Проект по распознаванию бирок на одежде от студентов CS центра

Студенты CS центра Ирина Ахмадеева и Никита Одиноких разработали приложение, которое распознаёт символы на бирках для стирки. Они рассказали, как выбрали проект, как самостоятельно составляли базу данных бирок на одежде и когда собираются закончить работу над приложением.
Computer Science Center — это совместный проект Школы анализа данных Яндекса, JetBrains и Computer Science клуба. В Санкт-Петербурге и Новосибирске организованы очные вечерние курсы по математике и программированию, для жителей других городов доступно платное заочное отделение.
История проекта
Каждый семестр студенты CS центра работают над инженерными или исследовательскими проектами под руководством сотрудников IT-компаний или учёных. Среди других проектов проект по распознаванию бирок зацепил нас тем, что, помимо машинного обучения, мы могли прокачаться в программировании на Android. Понравилось и то, что у этой идеи есть реальное применение, оно может сделать жизнь чуть проще.
Нашей практикой руководил Дмитрий Кузнецов, который занимается мобильным приложением Яндекс. Музыки, поэтому хорошо разбирается в Android-разработке. Во время создания приложения Дима всегда приходил на помощь в трудную минуту, объяснял непонятные концепты, эффективно организовывал работу. Мы встречались раз в неделю, чтобы обсудить прогресс и трудности. Так, нам было трудно разобраться со свободным перемещением фотографии по экрану — он рассказал нам о разных подходах, среди которых мы выбрали самый удобный.
Распознавание бирок
Приложение работает очень просто. Это камера со специальной областью для ярлыка и кнопкой «Распознать», которая отправляет нужный фрагмент изображения для определения в нейросеть. В результате пользователь видит текст с расшифровкой значков с ярлыка и степенью уверенности нейросети в правильности ответа.

К защите проекта весной 2019 была готова только первая версия, а над улучшениями мы работали летом. Теперь приложение будет искать значки по всей области экрана, распознавать ярлыки в реальном времени и давать по поводу стирки расширенные рекомендации.
Как разрабатывали и учили приложение
У нас был опыт в программировании и машинном обучении, но никто из нас раньше не писал для Android. Поэтому пришлось начинать с азов. Даже самые простые вещи поначалу давались с трудом. Но при помощи упорного труда и советов руководителя проекта у нас всё получилось.
В основе лежит сверточная нейронная сетка. Для того, чтобы её обучить, пришлось самим стать немного экспертами в значках, которые сообщают, как нужно ухаживать за одеждой.
Раньше мы знали только два типа значков: про стирку и про глажку, а остальные считали неважными. Чтобы собрать обучающую выборку, нам пришлось вручную перебрать всю одежду в гардеробе. Так мы получили почти 980 размеченных значков. Интересно, что почти всю одежду нельзя отбеливать, поэтому в обучающей выборке почти не было примеров, разрешающих отбеливание. Для того, чтобы охватить всё разнообразие обозначений, кроме реальных данных пришлось использовать сгенерированные — это еще 4330 значков.
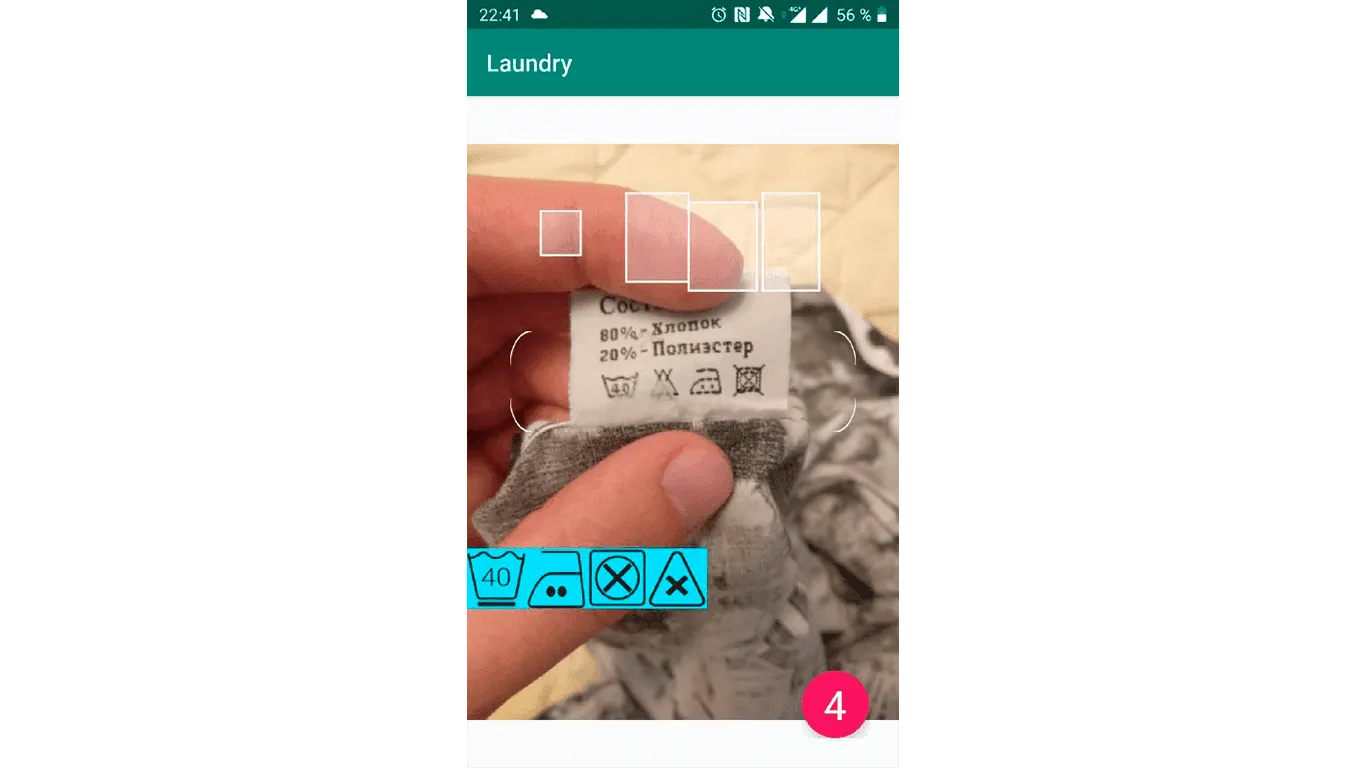
Изначально у нас был классификатор, из-за которого пользователю приходилось размещать значки в специальном окошке, чтобы мы могли их подать на вход нейронной сети. Теперь наша сетка умеет делать сегментацию изображения, и можно подавать на вход всю картинку, главное, чтобы на ней была бирка.
Что нас вдохновило на создание приложения
У нас была идея создать приложение, которое помогает обычным людям понять, что значат специализированные символы: это ведь не только значки на бирках, но и указатели на дорогах, и, на самом деле, много что еще. Мы хотели сделать переводчик с языка символов, и частично реализовали исходную идею в нашем приложении.
Сначала этот проект воспринимался как небольшая задачка, которую можно попробовать быстро решить для своего удовольствия, немного потренироваться в новых для себя областях и сделать приложение для себя.
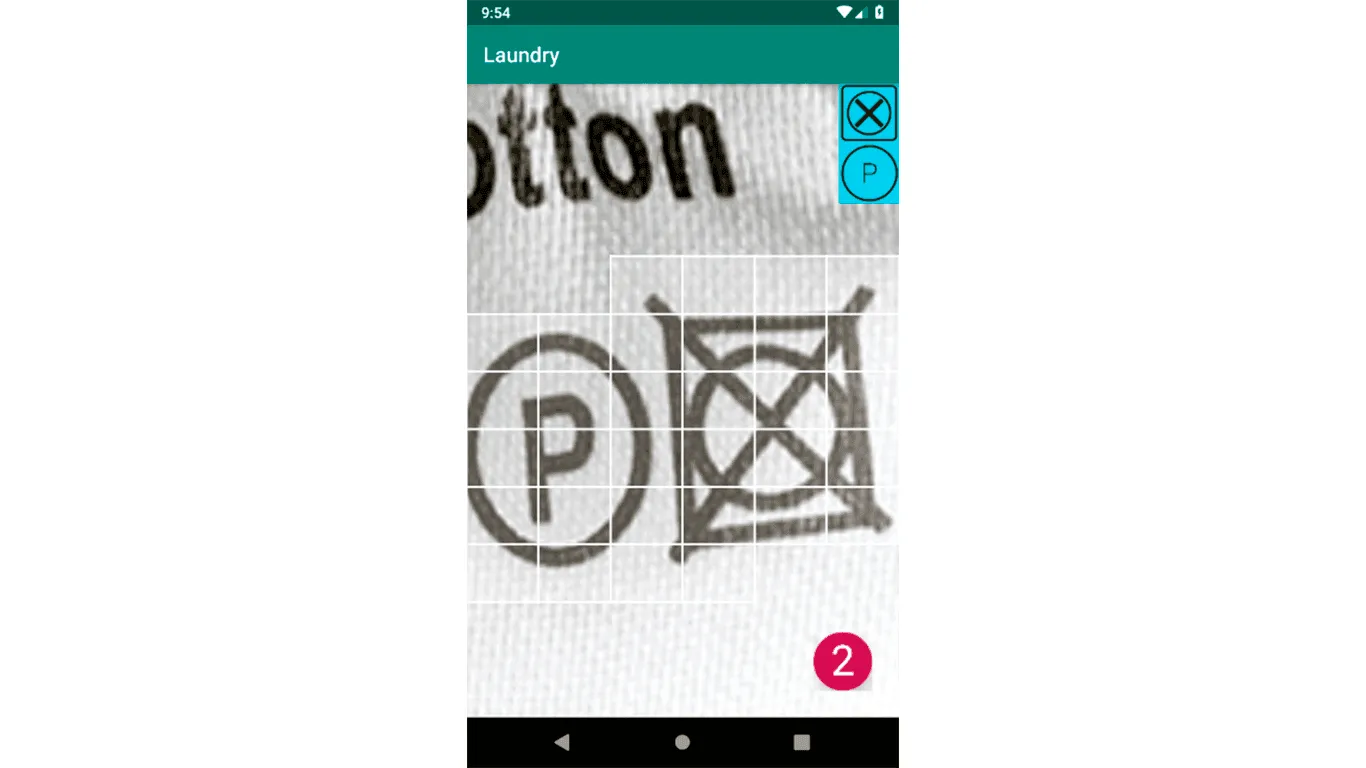
Однако теперь, спустя полгода после начала работы над проектом, он стал для нас чем-то бóльшим. Нам хочется довести его до состояния, когда его будет трудно отличить от приложения, созданного крупной компанией. Мы хотим, чтобы наше приложение помогало людям в повседневной жизни, будем продолжать его поддерживать после релиза. Возможно, в будущем мы начнём и новые проекты, относящиеся к другим областям человеческой жизни. А пока мы продолжаем разработку, исправляем баги и реализуем новые идеи, которые появляются каждую неделю. Скоро планируется релиз новой версии, но и сейчас уже видны явные улучшения в выделении значков на экране и в скорости распознавания. Такими темпами мы можем получить законченную версию уже к концу ноября.