Как написать загрузчик для приложения

Базовые функции
Наша задача — загрузить N постов с бэкенда и отобразить их в ленте.
На стороннем потоке запускаем запрос и дожидаемся его окончания. Пока нет никаких ошибок. Считаем, что у нас идеальная сеть и всё всегда приходит.
Затем переключаемся на главный поток, чтобы работать с view. В adapter для recyclerview вставляем данные, которые загрузили, и уведомляем его о том, что пришли новые данные.
1lifecycleScope. launch(Dispatchers.I0) {
2val items = feedApi.getApi( )
3withContext(Dispatchers.Main) {
4adapter.appendItems(items)
5adapter.notifyDataSetChanged( )
6}
7}
Добавляем пагинацию
Лента бесконечная, её можно скроллить сколько угодно. Для этого нам необходима пагинация, или структурирование информации путём разделения её на отдельные куски — «страницы». Они должны загружаться друг за другом, последовательно.
Так как у нас появляется пагинация, введём понятие current page. Для этого заводим переменную, которая обозначает, какую page мы загрузим следующей, — изначально нулевую. Затем при начале загрузки увеличиваем её, чтобы отобразить следующую страницу.
1var currentPage = 0
2
3fun load( ) {
4val pageToLoad = currentPage++
5lifecycleScope. launch(Dispatchers.I0) {
6val items = feedApi.getApi(pageToLoad)
7withContext(Dispatchers.Main) {
8adapter.appendItems(items)
9adapter.notifyDataSetChanged( )
10}
11}
12}
13
После передаём page в API, загружаем нужную страницу и прибавляем загруженные данные в адаптер. Важно, что у адаптера мы вызываем метод appendItems, который прибавляет объекты к уже существующим. Обратите внимание, тут не setItems, мы не обновляем их, а присоединяем.
Но это ещё не пагинация. Нам нужно загружать данные, когда пользователь проскролил до конца. Для этого можно добавить listener на recycler. Мы смотрим, какой предмет последний, и если до конца списка осталось немного — начинаем следующую загрузку.
1recyclerView.addOnScrollListener(object :
2RecyclerView.OnScrollListener( ) {
3override fun onScrolled(
4recyclerView: RecyclerView,
5dx: Int,
6dy: Int
7) {
8val lastVisibleIndex = findLastVisibleItemPosition( )
9if (getItemsCount( ) – LastVisibleIndex <= THRESHOLD) {
10load( )
11}
12}
13
14})
Здесь возникает проблема: мы никак не ограничиваем количество запросов. Этот метод вызывается при любом изменении скролла, и каждый раз он запускает новую загрузку. Поэтому нужно добавить новые флаги, что у нас идёт загрузка: так мы не даём начать следующую. В начале загрузки также уточняем, что она запущена. Если всё успешно, флаг устанавливаем false и указываем, что активной загрузки нет и можно загружать снова.
1var isLoading = false
2
3
4var currentPage = 0
5
6fun load( ) {
7if (isLoading) {
8return
9}
10isLoading = true
11val pageToLoad = currentPage++
12lifecycleScope. launch(Dispatchers.I0) {
13val items = feedApi.getApi(pageToLoad)
14withContext(Dispatchers.Main) {
15isLoading = false
16adapter.appendItems(items)
17adapter.notifyDataSetChanged( )
18}
19}
20}
Добавляем кеш
Пользователи не хотят ждать, пока мы загрузим данные из сети, они хотят сразу видеть их при открытии приложения. Для этого нужно добавить кеш.
Структура осталась та же, но добавляется переменная cacheEnded. Она показывает, есть ли данные в кеше. Если данных нет, то cacheEnded = true — грузим данные из API.
Для этого мы делаем запрос в API, получаем данные, кладём их в базу данных и возвращаем. Представим, что все инструменты поддерживают один и тот же тип. Что делать, если кеш не кончился? Отправляем в него запрос.
Однако может возникнуть ситуация, когда кеш окажется пустым. В таком случае мы ставим флаг, что он закончился. За новой страницей делаем запрос в сеть, её кладём в кеш и возвращаем.
1fun load(clearDataBeforeSet: Boolean) {
2val pageToLoad = currentPage
3//…
4val loadJob = lifecycleScope. launch(Dispatchers.I0) {
5val = items = try {
6if (cacheEnded) {
7val items = feedApi.getApi(pageToLoad)
8db.putPage(pageToLoad, items)
9items
10} else {
11val items = db.getPage(pageToLoad)
12if (items.isEmpty()) {
13withContext(Dispatchers.Main) {
14cacheEnded = true
15}
16val items = feedApi.getApi(pageToLoad)
17db.putPage(pageToLoad, items)
18items
19} else {
20items
21}
22}
23}
24}
25}
В итоге для реализации 5–6 задач получилось полотно кода. Он сложный: в нём трёхуровневые if, прямая работа с потоками, разные флаги, которые друг с другом не связаны. С этим работать уже откровенно сложно.
Делаем особый вид экрана
Если у пользователя нет подписок и в ленту не пришло ни одной картинки, ему показывается предложение подписаться на кого-нибудь. Если в адаптере сейчас нет предметов, будем показывать какой-то пустой state. Например, предложение подписаться. Если предметы есть, например картинки, — покажем их.
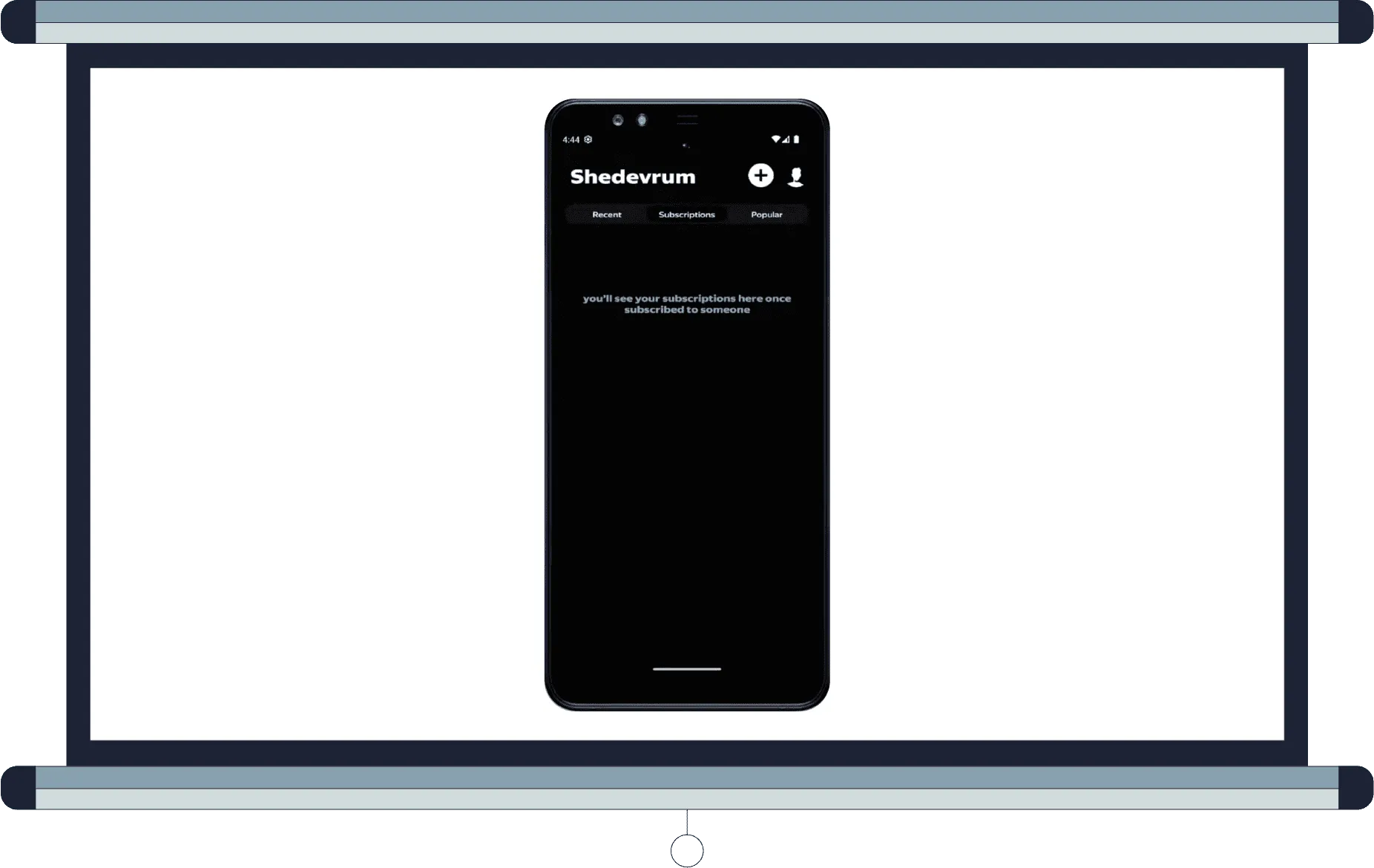
Но это не работает, потому что изначально, когда начинается работа вашего feed, адаптер пуст. Возможно, вы часто видели такие баги в разных приложениях. Например, в Glovo: когда вы заходите на экран заказов, а там говорится, что у вас пусто. Затем начинается загрузка и появляются ваши заказы.
Добавим, что в случае успешной загрузки, если предметы пустые, показываем пустое состояние, иначе — применяем обычную логику. Это иногда может работать, но приводит к багу. Чтобы его исключить, добавим ещё один if, который будет проверять, что нулевая страница сразу пустая.
1fun load(clearDataBeforeSet: Boolean) {
2if (isLoading) {
3return
4}
5val pageToLoad = currentPage
6isLoading = true
7loadJob = lifecycleScope. launch(Dispatchers.I0) {
8val = items = //…
9withContext(Dispatchers.Main) {
10currentPage++
11isLoading = false
12adapter.setIsError(false)
13if (items.isEmpty( ) pageToLoad = = 0) {
14adapter.showEmptyState( )
15} else {
16if (clearDataBeforeSet) {
17adapter.setItems(items)
18} else {
19adapter.appendItems(items )
20}
21adapter.notifyDataSetChanged( )
22}
23}
24}
25
Мы добавили ещё кода, работать с ним стало ещё сложнее. Теперь представьте, что мы живём не в идеальном мире, у нас есть ещё три разных слоя данных:
-
база данных;
-
данные из сети;
-
то, что мы сообщаем из приложения.
Как и любую большую функциональность, загрузчики лучше прятать за интерфейсами. Для загрузчиков можно взять удобный интерфейс loader. У него есть понятие «состояние» — то, что он вам сейчас показывает как клиенту:
-
данные (data);
-
флаг о том, загружает ли он что-то сейчас;
-
флаг об ошибке.
С помощью этих трёх флагов можно реализовывать очень большой спектр загрузок.
У loader есть два публичных метода: state, в котором лежат данные, и load, который клиенты дёргают по скроллу. С таким внешним состоянием, конечно, много не сделать. Нужно работать с внутренним состоянием, и тут полей уже побольше. С их помощью вы будете решать, как работать вашему loader. Я бы выделил шесть полей во внутреннем состоянии:
-
текущие данные;
-
флаг загрузки из кеша;
-
флаг загрузки из сети;
-
флаг, есть ли что-то в кеше;
-
флаг, есть ли что-то в сети;
-
флаг о том, что случилась ошибка в сети.
С помощью функции map вы получаете внутренний state и возвращаете публичный. Флажком isLoading показываете, загружается что-то из сети или из кеша. Флаг ошибки также есть во внутреннем state. Таким образом, внутри loader мы можем работать с внутренним state, а для клиентов он обновляется автоматически.
1private val _state: MutableStateFlow<InnerState<Data>> =
2MutableStateFlow(createDefaultState( ))
3
4override val state: Flow<Loader.State<Data>> =
5_state.map {
6Loader.State(
7data = it.currentData,
8isLoading = it.isLoadingFromRemote || it.isLoadingFromCache,
9isError = it.remoteError,
10)
11}
12
Добавляем корутины
Очень большую поддержку оказывают корутины, потому что у них можно легко взять один поток. Такой workDispatcher с помощью флага limitedParallelism позволяет обновлять внутренний state строго на одном потоке. Если экран закроется, все загрузки остановятся, поэтому также важно взять scope, чтобы ресурсы не потерялись.
1@OptIn(ExperimentalCoroutinesApi: :class)
2private val workDispatcher = Dispatchers.I0.limitedParallelism(1)
3
4private val scope: CoroutineScope
Loader легко представить state-машиной. Мы берём scope, запускаем на workDispatcher и внутри этого процесса берём старый state. К нему применяем мутацию и устанавливаем новым state. Благодаря тому, что внутренний state преобразуется во внешний, будут мутировать оба.
1private fun launchWork(block: (InnerState<Data>) -> InnerState<Data>) {
2scope. launch(workDispatcher) {
3 _state.value = block(_state.value)
4}
5}
Реализуем функции load и launchLoad
Мы вызываем наш утилитный метод launchWork, в который передаём лямбду — мутацию state. Нужно реализовать функцию launchLoad, которая берёт state и возвращает его, чтобы делать загрузку из кеша или из сети.
1override fun load ( ) {
2launchWork { state –>
3launchLoad(state = state)
4}
5}
Мы начинаем работать с флагами. Главное преимущество этого подхода в том, что теперь наши флаги и номера страниц собраны в одном месте и мы работаем с ними строго с одного потока.
Сначала пытаемся запустить загрузку из кеша. Для этого вызываем метод launchCacheLoad. Если загрузить из кеша не получилось, смотрим, можем ли загрузить из сети. Для этого нужно, чтобы соблюдались условия:
-
в сети есть данные и feed не кончился;
-
из сети и кеша сейчас ничего не грузят;
-
нет ошибки.
1private fun launchLoad(state: InnerState<Data>,): InnerState<Data> {
2if (state.hasMoreInCache && !state.isLoadingFromCache) {
3return launchCacheLoad(state = state)
4}
5
6if (state.hasMoreInRemote
7&& !state.isLoadingFromRemote
8&& !state.isLoadingFromCache
9&& !state.remoteError
10) {
11return launchRemoteLoad(state)
12}
13return state
14}
15
Этот состав флагов может быть разным, можно наворачивать какую угодно логику, главное — подход, что все флаги вместе и синхронизированы.
Если мы можем запустить загрузку из сети, запускаем. Если не смогли, возвращаем state — ничего не изменилось.
Запускаем загрузку из кеша
LaunchCacheLoad берёт новую страницу для загрузки. Предположим, что данные знают, какую страницу грузить дальше. Тогда берём и отдельным потоком запускаем загрузку из репозитория, например вашего локального.
Мы оказываемся в ситуации, когда мы на стороннем потоке, а не в state-машине, и эти данные нужно вернуть. Тогда мы снова вызываем нашу функцию, получаем новый state и вызываем метод onCacheLoaded. Передаём новый state и данные, которые загрузили.
1private fun launchCacheLoad(
2state: InnerState<Data>,
3): InnerState<Data> {
4val pageToLoad = state.currentData.nextPage
5scope. launch(Dispatchers.I0) {
6val chunk = localRepository.load(pageToLoad)
7launchwork {
8onCacheLoaded(chunk, it)
9}
10}
11return state.copy(
12loadingFromCache = true
13)
14}
15
В CacheLoaded мы передаём не тот state, что был в начале загрузки, а тот, что будет на момент её окончания.
Когда загрузка завершилась, получаем загруженные данные, сливаем их с новыми и снова мутируем state. Так мы устанавливаем, что у нас есть новые и старые данные. Указываем, что теперь не грузим из кеша, и устанавливаем флаг о том, есть ли что-то в кеше.
1private fun onCacheLoaded(
2chunk: Data,
3state: InnerState<Data>,
4): InnerState<Data> {
5val mergedData = state.currentData + chunk
6return state.copy(
7currentData = mergedData,
8isLoadingFromCache = false,
9hasMoreInCache = chunk.hasMore,
10)
11}
Запускаем загрузку из сети
При загрузке из сети могут возникать ошибки. Как и раньше, берём номер страницы, начиная с которой нам необходимо грузить. Затем делаем API-запрос в удалённый репозиторий — нашу сеть или облако. Смотрим, пришли ли данные.
Если данные не пришли, значит, случилась какая-то ошибка. Её нужно обработать. Здесь пользуемся тем же механизмом: получаем актуальный state на момент окончания загрузки. Важно понимать, что в этот промежуток между началом загрузки из сети и окончанием никаких новых загрузок начато быть не может.
1private fun launchRemoteLoad(state: InnerState<Data>): InnerState<Data> {
2val pageToLoad = state.currentData.nextPage
3scope. launch(Dispatchers.I0) {
4val result = invokeApiCall { remoteRepository.load(pageToLoad) }
5val chunk = result.getOrNull()
6if (chunk == null) i
7launchWork {
8it.copy(
9isLoadingFromRemote = false,
10remoteError = true,
11)
12}
13return@launch
14}
15launchWork {
16onRemoteLoaded(chunk, it)
17}
18}
19return state.copy(
20isLoadingFromRemote = true
21)
22}
23
Если данные загрузились, мы так же берём актуальный state на текущий момент и вызываем onRemoteLoaded. Всё происходит на стороннем потоке, а на потоке в нашей state-машине мы мутируем state и говорим, что теперь загружаем из кеша.
В методе onRemoteLoaded мы сливаем данные и говорим, что теперь у нас в сети есть столько-то. Сообщаем, что теперь нет загрузки из кеша и нет ошибки, потому что мы загрузили из сети успешно.