Может ли ИИ диагностировать болезни?

Как ты оказался в этом проекте?
Изначально я закончил ФКН ВШЭ, учился на прикладной математике и информатике. Потом начал заниматься программированием и поступил в ШАД. Там было классно и я решил пойти прокачать софт и хард скиллы руководителя в ШМЯ. В итоге, сейчас работаю лидом аналитики фида в Яндекс.Go. В проект меня позвали ребята, с которыми мы познакомились ещё в ШАДе. Когда я узнал, что это социальный проект на базе облачной инфраструктуры — сразу согласился.
Расскажешь, что это за проект и почему ты решил в нём участвовать?
Бывает так, что на этапе внутриутробного роста у ребёнка не успевают полностью сформироваться некоторые части позвонков. В норме эти части защищают спинной мозг и нервы. Такая патология называется Spina Bifida (спина бифида), это орфанное заболевание: на одного ребёнка с подобным диагнозом приходится около десяти тысяч здоровых детей.
Если вовремя поставить диагноз, у родителей будет возможность принять решение о внутриутробной операции и подготовиться к рождению особенного ребёнка. Но только очень опытные и узкопрофильные УЗИ-специалисты могут увидеть нарушения уже в первом триместре.
По инициативе фонда «Спина Бифида» мы в Яндексе реализовали кросс-дисциплинарный проект Spina Bifida и создали алгоритм, который поможет диагностировать болезнь без вовлечения не всегда доступных высококлассных УЗИ-специалистов.
Я рад, что смог внести вклад в проект, который объединяет искусственный интеллект, медицину и благотворительность. Наконец появилась возможность решить прикладную задачу, которая положительно повлияет на мир.
А как всё начиналось?
Программу разработала большая команда. Ребята из Yandex Cloud вели проект и делали архитектуру, выпускники ШАДа — ML-модели и интерфейс. Я занимался обучением, тестированием, пере- и дообучением нейросетей для выделения зоны интереса и классификации на корректность снимка и наличие патологии. А ещё писал интерфейс для пользователей.
Изначально мы получили запрос от фонда. Нужно было придумать алгоритм, который сможет проанализировать УЗИ-снимки и определить наличие патологии у плода. Врачи из НМИЦ им. Кулакова дали материал для обучения ML-модели — 6 тысяч размеченных снимков. Ещё они поэтапно рассказали, как сами выявляют патологию. На основе этого мы построили план и начали разработку.
Какой у вас был пошаговый план?
Сначала лиды сформировали пул задач. В целом тут ничего необычного:
-
Создание архитектуры решения. По сути, это структура будущего продукта. Она нужна, чтобы у команды сформировалось чёткое понимание того, каким должен получиться конечный продукт.
-
Доразметка изображений. Определяли на изображениях зону интереса, корректность, патологию. В основном этим занимались врачи.
-
Унификация базы данных с изображениями. Тут мы объединили все снимки, которые у нас были, в единый датасет.
-
Создание пайплайна для обучения моделей. Прописали алгоритмы моделей и метрики качества. На основе метрик качества модель принимала решение о корректности изображений. Для этого кейса я использовал функцию F2-score.
-
Тестирование гипотез в пайплайне. Тут добавляли разные функции потерь и аугментации; гиперпараметры и так далее. Такое тестирование нужно, чтобы увидеть на ходу, чего не хватает программе, и доработать её.
-
Создание веб-интерфейса для врачей.
Интересно! А как нейросеть училась распознавать патологию?
На самом деле получилось целых пять нейросетей: одна для выделения зоны интереса, две для оценки корректности и ещё две для определения патологии. Получается, основные структурные элементы программы — это три последовательных блока. Эти блоки повторяют образ мыслей врачей и соответствуют трём этапам работы программы.
-
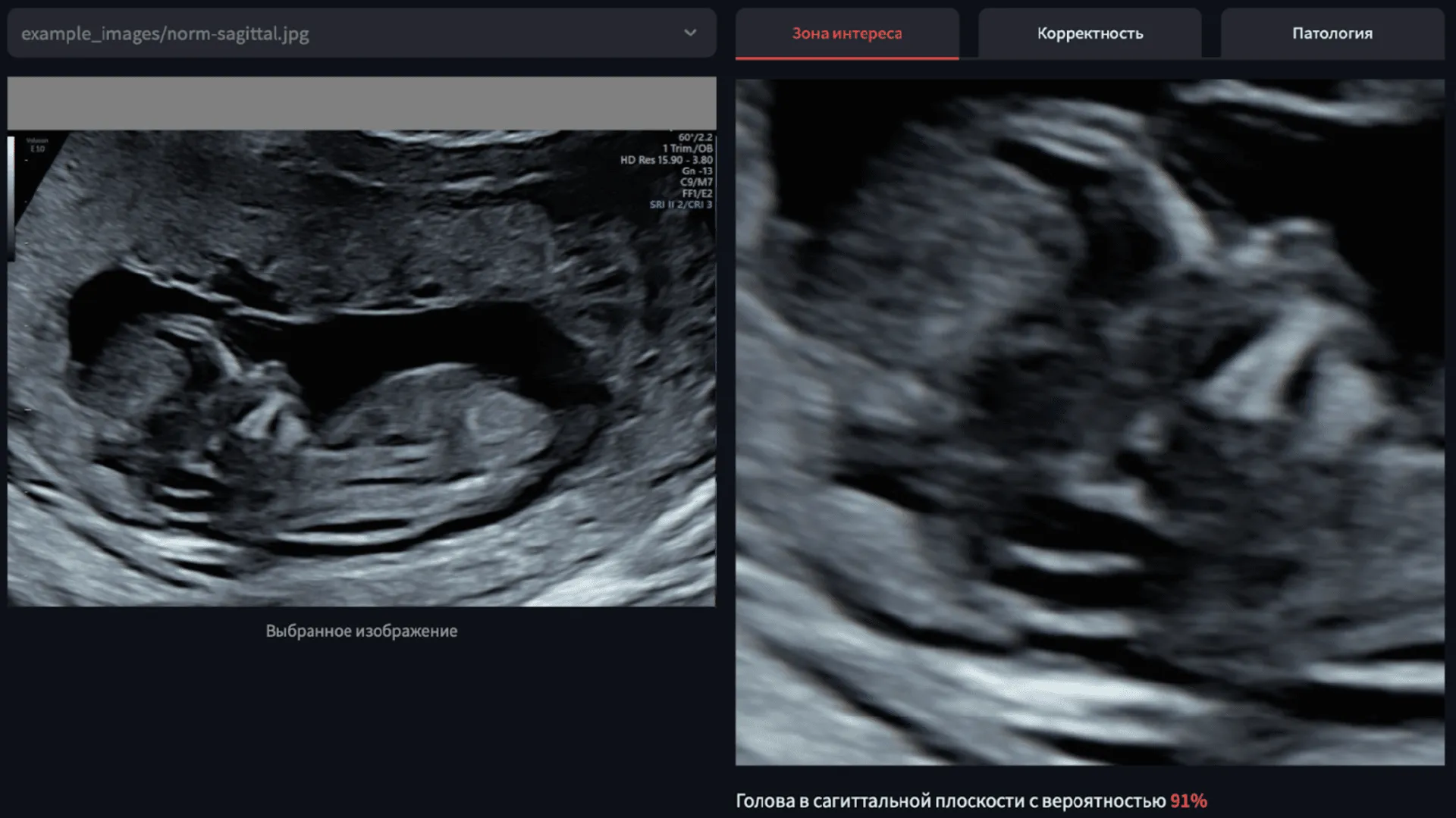
Поиск и обрезка зоны интереса. Сначала врач на снимке смотрит только на зону интереса: в нашем случае это голова и часть позвоночника. Поэтому мы собрали модель выделения зоны интереса. Для этого я применил задачу Object Detection. Это такая задача в машинном обучении, которая определяет, есть ли на изображении какой-то конкретный объект, а также ищет его границы на уровне пикселей.
-
Нейросеть определяет первичную корректность изображения. Потом врач проводит анализ того, насколько качественно на изображении представлены необходимые ему признаки: не мешает ли шум, контраст, твёрдые ткани и так далее. Поэтому в разработке для этого этапа я прописал ML-модель, которая классифицирует изображение как корректное или некорректное.
-
Поиск патологии. Наконец, если изображение корректное, врач принимает решение о наличии патологии. Аналогичный этап в разработке — ML-модель, обучена классифицировать изображения на норму и патологию. Это тоже своего рода определение корректности изображения: если патология есть, нейросеть считает снимок «корректным».
Для обучения ИИ 6 тысяч снимков очень мало. Поэтому мы сделали аугментацию и расширили учебный материал. Сложно сказать, сколько точно изображений дала аугментация, потому что преобразования применяются последовательно и случайно на каждом батче. Потенциально там сотни тысяч вариаций картинок.
Аугментация данных — метод в медицинской визуализации. Она помогает улучшить модели диагностики, которые используют изображения для выявления и распознавания заболеваний.
Так как большинство изображений корректные и нормальные, модель была склонна реже замечать патологию. Чтобы победить эту проблему, я использовал специальные функции потерь — Focal Loss, Cross Entropy Loss с весами и так далее.
Как происходило взаимодействие программистов и врачей?
Врачи помогали валидировать, что аугментированные снимки всё ещё похожи на настоящие.
Например, перекрасить УЗИ из серого в любой цвет радуги — это тоже аугментация, но она скорее вредная, потому что зелёных УЗИ-снимков на практике не бывает. Так модель может выучить несвойственные реальности признаки.
Если говорить не об изменении цвета, а о более тонкой аугментации — например, понижении качества из библиотеки MONAI или накладывании различных шумов, то задача усложняется и для решения нужен специалист. Тут и помогали врачи. Они также тестировали программу.
Очень классный проект! Им может воспользоваться кто угодно?
Да, решение сейчас в открытом доступе. Проект продолжает развиваться: следующим шагом станет сбор и обработка новых данных в НМИЦ им. Кулакова для дообучения модели и повышения её эффективности.