
Разработка фичи: как эффективно пройти путь от идеи до реализации

Запустить новую фичу на пару сотен тысяч пользователей — вполне посильная задача, если спланировать весь путь разработки. На примере Яндекс Go пройдём путь разработки фичи от идеи до реализации.
Придумываем идею и формулируем продуктовую гипотезу
Любое изменение приложения начинается с идеи о том, что в нём можно что-то улучшить. В нашем случае это была идея добавить в профиль водителя Яндекс Go его фотографию. Выглядит просто: водитель фотографируется, фото где-то сохраняется, и пассажир видит его во время заказа.
Но одной идеи недостаточно, её нужно подкреплять аргументами, отвечая на вопрос «Зачем нужно делать эту фичу?». Продуктовая гипотеза формулируется так: «Если мы сделаем (описываем идею), то получим (ожидаемый результат), потому что (объяснение)».
Гипотез может быть несколько. В нашем случае они звучали следующим образом:
1. Если мы добавим фото водителя, то пассажиры будут оставлять больше чаевых, потому что получат более личный опыт общения с водителем, познакомятся с ним.
2. Если мы добавим фото водителя, то у пассажира вырастет ощущение безопасности из-за повышения осведомлённости о водителе.
Оцениваем сроки и сложность разработки
Важно хотя бы примерно понимать, сколько времени понадобится на разработку новой фичи и как можно упростить процесс. Вы наверняка знаете, что в разработке существует важная метрика: time to market. Чтобы понять, как её оптимизировать, верхнеуровнево прописываем механику новой фичи. И затем смотрим, можно ли реализовать её частично и насколько сильно изменения затронут архитектуру приложения.
Архитектурно в Go есть два приложения: для водителей и для пассажиров. В качестве прототипа мы выбрали ручную загрузку фотографий водителей в базу данных, чтобы не затрагивать изменениями приложение для водителей Яндекс Pro. При этом приложение для пассажиров необходимо будет изменить и сделать в нём отображение фото водителя.
Разрабатываем прототип с минимальной функциональностью
Прототип (MVP, minimal viable product) — это решение с минимальной функциональностью, которое позволяет быстро протестировать гипотезу и понять, взлетит ли идея.
Проекты, подобные нашему, делаются примерно два месяца, а нам благодаря прототипу удалось за две недели проверить гипотезу и убедиться, что фото водителя влияет на продуктовые метрики. Значит, идея стоящая — можно заниматься ею дальше и переходить к разработке архитектуры. Если бы идея не взлетела, мы сэкономили бы полтора месяца труда целой команды разработчиков, что тоже было бы хорошо.
Выбираем архитектуру
Следующий вопрос, который встаёт перед разработчиками, — это выбор архитектуры и способа реализации новой фичи. У нас было три варианта: писать в монолит, в готовый микросервис для водителей или разработать новый микросервис.
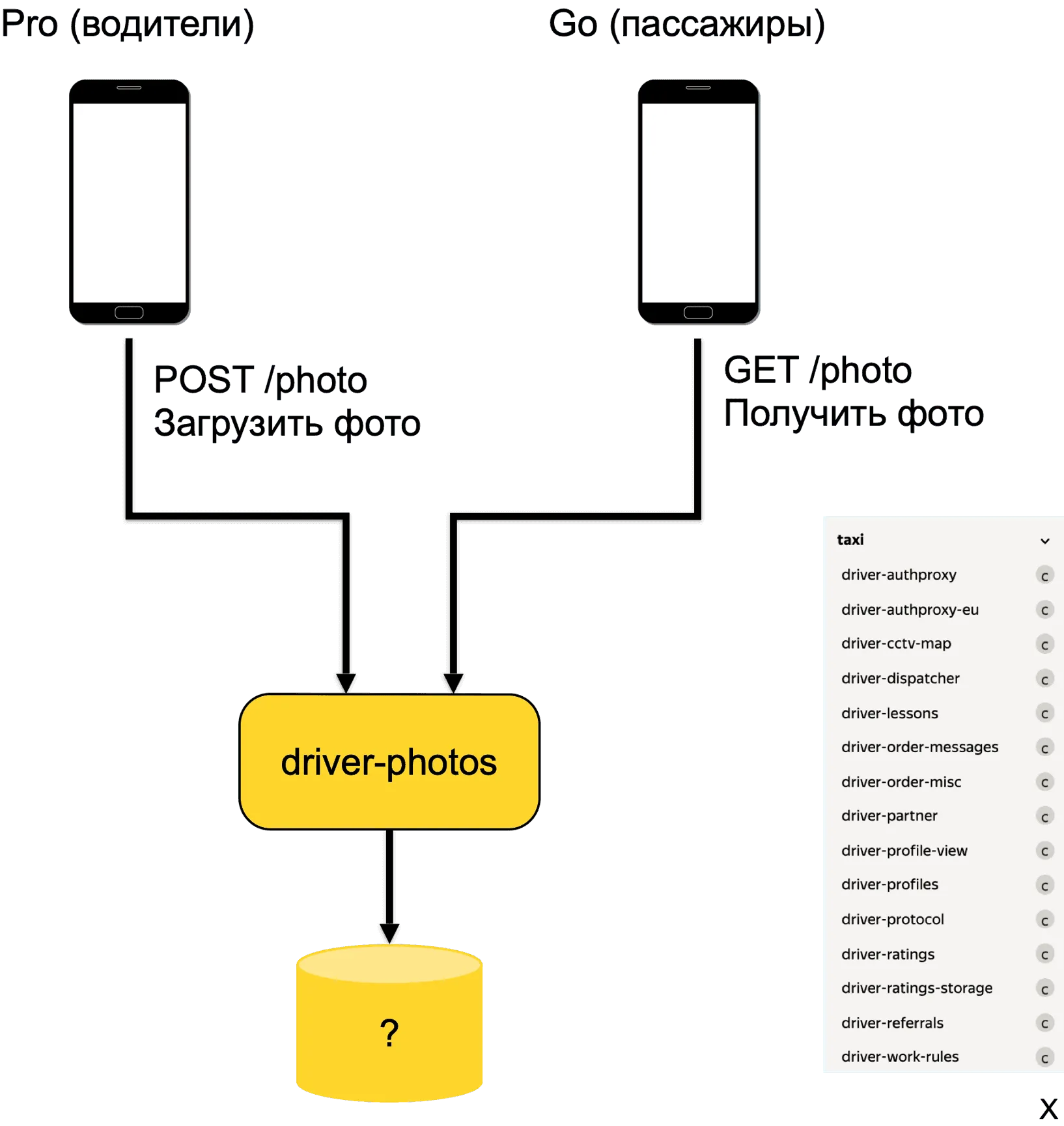
При добавлении в монолит мы столкнулись бы со следующими проблемами: долгий деплой, большая кодовая база, сложность прогнозирования нагрузки и масштабирования, долгая компиляция.
Готовый микросервис для водителей не подходил, потому что грозил долгой раскаткой, ведь не все водители быстро обновляют свои приложения. Поэтому мы выбрали третий вариант: новый микросервис.
Выбираем базу данных
На что обратить внимание при выборе БД для микросервиса:
Требования технологического радара (whitelist) — это список разрешённых технологий, языков и средств разработки, которые использует компания или команда.
Поддержка инфраструктуры. Завести новую БД не получится, если администраторы и инфраструктура не готовы работать с ней.
Fit for purpose. Смотрите, насколько выбранная база данных соответствует вашим целям.
Выбираем язык
На чём писать код фичи — ещё один трудный вопрос, который решается аналогично выбору БД. Например, обязательно нужно учитывать опыт команды: эксперименты с незнакомыми языками вряд ли будут удачными. Исходя из списка разрешенных языков и опыта команды, мы остановились на Python и C++.
Нужно учитывать, куда будет приходиться основная нагрузка: на CPU или на IO-ресурсы. Python хорош для проверки гипотез, но менее производителен. В то же время в нём есть библиотеки для работы с изображениями (pillow, face_recognition) и вспомогательные сервисы с тестами. В С++ тоже можно делать какую-то обработку изображений, накладывать фильтры и другие эффекты, но это труднее. Поэтому мы выбрали Python.
Оптимизируем разработку
Перед началом разработки стоит предусмотреть некоторые дополнительные моменты:
1. Уже на этапе планирования архитектуры договоритесь с командой фронтенда, как вы будете обмениваться данными. Мы используем формальную спецификацию интерфейса OpenAPI.
2. Подумайте о расширяемости интерфейса, но без over-engineering, чтобы не тратить слишком много времени и сил на вещи, которые могут не пригодиться. Ищите баланс.
3. Если есть возможность, используйте кодогенерацию, это ускоряет разработку.
4. Обязательно проводите ревью архитектуры. Это что-то вроде код-ревью, но на раннем этапе. Почему это важно? Существует правило 1-10-100: чем раньше обнаружена ошибка, тем дешевле обходится её исправление. В работающем приложении переписывать код дольше, дороже и труднее, чем на этапе согласования архитектуры.
И только после всех этих действий можно писать код. Подробно останавливаться на нём не будем, только напомним, что обязательно нужно проводить код-ревью, использовать линтеры и применять техники непрерывной интеграции CI, писать и исполнять тесты на постоянной основе.
Тестируем
Тестирование — важный этап разработки, который позволяет свести вероятность наличия ошибок к минимуму. Поэтому приложения обязательно прогоняют через все типы тестов.
Наверняка вам знакома пирамида тестирования, которая отображает фазы тестирования и характеризует количество тестов.
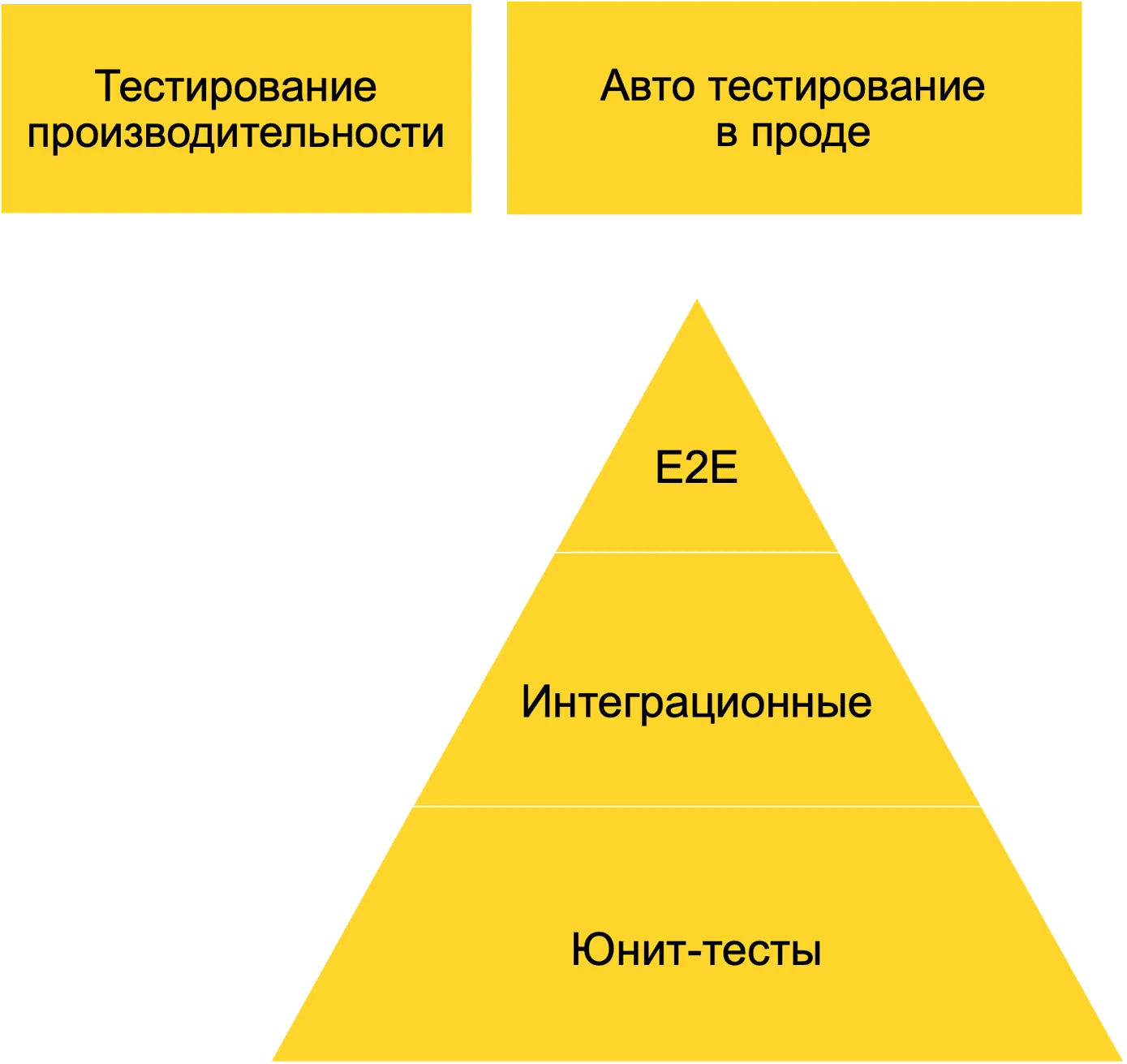
Основание пирамиды — модульные (юнит-) тесты. Их много, они простые и быстрые, но они тестируют небольшие кусочки кода, как правило, алгоритмы.
Чуть выше находится уровень интеграционных тестов — тесты на интерфейсы API в микросервисах, например. Этих тестов меньше в сравнении с юнит-тестами, зато при выполнении они затрагивают больше кода, поскольку тестируют более широкие сценарии, характерные для бизнес-специфики приложения. Такие тесты пишутся на базе фреймворков и библиотек тестирования, часто используются mock-объекты и mock-серверы.
На верхнем уровне находятся системные (E2E, end-to-end) тесты, которые тестируют готовую к эксплуатации систему так, как это делал бы конечный пользователь: нажимают на кнопки в интерфейсе, проверяют результаты на экране и т. п. Часто такие тесты бывают ручными. На этом этапе проверяются конечные сценарии, которыми пользуются клиенты приложения. E2E тесты сложно поддерживать, потому что бизнес-логика часто меняется, и тесты тоже приходится переписывать.
Отдельно стоит выделить ещё два вида тестов:
Тестирование производительности, в которое входят стресс-тестирование, нагрузочное и другие виды тестирования.
Тестирование в продакшне. Такое редко, но тоже встречается. Например, в Яндекс Go робот заказывает машину у робота, они виртуально перемещаются и производят оплату. Так тестом покрывается самый главный сценарий приложения.
Раскатываем на пользователей
Когда фича протестирована со всех сторон, можно предлагать её пользователям. Но здесь необходимо сделать несколько шагов.
В первую очередь считаем, сколько экземпляров сервиса нужно развернуть, чтобы выдержать нагрузку. Для ответа нужно изучить результаты тестов производительности.
Далее проверяем, какие нужны шаги для выкатывания фичи. Чаще всего используется постепенная выкатка (canary deployment), так как пользовательские сценарии уникальны и люди могут найти какие-то ошибки.
Убеждаемся, что выкатка релиза не обрушит тайминги, время ответов, количество ошибок и другие метрики.
И, наконец, даже если всё проверили, не включаем фичу сразу для всех, а используем фича-тоглы (feature toggles), задействуя узкий сегмент пользователей. Небольшую часть пользователей легче откатить в случае обнаружения проблем. С помощью фича-тоглов можно провести A/B-тесты и проверить гипотезы.
Внедряем мониторинг
Фичу раскатили, но её целостность и стабильность работы необходимо отслеживать. Для этого настраиваем мониторинг для отслеживания важных метрик и алерты, которые будут предупреждать о сбоях.
Ресурсные метрики: затраты на CPU и оперативную память, скорость чтения с диска, количество операций с БД и тайминги.
Продуктовые метрики: размер чаевых водителю, частота вызова такси пользователем и другие характеристики, свидетельствующие о том, что фича полезна.
Обязательно внедряем процесс устранения и анализа ошибок. Одним из лучших инструментов для этого являются логи микросервисов. Они позволяют проследить путь запроса пользователя по всей распределенной микросервисной системе и выяснить, что именно привело к нештатному поведению. Но устранением ошибки дело не ограничивается. Дополнительно проводится post-mortem анализ — процесс, на котором разбирается ошибка и ищется решение (а не виновный!), способное предотвратить повторение ошибки в будущем.
Пишем документацию
Фича написана и доступна пользователям. Но это ещё не конец истории: необходимо позаботиться о документации. Что сюда входит?
Самодокументируемый код — одно из правил хорошего тона для разработчиков. Код должен читаться как текст на английском языке, а для этого важно соблюдать code style.
Архитектура: сохраняйте информацию в системе контроля версий, чтобы можно было посмотреть, как шло обсуждение и каков конечный итог.
Текстовая документация на вики или в описании классов и методов нужна при написании API для других разработчиков.
Пользовательская документация пишется для заказчика или широкого круга лиц, которые будут пользоваться решением. Как правило, её готовят технические писатели вместе с разработчиками.
Готовимся к сценариям, которые невозможно предусмотреть
В ходе использования фичи могут возникать ситуации, которые не предусмотрели на этапе разработки и проектирования. К этому тоже нужно быть готовым. Например, у нас возникла история с загрузкой водителями случайных изображений вместо своего фото. Как можно было решить проблему?
Вариант 1. Модерация фото при загрузке. Это усложняет процессы и увеличивает время обработки запросов.
Вариант 2. При загрузке фото создаётся объект с заданием, который отправляется в очередь заданий (в ашем случае — в краудсорсинговый сервис Толока). Толокеры проверяют объект, следуя ряду правил, и сообщают, соответствует ли фотография этим правилам.
Второе решение позволило быстро и без серьёзных расходов сообщить водителям, что нужно загружать в профиль реальные фотографии.
В продуктовой разработке нет решений, подходящих под все случаи. Многое зависит от культуры компании, её масштаба и направленности. Но базово вектор разработки фич выглядит так, как описано выше.
Научиться писать код, вести разработку продукта, взаимодействовать с разными командами и тестировать приложения вы можете в Школе бэкенд-разработки Академии Яндекса. Прямо сейчас в Школе проходит открытый лекторий, к которому можно присоединиться в любой момент. Знакомьтесь с программой и присоединяйтесь к другим начинающим разработчикам, чтобы вместе работать над реальными проектами.
