Ключевые вопросы параграфа
- Как установить и подключить библиотеку
pandas? - Что такое объекты
SeriesиDataFrameи как с ними работать? - Как фильтровать, сортировать и агрегировать данные?
- Как создавать и изменять табличные структуры в pandas?
- Как визуализировать табличные данные с помощью библиотеки
matplotlib?
Как установить и подключить библиотеку pandas
Для работы с табличными структурами данных в Python чаще всего используют библиотеку pandas. Она построена на основе numpy и обеспечивает удобные инструменты для анализа и обработки данных.
Чтобы начать использовать pandas, установите её через командную строку:
1pip install pandas
Во всех примерах в этом параграфе предполагается, что библиотеки numpy и pandas импортированы следующим образом:
1import numpy as np
2import pandas as pd
Далее вы познакомитесь с двумя основными структурами данных библиотеки pandas — объектами Series и DataFrame — и научитесь создавать и обрабатывать таблицы.
Что такое объекты Series и DataFrame и как с ними работать
В библиотеке pandas определены два основных класса объектов для работы с данными:
Series— одномерный массив, способный хранить значения любого типа. По своей структуре напоминает словарь: каждому значению присваивается метка (индекс), которая может быть как числом, так и строкой.- DataFrame — двумерная таблица, в которой строки и столбцы имеют имена. Каждый столбец — это объект класса
Series, а сами данные удобно организованы для анализа и преобразований.
Создание и работа с этими объектами лежит в основе большинства операций в pandas.
Создание Series
Создать Series можно с помощью конструктора:
1s = pd.Series(data, index=index)
dataможет быть массивомnumpy, словарём или скаляром (числом).index— список меток, по умолчанию это целые числа от0доn-1.
Примеры:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2print(s)
3
4s = pd.Series(np.linspace(0, 1, 5))
5print(s)
6
7# Вывод программы
8
9# a 0
10
11# b 1
12
13# c 2
14
15# d 3
16
17# e 4
18
19# dtype: int32
20
21# 0 0.00
22
23# 1 0.25
24
25# 2 0.50
26
27# 3 0.75
28
29# 4 1.00
30
31# dtype: float64
Если data — словарь, а index не задан, то в качестве меток используются ключи словаря:
1d = {"a": 10, "b": 20, "c": 30, "g": 40}
2print(pd.Series(d))
3
4# Вывод программы:
5
6# a 10
7
8# b 20
9
10# c 30
11
12# g 40
13
14# dtype: int64
Если передать index, не совпадающий с ключами словаря, то отсутствующие значения будут заменены на NaN:
1print(pd.Series(d, index=["a", "b", "c", "d"]))
2
3# Вывод программы
4
5# a 10.0
6
7# b 20.0
8
9# c 30.0
10
11# d NaN
12
13# dtype: float64
Если data — число, обязательно передаётся index, определяющий количество элементов:
1index = ["a", "b", "c"]
2
3print(pd.Series(5, index=index))
4
5# Вывод программы
6
7# a 5
8
9# b 5
10
11# c 5
12
13# dtype: int64
Индексация, срезы и арифметика
Объекты Series поддерживают индексирование, срезы и математические операции:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2print(s["a"]) # Один элемент
3print(s[["a", "d"]]) # Несколько элементов
4print(s[1:]) # Срез
5print(s + s) # Поэлементное сложение
6
7# Вывод программы
8
9# Выбор одного элемента
10
11# 0
12
13# Выбор нескольких элементов
14
15# a 0
16
17# d 3
18
19# dtype: int32
20
21# Срез
22
23# b 1
24
25# c 2
26
27# d 3
28
29# e 4
30
31# dtype: int32
32
33# Поэлементное сложение
34
35# a 0
36
37# b 2
38
39# c 4
40
41# d 6
42
43# e 8
44
45# dtype: int32
Фильтрация
Можно использовать булевы условия для отбора значений:
1print(s[s > 2])
2
3# Вывод программы
4
5# Фильтрация
6
7# d 3
8
9# e 4
10
11# dtype: int32
Атрибуты Series
У объекта Series есть полезные свойства:
1s.name = "Данные"
2s.index.name = "Индекс"
3print(s)
4
5# Вывод программы
6
7# Индекс
8
9# a 0
10
11# b 1
12
13# c 2
14
15# d 3
16
17# e 4
18
19# Name: Данные, dtype: int32
Создание и работа с DataFrame
DataFrame — это таблица с именованными столбцами и индексами строк. Создать DataFrame можно из словаря списков:
1students_marks_dict = {
2 "student": ["Студент_1", "Студент_2", "Студент_3"],
3 "math": [5, 3, 4],
4 "physics": [4, 5, 5]
5}
6students = pd.DataFrame(students_marks_dict)
7print(students)
8
9# Вывод программы
10
11# student math physics
12
13# 0 Студент_1 5 4
14
15# 1 Студент_2 3 5
16
17# 2 Студент_3 4 5
Индексы строк и столбцов
У объекта DataFrame есть индексы по строкам и по столбцам. Их можно получить с помощью свойств index и columns:
1print(students.index)
2print(students.columns)
3
4# Вывод программы
5
6# RangeIndex(start=0, stop=3, step=1)
7
8# Index(['student', 'math', 'physics'], dtype='object')
По умолчанию строки нумеруются от 0. При необходимости индексы можно переопределить вручную:
1students.index = ["A", "B", "C"]
Каждый столбец DataFrame на самом деле представляет собой отдельный объект Series. Поэтому, если обратиться к одному столбцу по его имени, мы получим объект этого типа:
1print(type(students["student"]))
2
3# <class 'pandas.core.series.Series'>
Для доступа к строкам по индексам используют .loc[], включая срезы:
1print(students.loc["B":])
2
3# Вывод программы
4
5# student math physics
6
7# B Студент_2 3 5
8
9# C Студент_3 4 5
Как фильтровать, сортировать и агрегировать данные
В pandas объект Series можно создать из массива numpy, словаря или даже одного значения. Параметр index задаёт метки осей (индексы) и передаётся в виде списка. Метками могут быть числа, но чаще — строки.
Если в качестве data используется массив numpy, длина index должна совпадать с числом элементов. Если индекс не задан, он формируется автоматически как последовательность от 0 до len(data) - 1:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2print(s)
3print()
4s = pd.Series(np.linspace(0, 1, 5))
5print(s)
6
7# Вывод
8
9# a 0
10
11# b 1
12
13# c 2
14
15# d 3
16
17# e 4
18
19# dtype: int32
20
21#
22
23# 0 0.00
24
25# 1 0.25
26
27# 2 0.50
28
29# 3 0.75
30
31# 4 1.00
32
33# dtype: float64
Объект Series во многом напоминает словарь: каждому значению соответствует собственная метка.
Если data — это словарь, а index не задан, в качестве индексов будут использованы ключи словаря. Если index задан и содержит значения, которых нет среди ключей словаря, то в соответствующих ячейках будет стоять NaN — стандартное обозначение отсутствующих данных в pandas:
1d = {"a": 10, "b": 20, "c": 30, "g": 40}
2print(pd.Series(d))
3print()
4print(pd.Series(d, index=["a", "b", "c", "d"]))
5
6# Вывод
7
8# a 10
9
10# b 20
11
12# c 30
13
14# g 40
15
16# dtype: int64
17
18#
19
20# a 10.0
21
22# b 20.0
23
24# c 30.0
25
26# d NaN
27
28# dtype: float64
Если data — это одно значение, параметр index обязательно нужен. Серия будет состоять из повторяющихся значений:
1index = ["a", "b", "c"]
2print(pd.Series(5, index=index))
3
4# Вывод
5
6# a 5
7
8# b 5
9
10# c 5
11
12# dtype: int64
С объектами Series можно работать так же, как с массивами numpy: выполнять срезы, индексацию, поэлементные операции:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2print("Выбор одного элемента")
3print(s["a"])
4print("Выбор нескольких элементов")
5print(s[["a", "d"]])
6print("Срез")
7print(s[1:])
8print("Поэлементное сложение")
9print(s + s)
10
11# Вывод
12
13# Выбор одного элемента
14
15# 0
16
17# Выбор нескольких элементов
18
19# a 0
20
21# d 3
22
23# dtype: int32
24
25# Срез
26
27# b 1
28
29# c 2
30
31# d 3
32
33# e 4
34
35# dtype: int32
36
37# Поэлементное сложение
38
39# a 0
40
41# b 2
42
43# c 4
44
45# d 6
46
47# e 8
48
49# dtype: int32
Можно отфильтровать данные по условию:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2print("Фильтрация")
3print(s[s > 2])
4
5# Вывод
6
7# Фильтрация
8
9# d 3
10
11# e 4
12
13# dtype: int32
У объектов Series есть два полезных атрибута:
name— название набора данных;index.name— имя оси индексов:
1s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
2s.name = "Данные"
3s.index.name = "Индекс"
4print(s)
5
6# Вывод
7
8# Индекс
9
10# a 0
11
12# b 1
13
14# c 2
15
16# d 3
17
18# e 4
19
20# Name: Данные, dtype: int32
Как создавать и изменять табличные структуры в pandas
Обычно табличные данные хранятся в файлах. Такие наборы принято называть датасетами (англ. dataset, набор данных). Файлы с данными могут быть в разных форматах: CSV, Excel, JSON, SQL и другие. Библиотека pandas поддерживает как чтение, так и сохранение таблиц в этих форматах.
Как считывать и сохранять данные в различных форматах (CSV, Excel, JSON)
Рассмотрим несколько примеров:
CSV-файлы
- Считывание:
pd.read_csv("имя_файла.csv") - Сохранение:
df.to_csv("имя_файла.csv")
Excel-файлы (формат 2007+)
- Считывание:
pd.read_excel("имя_файла.xlsx") - Сохранение:
df.to_excel("имя_файла.xlsx")
JSON-файлы
- Считывание:
pd.read_json("имя_файла.json") - Сохранение:
df.to_json("имя_файла.json")
Полный список поддерживаемых форматов и настроек доступен в официальной документации.
CSV остаётся одним из самых популярных форматов хранения табличных данных. Это обычный текстовый файл, в котором значения разделены символами (например, запятой или точкой с запятой), а строки идут с новой строки. Обычно первая строка содержит заголовки столбцов.
Пример содержимого CSV-файла:
1"gender","race/ethnicity","parental level of education","lunch","test preparation course","math score","reading score","writing score"
2"female","group B","bachelor's degree","standard","none","72","72","74"
3"female","group C","some college","standard","completed","69","90","88"
Для дальнейшей работы скачайте данный файл с датасетом.
Получим датасет из CSV-файла с данными о студентах:
1import numpy as np
2import pandas as pd
3
4students = pd.read_csv("StudentsPerformance.csv")
Полученный объект students относится к классу DataFrame.
Для получения первых n строк датасета используется метод head(n). По умолчанию возвращается пять первых строк:
1print(students.head())
2
3# Вывод программы
4
5# gender race/ethnicity ... reading score writing score
6
7# 0 female group B ... 72 74
8
9# 1 female group C ... 90 88
10
11# 2 female group B ... 95 93
12
13# 3 male group A ... 57 44
14
15# 4 male group C ... 78 75
16
17# [5 rows x 8 columns]
Для получения последних n строк используется метод tail(n). По умолчанию возвращается пять последних строк:
1print(students.tail(3))
2
3# Вывод программы
4
5# gender race/ethnicity ... reading score writing score
6
7# 997 female group C ... 71 65
8
9# 998 female group D ... 78 77
10
11# 999 female group D ... 86 86
12
13#
14
15# [3 rows x 8 columns]
Для получения части датасета можно использовать срез:
1print(students[10:13])
2
3# Вывод программы
4
5# gender race/ethnicity ... reading score writing score
6
7# 10 male group C ... 54 52
8
9# 11 male group D ... 52 43
10
11# 12 female group B ... 81 73
12
13#
14
15# [3 rows x 8 columns]
В качестве индекса можно использовать условия для фильтрации данных. Выберем первые 5 значений по математике у студентов, прошедших подготовку:
1print(students[students["test preparation course"] == "completed"]["math score"].head())
2
3# Вывод программы
4
5#
6
7# 1 69
8
9# 6 88
10
11# 8 64
12
13# 13 78
14
15# 18 46
16
17# Name: math score, dtype: int64
Выведем пять лучших результатов тестов по трём дисциплинам для предыдущей выборки с помощью сортировки методом sort_values().
Сортировка по умолчанию производится в порядке возрастания значений. Для сортировки по убыванию в именованный аргумент ascending передаётся значение False.
1with_course = students[students["test preparation course"] == "completed"]
2
3print(with_course[["math score", "reading score", "writing score"]]
4 .sort_values(["math score", "reading score", "writing score"], ascending=False)
5 .head())
6
7# Вывод программы
8# math score reading score writing score
9# 916 100 100 100
10# 149 100 100 93
11# 625 100 97 99
12# 623 100 96 86
13# 114 99 100 100
Сортировка по новой колонке total_score, которую добавим вручную:
1students["total score"] = (students["math score"]
2 + students["reading score"]
3 + students["writing score"])
4
5print(students.sort_values("total score", ascending=False).head())
6
7# Вывод программы
8
9#
10
11# gender race/ethnicity ... writing score total score
12
13# 916 male group E ... 100 300
14
15# 458 female group E ... 100 300
16
17# 962 female group E ... 100 300
18
19# 114 female group E ... 100 299
20
21# 179 female group D ... 100 297
22
23#
24
25# [5 rows x 9 columns]
Чтобы в таблицу добавить колонку, подойдёт метод assign(). Данный метод даёт возможность создавать колонки при помощи лямбда-функции.
Обратите внимание: данный метод возвращает новую таблицу, а не меняет исходную.
Перепишем предыдущий пример с использованием assign():
1scores = students.assign(total_score=lambda x: x["math score"]
2 + x["reading score"]
3 + x["writing score"])
4
5print(scores.sort_values("total_score", ascending=False).head())
6
7# Вывод программы
8
9#
10
11# gender race/ethnicity ... writing score total_score
12
13# 916 male group E ... 100 300
14
15# 458 female group E ... 100 300
16
17# 962 female group E ... 100 300
18
19# 114 female group E ... 100 299
20
21# 179 female group D ... 100 297
Группировка и агрегирование данных
Метод groupby() позволяет сгруппировать записи по признаку. Например, узнаем, сколько студентов разного пола прошли подготовку:
1print(students.groupby(["gender", "test preparation course"])["writing score"].count())
2
3# Вывод программы
4
5#
6
7# gender test preparation course
8
9# female completed 184
10
11# none 334
12
13# male completed 174
14
15# none 308
16
17# Name: race/ethnicity, dtype: int64
Для вычисления сводных значений используем агрегирующие функции (среднее, медиана, сумма и т. п.).
Например:
1agg_functions = {"math score": ["mean", "median"]}
2
3print(students.groupby(["gender", "test preparation course"]).agg(agg_functions))
4
5# Вывод программы
6
7#
8
9# math score
10
11# mean median
12
13# gender test preparation course
14
15# female completed 67.195652 67.0
16
17# none 61.670659 62.0
18
19# male completed 72.339080 73.0
20
21# none 66.688312 67.0
Как визуализировать табличные данные с помощью matplotlib
Для построения графиков pandas использует библиотеку matplotlib. Чтобы начать с ней работать, необходимо:
- Установить библиотеку.
- Добавить импорт в начало программы.
Для установки выполним команду:
1pip install matplotlib
А затем импортируем:
1import matplotlib.pyplot as plt
Пример: гистограмма распределения баллов
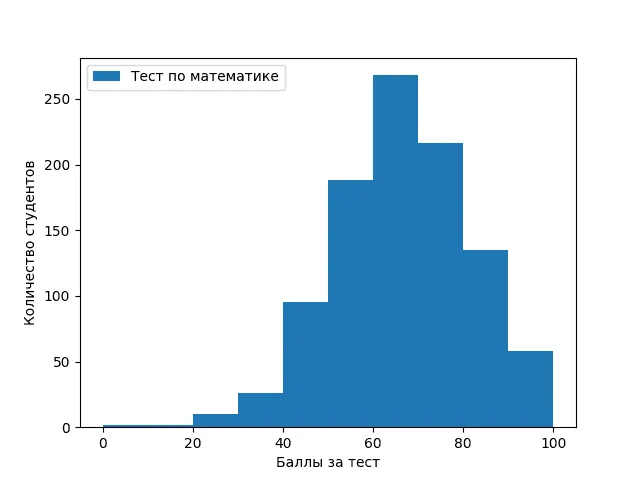
Построим гистограмму, отображающую распределение количества студентов по баллам за тест по математике:
1plt.hist(students["math score"], label="Тест по математике")
2plt.xlabel("Баллы за тест")
3plt.ylabel("Количество студентов")
4plt.legend()
5plt.show()
В результате выполнения кода отобразится график, где по оси X — баллы, а по оси Y — количество студентов, набравших соответствующий результат.
Ещё по теме
Для более детального изучения библиотеки numpy рекомендуем почитать документацию.
✅ У вас получилось разобраться с pandas?
Что дальше
В этом параграфе вы освоили базовые приёмы работы с табличными данными в библиотеке pandas.
Вы узнали, чем объекты Series и DataFrame отличаются друг от друга, научились создавать такие структуры и извлекать из них данные с помощью индексов и условий.
Вы попробовали считывать и сохранять датасеты в форматах CSV, Excel и JSON, освоили сортировку, группировку и агрегацию — а также построили свою первую визуализацию с помощью matplotlib.
Вы также увидели, как pandas интегрируется с другими библиотеками Python, расширяя возможности анализа и обработки реальных данных.
В следующем параграфе мы перейдём к важному практическому навыку — работе с HTTP-запросами и API. Вы узнаете, как загружать данные из внешних сервисов, отправлять запросы и получать ответы, а также взаимодействовать с API-сервисами вроде Static API и Яндекс Диска. Всё это — ключ к тому, чтобы ваши программы могли общаться с внешним миром.
А пока вы не ушли дальше — закрепите материал на практике:
- Отметьте, что урок прочитан, при помощи кнопки ниже.
- Пройдите мини-квиз, чтобы проверить, насколько хорошо вы усвоили тему.
- Перейдите к задачам этого параграфа и потренируйтесь.
- Перед этим загляните в короткий гайд о том, как работает система проверки.
Хотите обсудить, задать вопрос или не понимаете, почему код не работает? Мы всё предусмотрели — вступайте в сообщество Хендбука! Там студенты помогают друг другу разобраться.
Ключевые выводы параграфа
- В
pandasопределены два основных типа объектов:Series(одномерные структуры) иDataFrame(таблицы), основанные на numpy. - Объекты
SeriesиDataFrameпозволяют фильтровать, сортировать и агрегировать данные по условиям, индексам и значениям. - С
pandasудобно считывать и сохранять данные в популярных форматах — CSV, Excel, JSON — и обрабатывать их с помощью встроенных методов. - Для анализа доступны мощные инструменты группировки (
groupby), агрегации (agg) и построения новых столбцов (assign). - Визуализация данных осуществляется с помощью библиотеки
matplotlib, на основе которой можно строить гистограммы и другие графики.