Как студенты CS Центра создавали сервис для анализа аудитории блогеров

CS Центр — это совместная инициатива Школы анализа данных Яндекса, Computer Science клуба и JetBrains. Слушатели центра проходят курсы по анализу данных, разработке программного обеспечения или компьютерным наукам и применяют полученные знания на практике. Студенты Computer Science Center Александра Елисеева, Павел Чижов и Шамиль Мустафаев рассказали о сервисе SMM Meter для анализа аудитории блогеров, который они сделали под руководством Ивана Бибилова из Яндекса во время весенней практики.
Идея проекта и постановка задачи
Это приложение должно помочь рекламодателям и блогерам оценить активность аудитории, вероятность накрутки и тип взаимодействия с подписчиками того или иного аккаунта. За счёт этого они смогут оценить эффективность рекламы, уличить подозрительных блогеров в накрутке или сравнить себя с конкурентами.
Проект задумывался как приложение-помощник для рекламодателей и блогеров в социальных сетях — мы сосредоточились на Instagram. Перед нами стояли такие задачи:
— разобраться с данными, доступными через официальный API;
— собрать выборку блогеров;
— подготовить гипотезы и проверить их, составить как можно больше описательных статистик для наших данных;
— провести кластерный анализ, проверить его применимость;
— выявить основные показатели и интервалы для них;
— создать прототип интерфейса приложения.
Как мы решали задачу
Над проектом мы работали удаленно. Такой формат изначально оговаривался как основной, а ухудшение эпидемиологической ситуации сделало личные встречи еще менее возможными. Для организации взаимодействия внутри команды мы использовали сервис Яндекс.Коннект: писали вики с релевантной для проекта информацией и с помощью трекера четко распределяли задачи между собой. Общались мы в основном в чате в Телеграме и периодически созванивались в Дискорде или Зуме, чтобы обсудить текущую ситуацию и определить наиболее целесообразные действия на ближайшее будущее.
Сначала мы изучили похожие сервисы. Среди них можно выделить те, которые используют официальный Instagram Graph API и, следовательно, предоставляют только те данные, которые можно получить через него. Например, российский сервис LiveDune предоставляет много инструментов для отслеживания статистики собственного аккаунта, но об аккаунтах конкурентов информации гораздо меньше.
Существуют и сервисы, предоставляющие аналитику чужих аккаунтов. Например, HypeAuditor, помимо инструментов для ведения собственной маркетинговой кампании, позволяет получить подробный отчет об аудитории любого аккаунта в Instagram или YouTube (а с недавних пор и в TikTok). Однако для того чтобы получить такую информацию, официальных данных Instagram недостаточно.
Затем мы изучили существующие возможности для получения данных об аккаунтах и остановились на использовании Instagram Graph API. С его помощью можно получить количественные показатели, касающиеся профиля (количество подписок и подписчиков, число постов) и постов (количество комментариев и лайков). При этом не получится проверить гипотезы, которые требуют доступа к аккаунтам подписчиков или тех, кто оставляет лайки и комментарии.
Для нашей выборки блогеров по совету руководителя мы собрали 816 профилей на различных страницах Википедии, связанных с российскими медийными личностями.
Важным шагом в работе над нашим проектом стало изучение различных метрик, которые позволяют проверить активность аудитории аккаунта или указывают на возможность неестественного роста активности или накрутки. Мы проводили эксперименты: смотрели на различные графики (boxplot, гистограмма) и основные описательные статистики всех найденных метрик на нашей выборке, решали, насколько они содержательные и какие значения можно считать хорошими, а какие нет.
В итоге мы остановились на нескольких метриках.
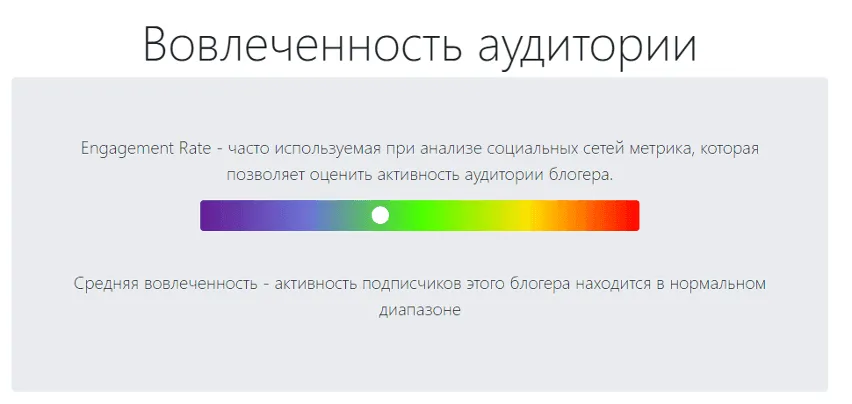
Engagement Rate (ER) — показатель вовлеченности. Он рассчитывается по такой формуле:
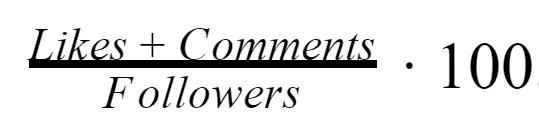
Boxplot на наших данных выглядит так:
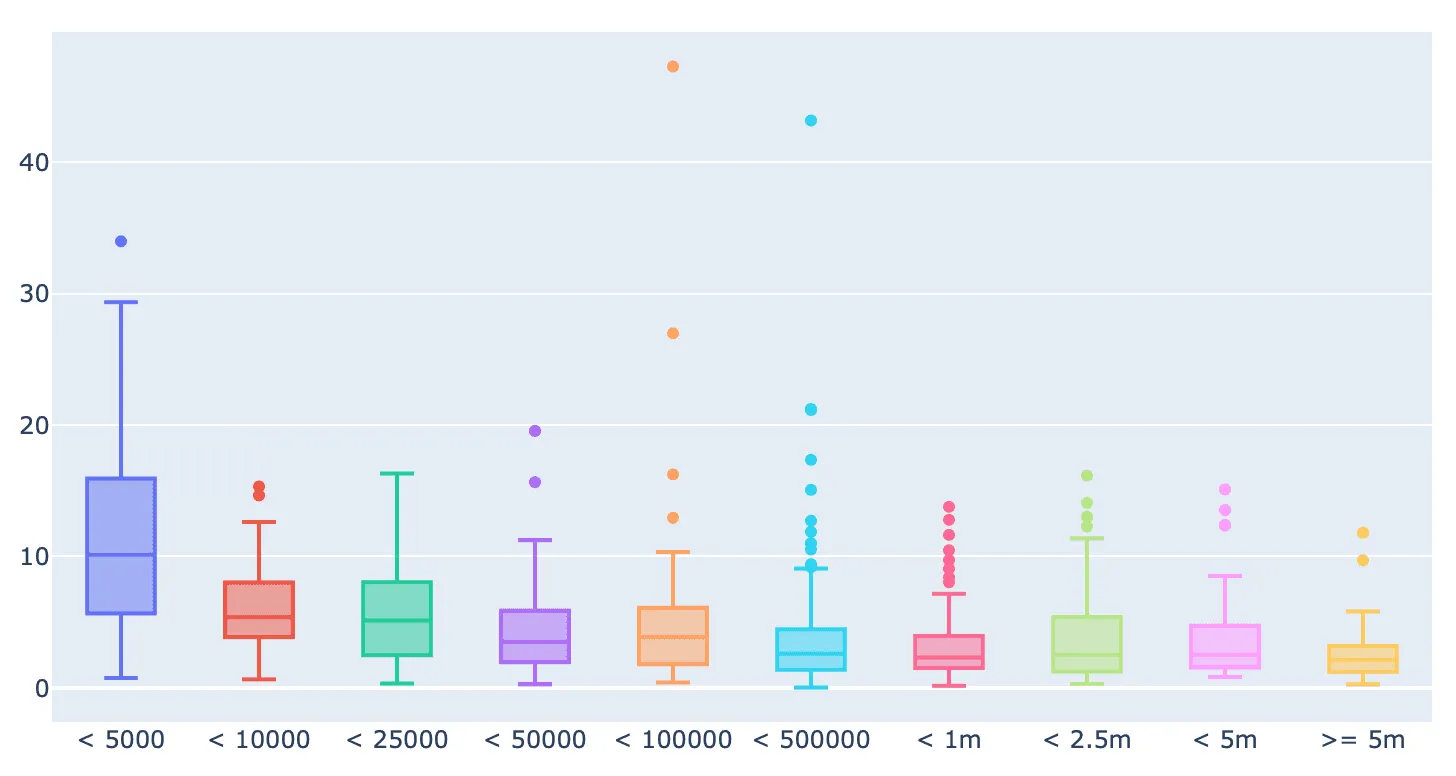
На графике видно, что значения ER для профилей с разным количеством подписчиков заметно отличаются друг от друга. Мы проанализировали профили с аномально высоким ER и заметили, что не всегда большие значения означают что-то плохое, например, у рэпера Хаски ER равен 42.5%. Можно было бы подозревать его в накрутке, но у него в профиле всего четыре поста, и три из них сделаны более года назад. В связи с этим мы решили рассчитывать ER по несколько другой формуле, которая позволяет более адекватно оценивать аккаунты со старыми постами и аккаунты, у которых мало постов:
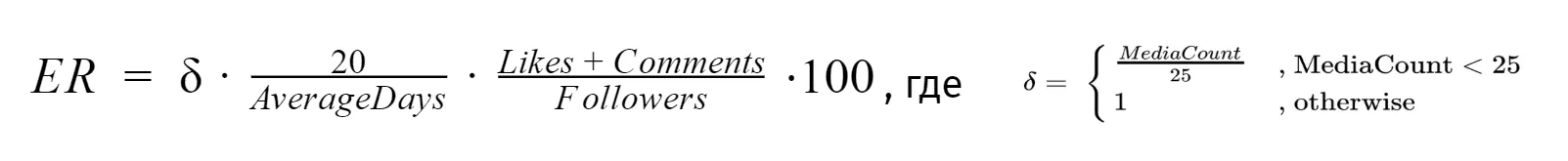
При использовании этого способа подсчёта значения Engagement Rate не сильно различаются у профилей с разным количеством подписчиков, а у профилей с небольшим количеством постов и у профилей со старыми постами (например, у страниц памяти) ER не такой высокий.
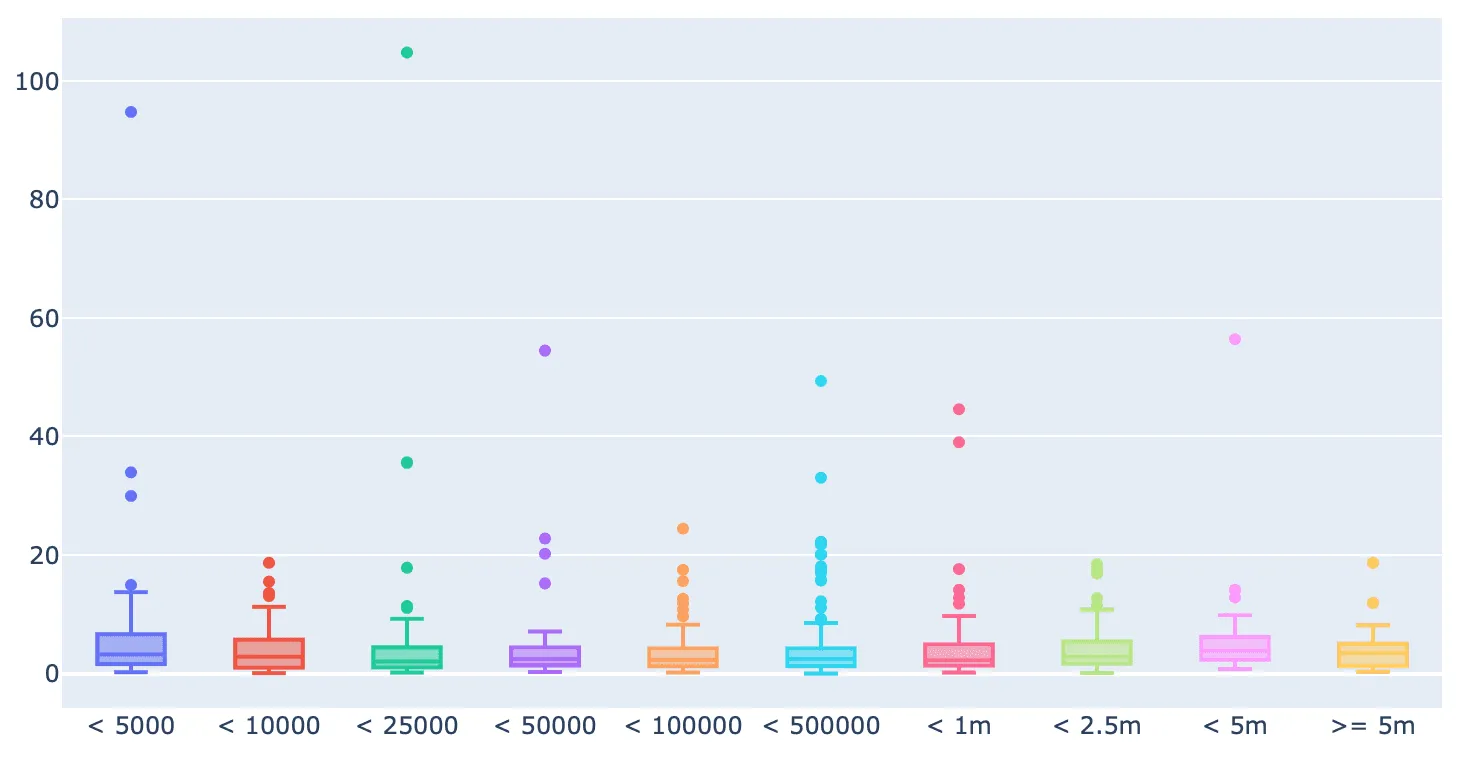
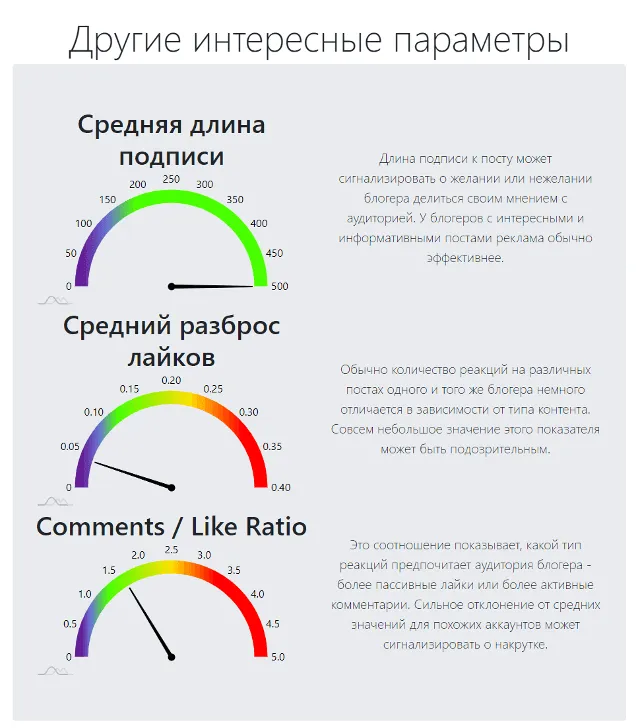
Средний разброс количества лайков. Чтобы значение показателя находилось в диапазоне от 0 до 1 и чтобы корректно обработать очень большие или очень маленькие значения, мы рассчитывали этот показатель как стандартное отклонение логарифма количества лайков под постами, деленное на логарифм среднего количества лайков.
При органической активности подписчиков количество лайков под публикациями блогера немного различается в зависимости от типа поста. Слишком большие или, наоборот, слишком маленькие значения этого показателя могут говорить о накрутках.
Caption Length — средняя длина подписи к посту. Этот показатель может сигнализировать о желании или нежелании блогера выражать свое мнение или делиться информацией. У блогеров с более длинными подписями реклама обычно эффективнее.
Comments/Likes Ratio — отношение количества комментариев к количеству лайков. Этот показатель говорит о том, какой способ взаимодействия предпочитает аудитория аккаунта: более пассивный (лайки) или более активный (комментарии).
Мы хотели научиться оценивать степень необычности значений некоторых важных показателей (например, тех, которые могут сигнализировать о накрутках). Изучив различные методы обнаружения выбросов в данных, мы решили остановиться на z-score.
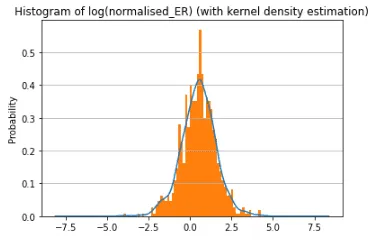
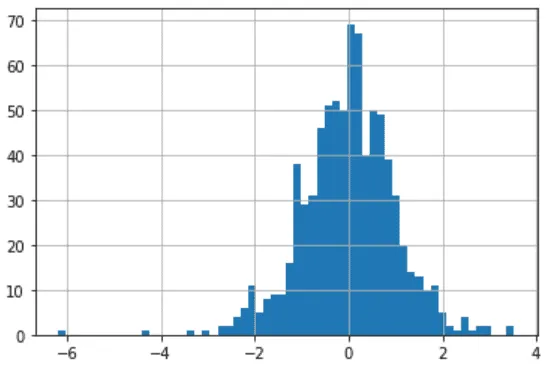
Чтобы сам z-score был распределен нормально, обычно его рассчитывают для нормально распределенных данных. Мы рассмотрели гистограмму логарифмов Engagement Rate и обнаружили, что она как раз очень напоминает нормальное распределение.
Трудности и особенности работы над проектом
В ходе работы мы столкнулись с несколькими сложностями:
1. Ограниченность официального API. Для углублённых исследований официальный Graph API не годится: можно получить только количественные показатели и только для бизнес-аккаунтов.
К официальному API довольно сложно подключиться. Необходимо иметь работающую https-веб-страницу, на которую можно делать редирект после авторизации для получения долгосрочного токена доступа — то есть обычный localhost не подойдёт. Для решения этой проблемы мы развернули дополнительное приложение на Heroku.
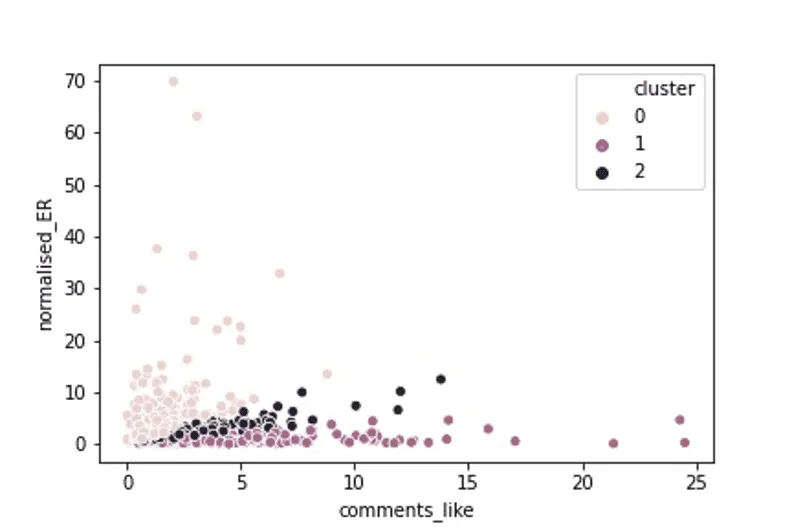
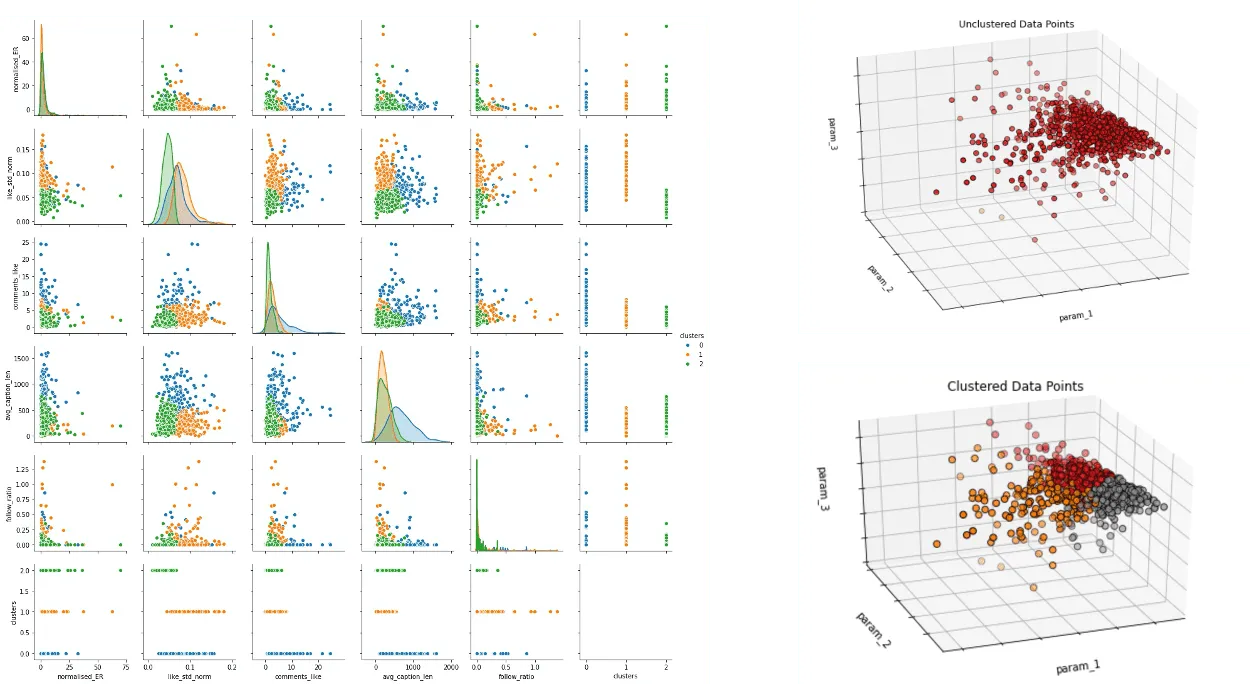
2. Проблемы с выявлением зависимостей при помощи кластерного анализа. Кластеризация не дала нам существенных результатов. Применив алгоритмы K-Means и K-Medoids, мы не смогли получить интерпретируемый результат. Как видно на графике, наша выборка не разбивается на четкие кластеры — возможно, это связано с её небольшим размером.
3. Потеря смысла интегральной формулы. Изначально в наших планах было создание общей формулы, в которой будет сумма нескольких нормированных показателей (возможно, с весовыми коэффициентами). Однако в процессе анализа выяснилось, что показатели слишком разнородные и серьезные отклонения их значений в разные стороны, говорящие о подозрительной активности в профиле, в сумме будут давать 0. Например, пользователь с миллионом подписчиков, 5 лайками и 15 комментариями к постам будет иметь низкий ER и высокий Comments/Likes Ratio, а в таком случае информативность теряется.
Итоговый результат
В нашем веб-приложении наглядно представляются показатели, рассчитанные для выбранного блогера, и это представление подкреплено кратким пояснением значения каждого показателя. Прототип приложения мы написали с помощью фреймворка Flask, а для интерактивных графиков использовался JavaScript.

Несмотря на интересные результаты, наше приложение пока рано считать конкурентоспособным. Для того чтобы привести приложение в рабочий режим на Facebook, нужно пройти процедуру верификации, которую мы пока, увы, не пройдем. Наши показатели менее информативны, чем могли бы быть: например, мы не проверяем, не являются ли подписчики ботами. Чтобы добыть такую информацию, нужно использовать неофициальные инструменты, а также подключать высокие мощности и продвинутые хранилища данных, что требует значительных материальных вложений в проект.
В ходе практики мы больше сосредоточились на Instagram, однако есть смысл расшириться и на YouTube, у которого тоже есть официальный API. У нас возникли некоторые гипотезы о метаданных в видео, поэтому было бы интересно аналогичным образом исследовать активность на этом видеохостинге.