ML-разработчик о том, зачем он пошел учиться краудсорсингу

Весной 2020 года в CS центре стартовал курс «Сбор и обработка данных с помощью краудсорсинга». Его уже включили в обязательную программу для бакалавриата факультета математики и компьютерных наук в СПбГУ, а также для студентов ФИТИП в ИТМО. Ещё раньше, осенью 2019 года, курс был запущен в Школе анализа данных. Мы поговорили с выпускником ШАДа и ML-разработчиком Даниилом Поляковым, который прошёл этот курс. Он рассказал о том, как применяет полученные знания в работе, как курс повлиял на восприятие профессии и подходы к сбору и разметке данных.
Зачем учиться краудсорсингу
Я учусь в МФТИ на кафедре анализа данных и работаю ML-разработчиком в Яндекс.Такси. Раньше стажировался в команде компьютерного зрения беспилотников Яндекса. Осенью в рамках обучения в ШАДе я решил пойти на курс «Сбор и обработка данных с помощью краудсорсинга».
Во-первых, до этого курса я вообще не задумывался, где брать данные, несмотря на то, что разбирался в ML, легко мог построить алгоритм классификации или дообучить нейросеть под необходимую задачу. Я просто об этом не задумывался: кто-то другой данные собрал и разметил — бери их да обучай алгоритмы. Потом я понял, что это мое слабое место, а курс может стать «кирпичиком», который сделает меня full-stack разработчиком машинного обучения.
Во-вторых, для новых, прорывных задач данных нет вообще. Я ощутил это, начав писать диплом по анализу рентгеновских стоматологических снимков с помощью нейросетей, над которым сейчас работаю. Нужно определить форму зубов по фото, чтобы провести диагностику на наличие дефектов. Это классическое задание компьютерного зрения. Но у меня не было размеченных фото. Оказалось, выделить контур зуба — простая механическая задача, не требующая медицинских знаний. Сделать её может любой, необязательно стоматолог, время которого стоит дорого.
В-третьих, качество работы конечного алгоритма напрямую зависит от качества сбора и разметки данных: я понял это на стажировке в команде беспилотников. Качество разметки напрямую влияет на работу обученной сети. В беспилотных автомобилях это особенно критично: они должны видеть всё вокруг.
Как проходило обучение
Курс проходил с сентября по декабрь один раз в неделю, поэтому я спокойно совмещал обучение со стажировкой. У нас было 12 лекций и 12 семинаров с домашними заданиями.
Лекции и семинары. На лекциях выступали крутые специалисты, в частности коллеги из отделов Яндекса, где для разметки используется Толока. Они делились опытом: как делали разметку раньше и как делают сейчас, какие ошибки допускали и как их избежать. Спикеры собирали кейсы и показывали: так работает, а так нет.
В том числе рассказывали про неожиданные области применения краудсорсинга, например, в оптимизации процессов. В некоторых подразделениях Яндекса есть только один тестировщик, который создает задания в Толоке, а всё остальное тестируют исполнители. В Толоке также делают разметку речи для Алисы и попарные сравнения соответствия сайтов и картинок текстовому запросу (для ранжирования в Поиске). А команда Такси с помощью краудсорсинга контролирует качество машин: чистое ли авто приехало на заказ. Такая же задача есть в Яндекс.Драйве. А в Картах нужно собирать разметку для сопоставления организаций на картах и панорамах. Было безумно интересно узнать, что можно собирать качественную разметку с помощью незнакомых людей, которым изначально нет поводов доверять.
Домашние задания последовательны: этапы сбора данных разбираются шаг за шагом. Именно при их выполнении (то есть настраивая боевые проекты) мы учились видеть подводные камни. Раз в одну-две недели нам выдавали небольшой бюджет на Толоку. Сначала кажется: как можно за 5 долларов качественно разметить 100 фотографий? Потом учишься: настраиваешь контроль качества, декомпозируешь задачи на более простые и дешёвые, отсеиваешь плохих исполнителей. Опытным путем мы поняли, в чём специфика разметки данных в конкретных областях.
Была и чистая математика. Сложный и важный этап: агрегация ответов исполнителей для получения «мудрости толпы» и отсеивания «шумных» и испорченных ответов. Например задание заключается в том, чтобы построить свою систему ранжирования сайтов. Я не знал, как сделать это надёжно и с минимальными затратами на разметку. Веб-страниц миллиарды, и каждое мелкое улучшение ранжирования экономит компании десятки или сотни тысяч долларов. Потому специалисты по краудсорсингу так ценны.
Так вот, если попросить людей отсортировать сайты по релевантности поисковому запросу или картинки по «красивости», списков будет столько же, сколько людей. Такую разметку сложно агрегировать статистически. Но на курсе нам показали разметку с помощью попарного сравнения картинок. Это оказалось гораздо дешевле и статистически надежнее. Такие нюансы открывались только на практике. Раз за разом преподаватели подкладывали нам грабли, мы на них наступали, но в рамках учёбы это был естественный процесс.
Ближе к концу обучения Толока и Ozon провели хакатон по построению рекомендаций c помощью краудсорсинга. Я и другие ребята с курса в нём участвовали: мы скомбинировали и адаптировали несколько домашних заданий под задачу хакатона и заняли призовое место.
Разметка данных в Толоке: тонкости и подводные камни
Часть курса по контролю качества разметки помогла развенчать мифы в моей голове. Когда я начинал размечать фото, то был настроен скептически: «Я отдаю миллион картинок тысяче человек в интернете, о которых ничего не знаю. На что я рассчитываю? Там могут быть недобросовестные люди, они испортят мне ответы или будут отвечать случайным образом».
А потом я узнал о разметке с помощью перекрытия: даешь одно и то же задание не одному, а пяти толокерам и смотришь, как согласуются ответы. Если отвечают по-разному — задание сложное. А если четверо говорят, что на картинке кот, и только один — что собака, то последний, скорее всего, ошибается.
Я не доверяю каждому человеку по отдельности, но доверяю пяти людям вместе: исполнители не могут скооперироваться, выполняют задания независимо. Значит, неправильные ответы отдельных недобросовестных людей компенсируются правильными ответами порядочных исполнителей, а их в сервисе большинство.
Мне казалось, выделение контура объектов не выполнить краудсорсингом: непонятно, как настроить автоконтроль качества разметки. На курсе мне показали, как это сделать.
Ещё одна техника, с которой я познакомился и которую теперь применяю: передача результатов одних исполнителей другим для уточнения. Эти «другие» тоже не всегда надёжны, но любые проблемы решает перекрытие и отсутствие кооперации между исполнителями, просто по теории вероятностей.
Были и другие открытия. Нам дали задание на генерацию контента: попросили составить биографии сотни малоизвестных актеров. Информация о них была только в специфических источниках, например, в сербской Википедии. Исполнители нашли всю информацию, перевели на русский, привели текст к нужному формату. Получается, они могут генерировать несложный контент, как настоящие копирайтеры. Я не думал, что краудсорсинг помогает решать креативные задачи.
Один из интереснейших инсайтов, о которых я узнал:
Если объяснять людям, зачем нужна их работа, то процент толокеров, готовых выполнить задачу, растёт
Если написать: «Ты поможешь построить беспилотник, который будет ездить по дорогам России и сделает их безопаснее», исполнитель скажет: «Ого, я могу внести вклад в великую вещь!» Само осознание, что работа важна, мотивирует людей больше денег.
Краудсорсинг — мощный инструмент, но овладеть им непросто. Даже при формулировании заданий легко попасть в ментальную ловушку: если тебе всё понятно, то и остальным якобы тоже. Я был уверен, что пишу чёткое задание, но в реальности все читали его по-своему и выполняли иначе. Это я недостаточно понятно объяснял, что прошу сделать.
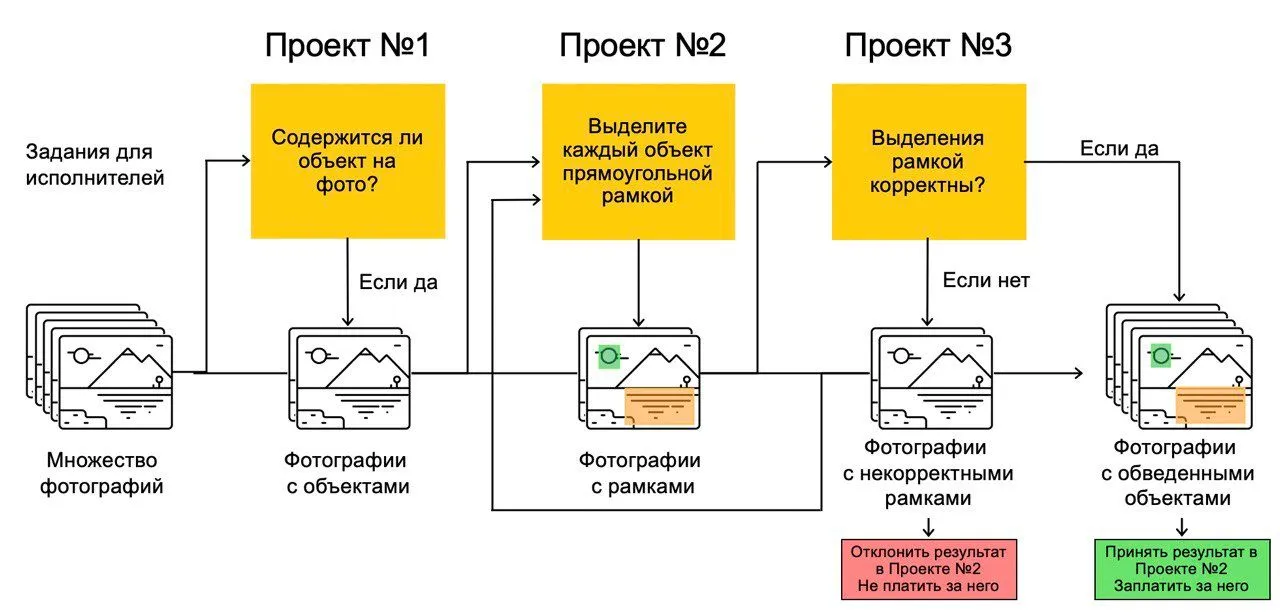
Скажем, я просил выделить прямоугольниками людей на фото. Я-то знаю: это нужно, чтобы обучать нейросеть для детекции, и по техническому формату разметки мне надо, чтобы каждый человек был в своем прямоугольничке. Но исполнители выделяли скученную группу людей одним прямоугольником. По смыслу всё верно, они выделили людей на фото, но такая разметка бесполезна.
Практические задания курса помогли мне научиться заранее продумывать формат и чётко прописывать: «Обведите рамкой каждого отдельного человека на фото так, чтобы высота и ширина рамки были максимально близки к высоте и ширине изображения человека на фото. Выделение лишних областей будет отклонено». Чем лучше инструкция, тем качественнее разметка и тем умнее нейросеть.
Иногда исполнители вообще не читают текст. Я уже говорил о своём дипломе, задача в котором — разметить снимки зубов (не требующие специальных знаний и взятые из открытой базы в интернете). Для диплома я сделал видеоинструкцию. Лучше один раз увидеть, чем читать список из 25 пунктов.
Плюсы и минусы курса
Курс немного выбивается из тем ШАДа, но полученные на нём знания расширяют кругозор. Для меня как для ML- и Deep Learning-разработчика проблема отсутствия данных больше не проблема. Это помогает снять ограничения в голове на масштаб и реализуемость проектов. Оказывается, процессы можно отдавать на недорогой (а если постараться, то и качественный) краудсорс.
Ещё пример. В некоторых компаниях есть специфичные задачи. Один мой коллега размечал временные ряды, полученные c умных часов, для анализа физического состояния человека. Компания потратила полгода, чтобы разметить и несколько раз переразметить данные. Это вместо условных двух недель!
Возможно, с первого раза курс получился неидеальным. Мы писали свои пожелания в Telegram-чат курса, преподаватели хорошо принимали обратную связь и на следующий год пообещали доработать сложные места. А менеджер проектов Толоки Даша Байдакова после каждого семинара собирала фидбэк и пожелания шадовцев к курсу в устных личных разговорах.
Сфера разметки обширна — невозможно уместить в курс нюансы для всех типов ML-задач. Скажем, в разметке фото важен интерфейс задания — тут пригодятся навыки JavaScript, которые выходят за рамки курса.

Перспективы после обучения
Специалисты по краудсорсингу нужны в любой команде, если она строит ML-сервисы для новых задач. Вот сферы и примеры российских компаний, в которых вы будете востребованы:
— поиск (Авито, Ozon, ЦИАН);
— чат-боты и голосовые помощники (Тинькофф, Mail.ru);
— анализ контента и рекомендации (Сбербанк, ABBYY, ВКонтакте, VisionLabs).
Разумеется, к каждому пункту можно добавить Яндекс. Если говорить про зарубежных игроков, то в Google, Facebook, Huawei, Tesla, Amazon, Netflix, Microsoft тоже постоянно решают подобные задачи. И список расширяется: ИИ сейчас проникает во все отрасли.
Зарабатывать специалисты по крауду могут 100–200 тысяч рублей в месяц, но чаще оплата проекта сдельная, поэтому многое зависит от навыков и опыта. В любом случае умение собирать данные повышает конкурентоспособность ML-разработчика в несколько раз. Для него не существует такой преграды, как отсутствие данных, он может концентрироваться на постановке и идее задачи. В связке с другими знаниями, например в области глубинного обучения, навык крауд-менеджмента дает почти безграничные возможности. Можно делать зрение для беспилотника, тренировать сети, которые будут генерировать художественные картины в нужном стиле, строить алгоритмы распознавания речи. Границ нет.
Индустрия разметки будет мощно развиваться в будущем, это просто ещё не все осознали. Глядя на сложности разметки в прорывных областях, на то, как системы анализа картинок помогают врачам, и на новые работы в глубинном обучении и речевых техенологиях, я понимаю: данных нужно будет всё больше. И люди, способные собирать разметку, будут всё более ценны.