (всё-таки они должны быть и некоррелированными).
Подготовка данных для ICA
Перед тем, как строить разложение нужно центрировать данные (вычесть из признаков их средние) и убедиться, что ковариационная матрица признаков является единичной.
Контрольный вопрос: как добиться последнего с помощью линейной замены?
При линейной замене матрица ковариации меняется, как . Осталось вспомнить, что, поскольку матрица ковариации симметричная и положительно определённая, существует линейная замена, для которой . Например, в качестве можно взять (симметричный положительно определённый) квадратный корень из .
Неотрицательное матричное разложение (NMF)
Мотивация: тематическое моделирование
Допустим, что у нас есть датасет, в котором объекты — тексты, признаки — токены (например, слова), а на -м месте написана частота встречаемости -го токена в -м тексте (то есть , где — сколько раз -й токен встретился в -м документе, а — общее число токенов в этом документе).

Приблизим нашу матрицу произведением
Одна из возможных интерпретаций такова. Есть тем:

За этим стоит вполне ясная вероятностная модель:
Вопрос в том, как получить такое разложение. Конечно, чисто технически можно использовать SVD. Но тогда элементы матриц разложения вряд ли будут иметь вероятностный смысл: они же даже не обязаны быть неотрицательными. С другой стороны, если потребовать, чтобы все элементы и были неотрицательными, ситуация исправится.
Определение NMF
Неотрицательное матричное разложение неотрицательной матрицы — это произведение матриц с неотрицательным элементами, наилучшим образом приближающее по норме Фробениуса
Alternating Least Squares (ALS)
ALS — один из популярных методов для решения факторизационных задач. Несмотря на то, что оптимизационная задача в целом не является выпуклой, по отдельности задача поиска каждого из сомножителей является выпуклой и может решаться с помощью привычных нам методов. Таким образом, мы можем чередовать поиск при фиксированном и поиск при фиксированном , итеративно сходясь к итоговому решению:

Заметим, что из-за насильного обнуления элементов будут получаться разреженные матрицы.
Разумеется, можно рассматривать и более сложные функционалы, прибавляя к различные регуляризационные члены, скажем, поощряющие большую разреженность матриц и .