Как обучают языковые модели и почему это сложно

Что такое большая языковая модель?
Большая языковая модель (large language model, LLM) — программа, которая понимает человеческий язык и генерирует на нём тексты. Программу обучают на больших объёмах данных: книгах, статьях, веб-сайтах и других текстовых ресурсах. Эти данные обычно включают широкий круг тем — от научных статей до художественной литературы, чтобы модель могла работать с разными стилями и контекстами.
Примеры больших языковых моделей: GPT-4, Сlaude, Gemini. Они решают самые разные задачи: от ведения диалогов и перевода текста до написания кода.
Как обучают большие языковые модели?
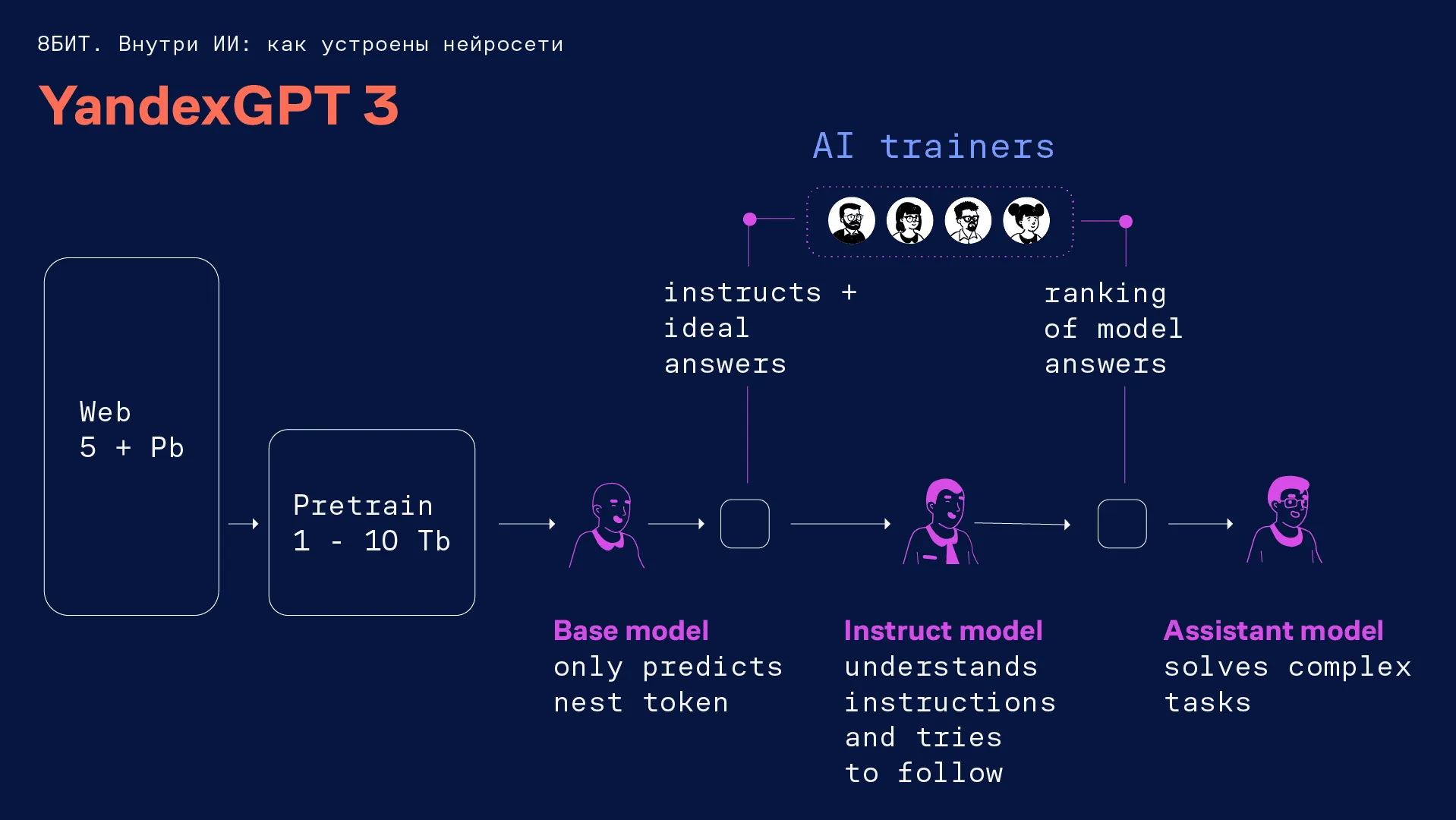
Обучение языковой модели можно разбить на три шага.
Pre-train. На этом шаге в нейросеть загружают большой массив данных о мире.
Здесь мы показываем модели тексты отовсюду, где только сможем найти знания. Всё, чему модель учится на этом шаге, — предсказывать следующее слово. Она запоминает, какие слова употребляются в разных контекстах. Например, модель смотрит на контекст предложения «Я открыл холодильник и обнаружил там...» и думает, что вероятнее там обнаружить: жирафа или торт? Наверное, торт. Примерно такой логикой она пользуется в этот момент.
Ирина Барская, руководитель службы аналитики и исследований в Яндексе
Проблема на этом этапе возникает в качестве данных. В интернете их петабайты, но полезных — мало, потому что много кликбейта, спорных статей, жёлтой прессы. Из-за этого нужно придумать систему фильтрации: как отобрать из всего этого мусора качественные данные и сложить их в обучение.
Это очень важный шаг, который закладывает вообще всю умность модели. Здесь я рекомендую посмотреть статью New York Times в качестве наглядного примера, что происходит на этом шаге. Там модель учится на книгах о Гарри Поттере. LLM пытается продолжить фразу «Гермиона взмахнула палочкой...». Только после 250 итераций она начинает составлять какие-то предложения, но они не имеют никакого отношения к Гермионе и вообще логической структуры. После 500 итераций появляется довольно робастная структура — и только после 30 тысяч итераций это уже неплохой текст в стиле оригинальных книг.
Ирина Барская, руководитель службы аналитики и исследований в Яндексе
Fine-tune. На этой стадии создаются инструкции для языковой модели, она учится понимать язык и отвечать на вопросы. Пока ещё LLM умеет только предсказывать следующее слово. Мы показываем ей, что нужно сделать и как должен выглядеть ответ. Например, если ответ в трёх пунктах, даём ей вариант, который разбит на три буллета.
Для этого нужно составить разнообразные инструкции, но тут возникает другая проблема. Если мы сядем писать их сами, вряд ли сможем написать такие сложные запросы, которые придумал бы учёный, а тем более — идеальные ответы к ним.
OpenAI опубликовали статью, в которой рассказали, как собирают данные на специально отобранных людях. Где-то за полгода они собрали достаточно большой датасет с ними. Они первыми начали пропагандировать: пусть будет меньше данных, но очень качественных. Тогда мы в Яндексе задались вопросом: где нам взять таких людей? Так у нас появился проект найма AI-тренеров.
Ирина Барская, руководитель службы аналитики и исследований в Яндексе
Сейчас в Яндексе больше 500 таких специалистов — это журналисты, редакторы, переводчики, учителя. После подачи заявки на вакансию будущий AI-тренер проходит четыре сложных текста на знание русского языка, фактчекинг, понимание этики и ранжирование. Подробнее о том, как AI-тренер работает с нейросетями, рассказали в статье «Чем занимается AI-тренер и кому подойдёт профессия».
Reinforcement learning. На прошлом шаге мы показывали модели, какой ответ нужен под конкретный запрос. Все эти ответы нужно проверять и улучшать. Нам просто не хватит времени и ресурсов, чтобы собрать миллионы разных вариантов ответов и проверить их. Для этого мы обучаем другую языковую модель оценивать, как наша LLM справляется с задачами. Такая нейросеть называется reward-моделью. Она выступает в роли судьи.
Благодаря reward-модели наша LLM находится в постоянном цикле самообучения и учится оптимизировать ответы. Это даёт возможность добавить десятки процентов качества к работе нейросети.
Ирина Барская, руководитель службы аналитики и исследований в Яндексе
Чек-лист, как обучить языковую модель:
-
Очистить петабайт данных из интернета до нескольких терабайт великолепных текстов, в которых содержатся все знания о мире — от термодинамики до популярных песен. Модель запоминает это и обучается предсказывать следующий токен.
-
Создать инструкции и с помощью AI-тренеров обучить модель следовать им, а также понимать человеческий язык.
-
Обучить reward-модель проверять ответы LLM, чтобы научить её улучшаться.
Можно ли самостоятельно создать и обучить языковую модель?
Одному специалисту или небольшой команде вряд ли под силу создать LLM, потому что нужны большие технические, финансовые и человеческие ресурсы.
Во-первых, для создания даже не очень большой языковой модели — до 35 млрд параметров — нужно собрать кластер GPU, графических процессоров. Кроме того, их придётся обслуживать, а стоимость поддержания очень высокая.
Если посмотреть на существующие нейросети — почти нет опенсорсных моделей, где пять ребят встретились и обучили невероятно классную LLM. Всё это строится вокруг крупных компаний, у которых есть ресурсы.
Ирина Барская, руководитель службы аналитики и исследований в Яндексе
Во-вторых, нужно собрать и обучить команду людей, которые будут писать сложные вопросы и ответы, а также оценивать их. Например, в Яндексе над обучением языковой модели работают более 500 специалистов. Из этого следуют большие затраты на наём и оплату труда.
Но если вы хотите работать с LLM и обучать их, можно присоединиться к командам и компаниям, которые этим занимаются. Например, для обучения языковых моделей нужны следующие специалисты:
-
ML-инженеры.
-
MLOps-инженеры.
-
Аналитики данных.
-
AI-тренеры.
О том, какие задачи они выполняют и каких специалистов всегда не хватает, читайте в нашей статье «Как работает команда обучения нейросетей».