

Языковые модели генерируются с помощью простых алгоритмов обучения, разработанных человеком, а вот механизмы, порождаемые этими алгоритмами, довольно сложные и не всегда понятны человеку.
В Antropic опубликовали исследование о том, как модель Claude 3.5 Haiku думает при ответе на запросы разного формата. Разработчики проанализировали, как происходит взаимодействие между информационными блоками внутри модели во время поиска ответа. В итоге, при помощи граф атрибуции исследователи проследили путь и логику размышлений языковой модели.
Что такое графы атрибуции?
Вкратце — это как карта нейронных связей в мозге, только для искусственного интеллекта. По сути это инструмент, который выявляет, какие нейроны модели активируются при обработке конкретного запроса и как они взаимодействуют между собой. Эти нейроны можно сравнить с абстрактными понятиями, которые модель использует для понимания и генерации текста. А связи между ними отражают причинно-следственные зависимости между этими понятиями.
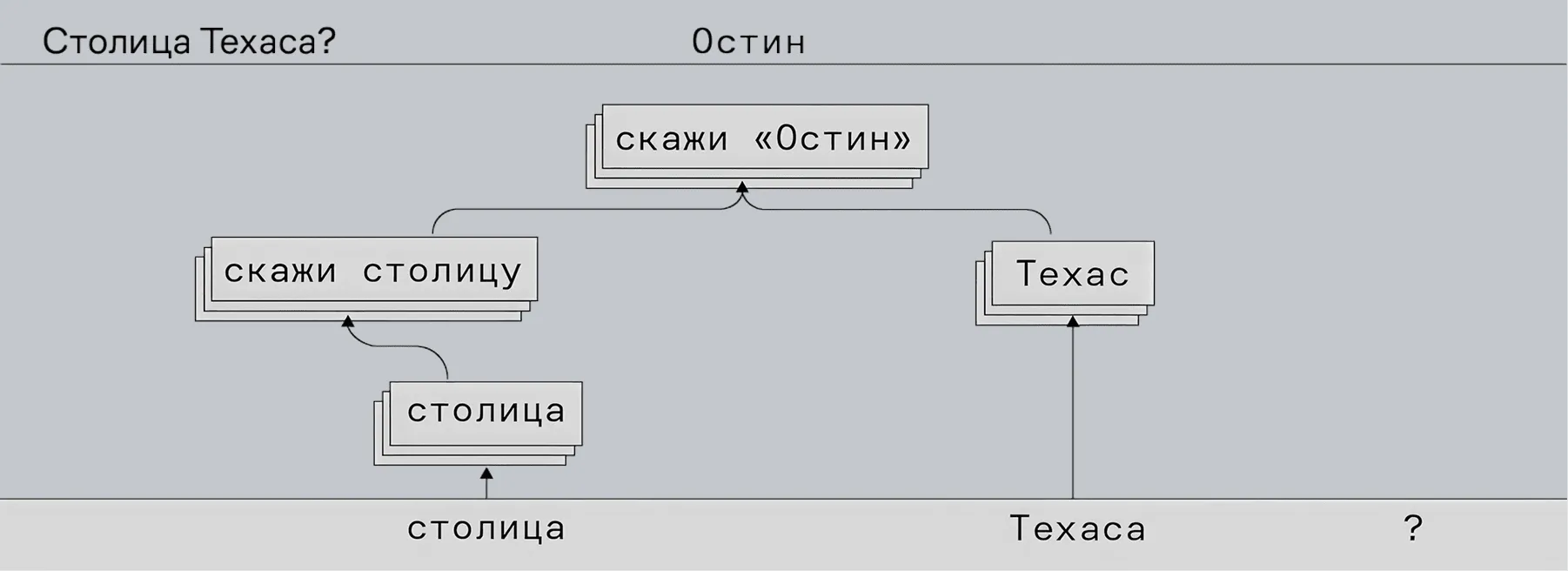
Цепочка выше построена на примере запроса «столица Техаса?» и помогает проследить последовательность промежуточных шагов, используемых моделью для преобразования конкретного входного запроса в выходной ответ.
Погодите, всё так просто?
На самом деле не совсем.
Чтобы построить такой граф атрибуции и понять общий принцип работы языковой модели, разработчики заменили часть алгоритма на более интерпретируемую версию — «локальную модель замены». Она позволяет отслеживать активацию нейронов, их взаимодействие и влияние на итоговый результат.
Так, исследователи смогли проследить промежуточные этапы «размышлений». На основе этих результатов и сформировались графы атрибуции.
Зачем нужна локальная модель замены?
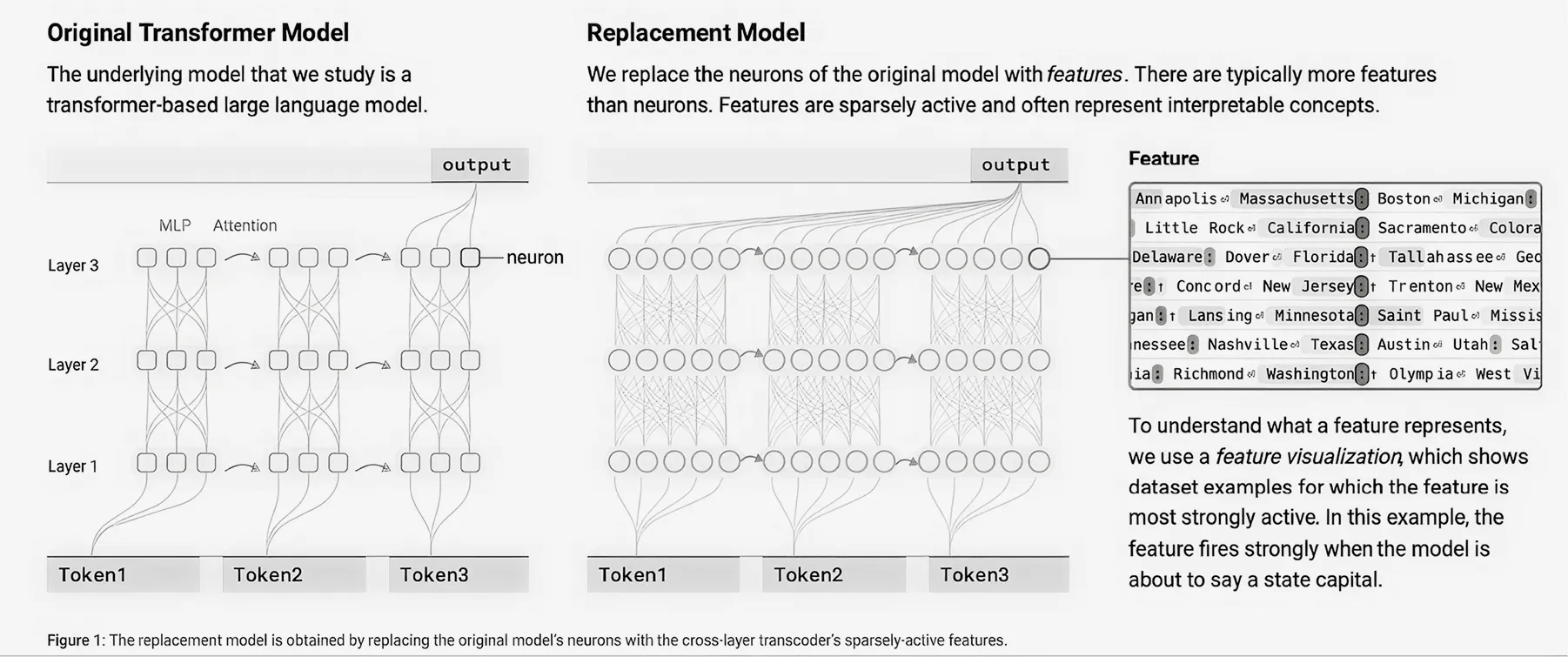
Основной фокус исследования Antropic был на языковых моделях на основе трансформаторов, которые принимают последовательности токенов — например, слова, фрагменты слов и специальные символы — и выводят новые токены по одному за раз.
Эти модели включают в себя два фундаментальных компонента:
-
Уровни MLP
"многослойного персептрона", которые обрабатывают информацию в пределах каждой позиции токена, используя наборы нейронов; -
Уровни внимания
которые перемещают информацию между позициями токена.
Нейроны внутри таких нейросетей многозначны, то есть выполняют множество различных функций. Из-за этого было сложно выявить, какая именно информация используется оригинальной моделью при поиске ответа на запрос.
Локальная модель замены основана на архитектуре многоуровневого транскодера (CLT), который обучен заменять MLP-нейроны основной модели более понятными компонентами.
Компоненты часто представляют собой понятные концепции, варьирующиеся от низкоуровневых (например, конкретные слова или фразы) до высокоуровневых (например, настроения, планы и логические шаги). Изучив визуализацию компонента, в котором активируется нейрон, мы можем присвоить каждому из компонентов более «человеческое» значение.
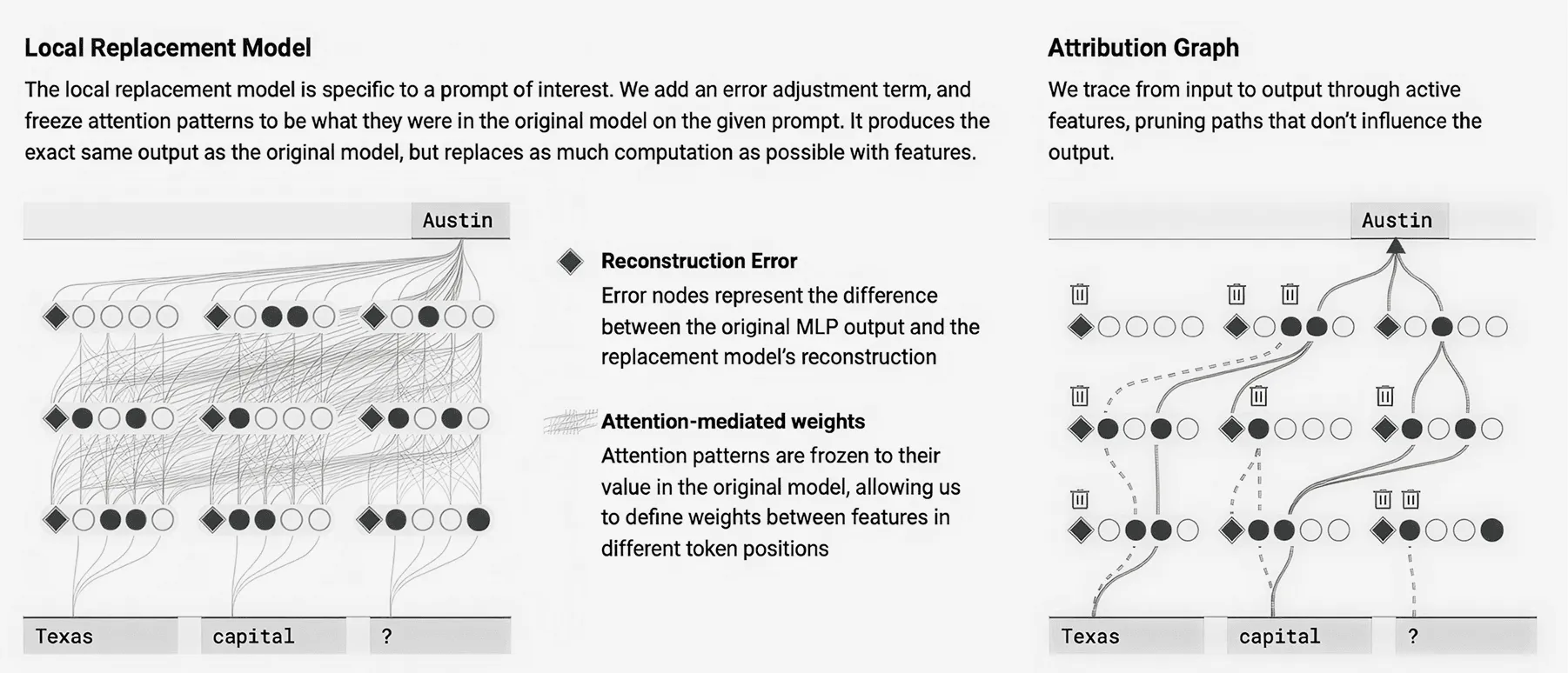
В любом запросе между замещающей и оригинальной моделями есть несоответствия. Чтобы выявить их, у замещающей модели есть узлы ошибок. Включение таких узлов дает более четкое представление о том, насколько велика разница между локальной моделью и изначальной.
Поскольку графы атрибуции основаны на замещающей модели, они предоставляют лишь гипотезы о механизмах, действующих в исходной модели. И эти гипотезы требуют дополнительной проверки.
Можно ли самому построить графы атрибуции?
Объяснение мышления нейросети — это новая область исследований, и визуальные инструменты почти любого рода пока доступны только техническим специалистам, в том числе и графы атрибуции.
Прямо сейчас можно использовать OpenAI API с logprobs. Этот инструмент показывает вероятности, с которыми модель выбирала каждое слово. А значит, можно посмотреть, где модель была уверена, а где — сомневалась.
Ещё, если научиться запускать модели локально, можно использовать LIT (Language Interpretability Tool) от Google. инструмент интерактивно показывает, как работает модель, например: какие слова влияют на результат и как распределяется внимание.
Всё это — интерпретируемость!
Чем активнее развиваются ИИ, тем актуальнее становится область исследований, в которой пытаются заглянуть в «мышление» нейросети и объяснить её поведение человеку. Это называется интерпретируемость или объяснение вывода модели.
А графы атрибуции — мощный инструмент для изучения и понимания сложных языковых моделей. Хотя метод ещё не идеален и требует доработок, он открывает новые горизонты в области интерпретации ИИ.
Понимание внутренних механизмов работы моделей поможет:
-
повысить доверие к ИИ и обеспечить прозрачность его решений.
-
находить и предотвращать нежелательные поведения, такие как галлюцинации или выполнение вредоносных инструкций.
-
улучшить архитектуру и обучение моделей, делая их более надёжными и эффективными.
Помимо визуализации, есть много других способов заглянуть внутрь нейросетей, например алгоритмы, объясняющие влияние входных данных на вывод (SHAP, LIME), соотношение внутренних признаков при выдаче результата (Feature attribution) и пошаговое объяснение модели своих рассуждений (Chain-of-thought). Последний из них, кстати, доступен всем пользователям по промту.