
Компьютерное зрение: как машины учатся видеть

Расскажи, как ты попала в IT?
В школе я хорошо писала сочинения, поэтому пошла на журфак. И к концу учёбы в университете поняла, что умение писать — это замечательно, но журналисту нужны и другие качества, которых у меня нет.
Я писала дипломную работу на тему «Оптимизация медиасайтов для поисковых систем на примере New York Times». Поняла, что эта сфера мне интересна. Однажды в компании, где я работала в контент-службе, я показывала админку ребятам-разработчикам и рассказывала, что там есть. Они мне заявили: «Ты здорово объясняешь! Нам как раз нужен человек, который умеет переводить с бизнесового языка на разработческий и обратно».
Так я стала работать в IT. А потом пришла в Яндекс.
Чем ты занимаешься в области компьютерного зрения?
Я менеджер проектов службы компьютерного зрения. В нашей службе несколько команд. Например, одна занимается генерацией изображений. Результаты её работы можно увидеть в приложении «Шедеврум», которое по итогам 2023 года вошло в мировой топ-3 приложений с генеративным искусственным интеллектом.
Другая команда занимается распознаванием текста. Ещё одна работает над визуальным поиском, который ищет информацию об объекте, представленном на фотографии. Есть и четвёртая команда, она занимается базовыми технологиями: детекцией объектов на фото, улучшением моделей и так далее.
Я занимаюсь визуальным поиском и умной камерой как продуктом, в который стекаются разные технологии службы компьютерного зрения. Умная камера — это всё сразу: и распознавание текста, и визуальный поиск, и детекция изображений. Она есть в Маркете — ищет товары по фото, в Путешествиях — распознаёт достопримечательности и рассказывает о них.
Как вообще умные камеры понимают, что изображено на фото? Как они отличают, например, собачий нос от разлитой туши?
Всё зависит от того, на каких данных обучалась модель. Если она не видела чёрных собачьих носов, а только тушь, то все собачьи носы она, скорее всего, определит как тушь.
У нас была забавная история, когда все женские губы модель распознавала как упаковку. Причём с мужскими губами такого не было. Мы долго не могли понять, в чём проблема. А потом выяснили, что в обучающих данных было много фотографий губной помады. Соответственно, модель научилась, что накрашенные губы — это, скорее всего, упаковка губной помады. Так что отбор данных и их разнообразие — очень важный фактор для обучения модели.
А как работает умная камера?
Всё начинается с того, что пользователь загружает фотографию из галереи или фотографирует то, что ему нужно.
При фотографировании первым в работу вступает трекер. Камера работает не только в момент, когда пользователь нажимает кнопку: она ведёт съёмку и до этого. Задача трекера — выбрать оптимальный для распознавания снимок из всего потока кадров и отсечь смазанные, затемнённые изображения. Это довольно трудоёмкая операция. От трекера зависит, будет ли телефон нагреваться. Поэтому мы постоянно оптимизируем ПО, чтобы оно поглощало как можно меньше ресурсов устройства.
После трекера в дело вступает детектор, который ищет объекты на фотографии и определяет, что он нашёл. Компьютер видит не так, как человек. Мир для него — лишь набор пикселей с обозначением цвета, глубины и резкости каждого пикселя. Соответственно, задача детектора — проанализировать фотографию и выделить то, что может подходить как объект для поиска. Иногда пользователь сам выделяет объект и указывает, что нужно найти. Дальше выделенный объект улетает в специальную модель, которая переделывает этот цифровой портрет в обобщённый вектор.

Интересно, а что такое вектор?
Допустим, мы сфотографировали собаку. У неё есть несколько свойств. Например, она с рыжей шерстью, с длинными ушами и коротким хвостом. Чем больше свойств модель увидит в собаке, тем точнее будет её вектор. Задача модели для каждого конкретного класса объектов — понимать, какие признаки для него наиболее важны, что можно упустить, а что важно отметить, чтобы максимально хорошо понять контекст изображения.
Когда вектор сформирован, модель идёт в индекс с изображениями, у каждого из которых есть свои векторы, и сравнивает их. Таким образом умная камера может сказать пользователю, что это за объект и какие у него свойства.
Обычно модель ищет не по одному индексу, а сразу по нескольким. Если это товар, запускается товарный поиск по всем изображениям из магазинов, о которых знает Яндекс.

Когда наиболее подходящее по вектору изображение найдено, запускаются дополнительные модули поиска. Они ищут информацию об объекте, то есть насыщают результат фактурой. Например, если мы нашли гортензию, то система достаёт из Википедии информацию об этом цветке. Если у нас товарный запрос, то мы обогащаем результат данными о магазинах, где этот товар продаётся.
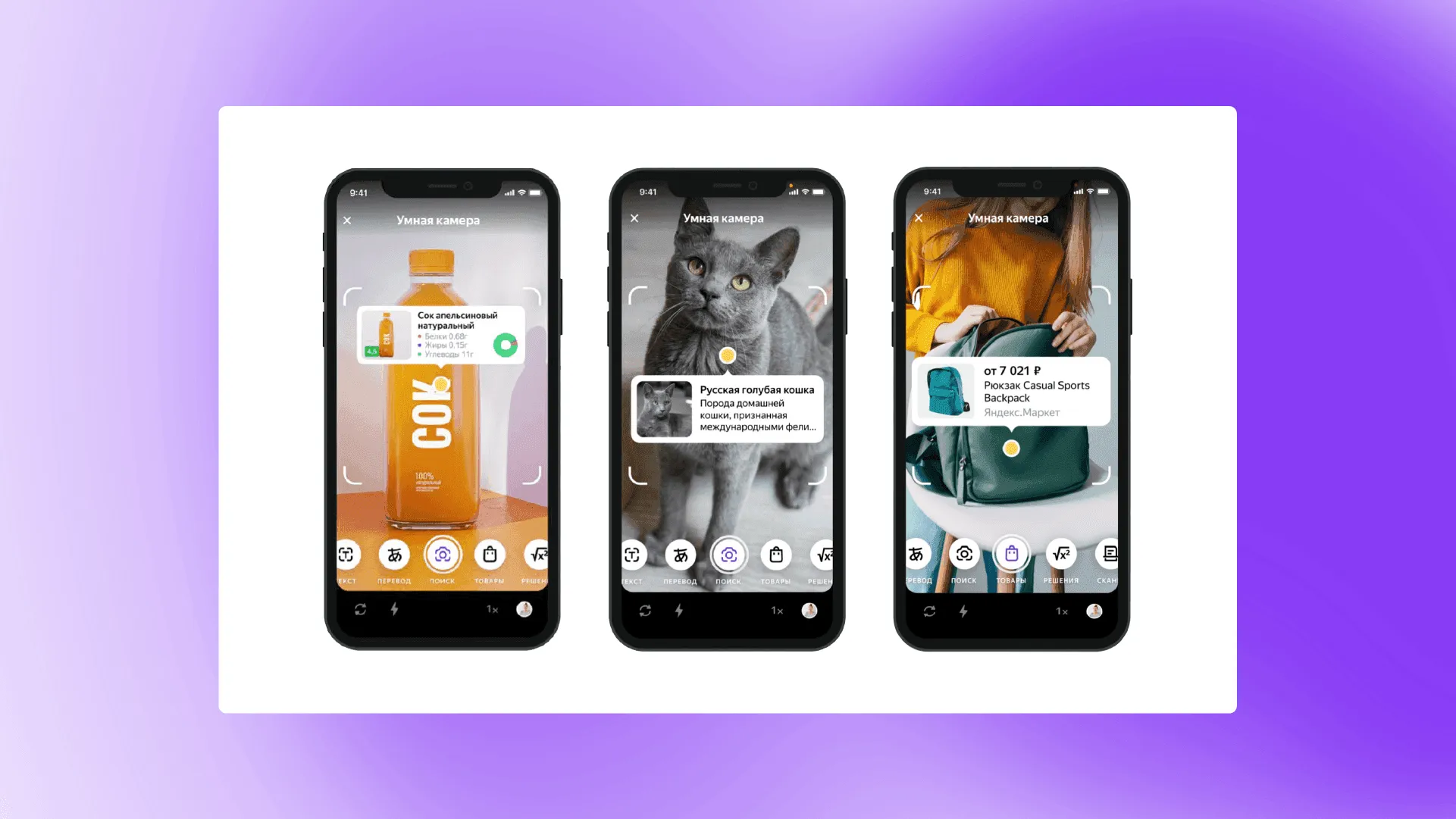
А как камера понимает, что конкретно нужно пользователю?
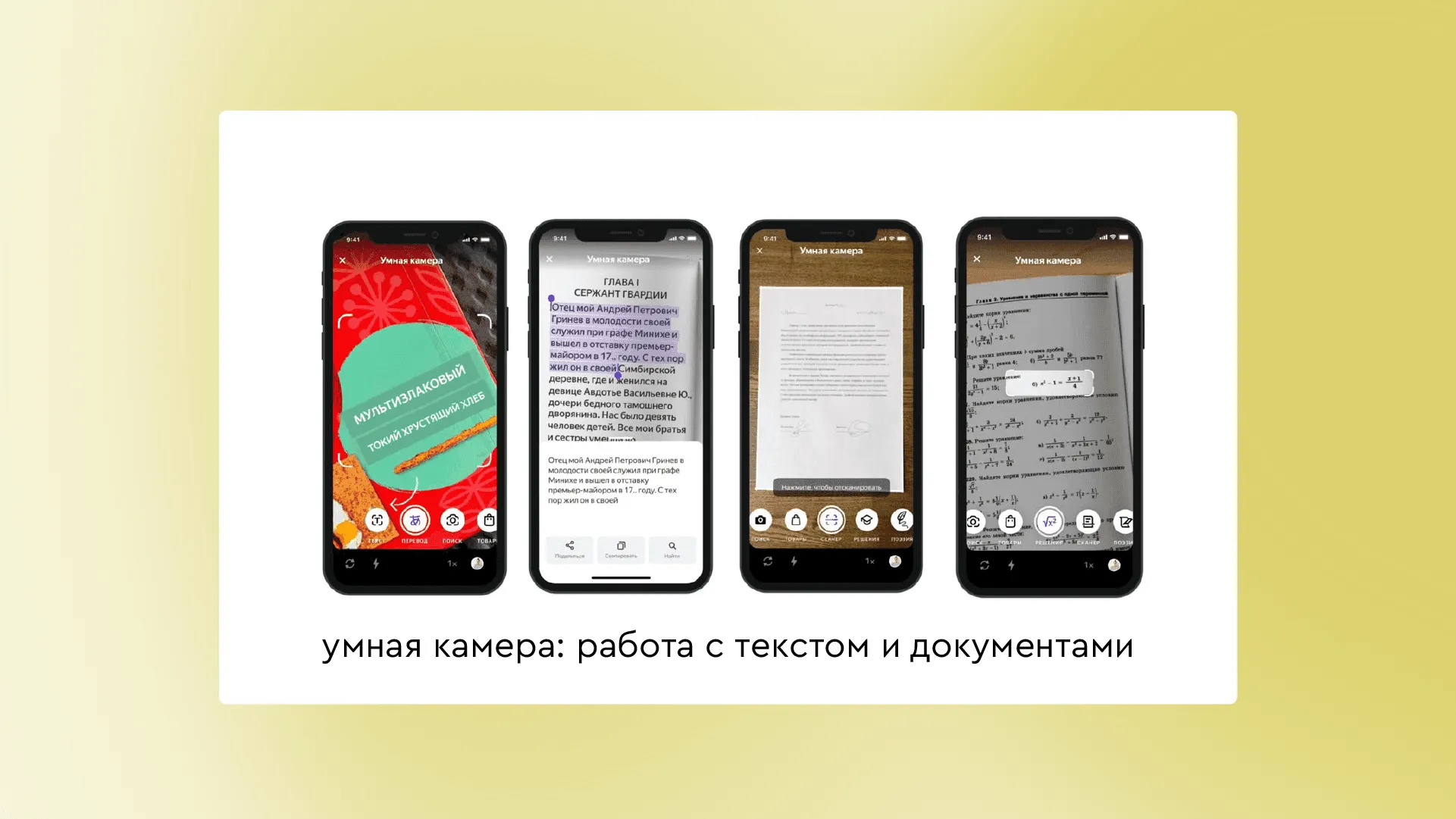
Это зависит от того, в каком режиме был сфотографирован объект. Есть общий поиск — он принесёт пользователю максимум информации об объекте. Есть товарный поиск — в итоге придёт товарная выдача. Ещё у нас есть переводчик, распознавание текста, решения — это мы помогаем школьникам и студентам решить математическую задачу или найти ответ на вопрос по литературе. Есть и сканер, который работает с документами: обрезает границы, повышает качество, может подклеить несколько листов в PDF.
Здорово! А какие объекты камере сложнее всего распознать и почему?
Понять, что на фотографии цветок или здание, нетрудно. Достаточно хорошо обучить модель. А вот создать правильный вектор сложнее. За это отвечает отдельная модель, которую мы постоянно улучшаем.
Например, для товарного поиска очень сложный объект — это телефоны, ноутбуки, телевизоры. Определить вид товара довольно просто, но вот понять, что это за модель, удаётся далеко не всегда. Если по задней стороне Samsung отличить от iPhone проще, то по экрану очень сложно, нужно выискивать косвенные признаки.
Ещё бывают сложности с детекцией, когда один объект перекрывает другой. Например, вам нужно найти стол, а перед ним стоит стул. И модели вырезать стол сложно. Скорее всего, она будет упорно видеть стул и пытаться искать именно его.
В каждом конкретном классе объектов есть свои особенности, с которыми надо учиться работать. Одновременно улучшать поиск по всем классам трудно, поэтому приходится определять приоритеты.
А умная камера может работать на любом железе? Есть у неё какие-то требования к смартфону?
Наша цель — добиться, чтобы она хорошо работала на любом железе. Естественно, на топовых смартфонах она работает быстрее, потому что тот же трекер ест довольно много ресурсов. Но основной объём работы идёт на серверах. Для умной камеры важнее качество интернета, чтобы устройство смогло быстрее отправить данные и принять выдачу с наших серверов.
Над чем сейчас бьются разработчики в области распознавания?
Основное движение сейчас вокруг GPT. И у визуального поиска развитие тоже идёт в эту сторону. Недавно Google выпустил свою модель для работы с изображениями — Gemini. У OpenAI тоже есть своё решение — GPT Vision. Эти модели умеют принимать на вход картинку и текст.
Раньше визуальный поиск находил похожие изображения и выдавал массив информации в надежде, что пользователь сам найдёт в ней нужное. А языковая модель, обогащённая визуальным вводом, может получить текстовый запрос к картинке и выдать конкретный результат. Например, мы можем отправить фотографию фикуса в поиск и спросить, как ухаживать за этим растением. Умная камера определит, что это фикус бенджамина, и сообщит, сколько раз его надо поливать и какие удобрения нужны.
Это простой кейс, но мы надеемся, что в будущем визуальный поиск сможет решать и сложные проблемы. Например, мы сфотографируем мультиварку и спросим, что с ней делать: она постоянно пищит. Или сфотографируем продукты в холодильнике и спросим, что можно из них приготовить.
Думаю, что на горизонте одного-двух лет визуальный поиск ждёт масштабная революция: люди смогут по щелчку пальцев решать вопросы, которые сейчас занимают много времени.
А в какие отрасли можно будет внедрить технологии компьютерного зрения?
Самое широкое применение они могут получить в ретейле, здравоохранении, производстве.
В ретейле компьютерное зрение будет помогать в складских системах учёта, когда по фотографии стеллажа система будет понимать, какие товары в наличии. Кроме того, в магазине можно будет набрать корзину товаров, а в зоне оплаты сканер определит, что взял покупатель, и при помощи детектора лица спишет деньги с привязанного счёта.

В здравоохранении компьютерное зрение будет заниматься анализом, например, рентгеновских снимков. Уже сейчас обученные модели могут видеть болезни, которые не замечают профессиональные рентгенологи, хотя это пока чисто случайные явления. Но в любом случае медицинские модели будут хорошими диагностами. Плюс можно научить модели следить за пожилыми людьми. Всё это вопросы не столь отдалённого будущего.
В производстве компьютерное зрение сможет заниматься контролем качества. То, что сейчас проверяют глазами, скорее всего, в ближайшем будущем станет сферой ответственности моделек.
Если хотите делать будущее, присмотритесь к работе в области компьютерного зрения!



