Как работает машинное обучение

Компьютеры могут быстро справляться с задачами, которые людям даются с трудом, например с подбором ключа к закодированному сообщению. Однако некоторые задачи даже машины не могут решить за разумное время. Их относят к классу NP, то есть к задачам, чьё решение невозможно проверить на машине Тьюринга — модели абстрактного вычислителя, на которой построены привычные нам компьютеры.
В контексте компьютерных наук машины Тьюринга используются для изучения свойств алгоритмов и определения, какие проблемы компьютеры могут решать. Машины моделируют поведение алгоритмов и анализируют их вычислительную сложность — количество времени и памяти, которые нужны для решения задачи.
Машина Тьюринга — абстракция, которую можно представить в виде считывателя. Он перемещается по бесконечно длинной ленте, состоящей из ячеек, и может читать, записывать или стирать их содержимое. Причём за раз он может обработать только одну ячейку.
Для перемещения машина использует набор правил, где указывается символ, определяющий следующее действие. Например, если машина находится в состоянии А и считывает 0, то нужно стереть его, записать 1, переместиться на одну ячейку вправо и изменить своё состояние на Б. Так, выполняя шаг за шагом инструкции, машина достигает состояния, когда вычисление считается успешным.
С другой стороны, есть задачи, которые человек решает без труда, а компьютеру выполнить их посредством классических вычислений не под силу. Например, перевод текста, диагностирование болезней, определение содержания изображения требуют наличия опыта научения чему-либо. Это сложно запрограммировать.
Здесь на помощь приходит машинное обучение — наука, изучающая алгоритмы, которые улучшаются благодаря собственному опыту. Особенности задач, которые могут решать алгоритмы:
-
Их можно записать в виде функции, которая переводит примеры в ответы. Например, перевести симптомы больного в диагноз или документ в оценку его релевантности поисковому запросу.
-
Для них нет единственного правильного решения. Например, профессиональные переводчики переводят один и тот же текст по-разному — и все варианты верные. В таких задачах рациональнее искать оптимальное решение, а не лучшее.
-
Есть много примеров правильных ответов (например, переводы или подписи к картинкам), а неправильные можем легко создать. Функция, которая переводит примеры в ответы, — модель, а все примеры, которые используют для обучения модели, называют обучающей выборкой или датасетом.
Как обучаются алгоритмы
Для обучения алгоритму нужна исходная база или выборка. Она включает в себя объекты: скачанные из интернета картинки, истории больных, активность пользователей. Для всех объектов создают метки — подписи, которые также называют таргетами. Обучение алгоритмов можно условно разделить на три категории: с учителем, без учителя и обучение с подкреплением.
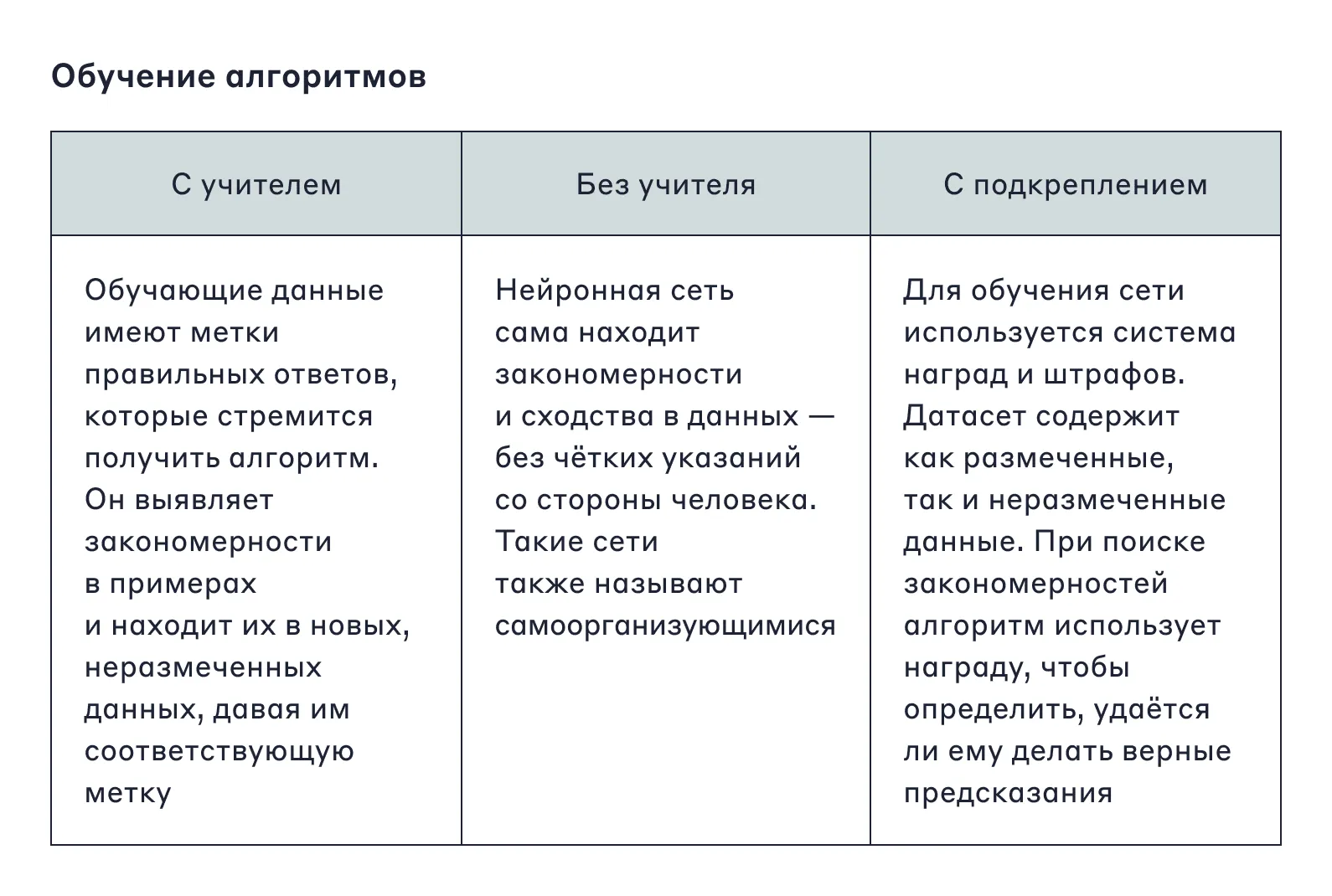
Популярные модели обучения «с учителем» подразделяются на пять основных видов — в зависимости от типа ответа, который мы ожидаем получить:
-
Регрессии — численное значение, например продолжительность поездки на каршеринге или погода на завтра.
-
Бинарная классификация — один из двух возможных исходов. Например, кликнет ли пользователь по рекламной ссылке или вернёт ли клиент кредит в срок.
-
Многоклассовая классификация — к какой категории относится объект. Например, научная статья или вид заболевания у пациента.
-
Многоклассовая с пересекающимися классами, где объект может относиться к нескольким категориям одновременно. Например, проставление тегов кухни для ресторана или определение основных проблем в научной статье.
-
Ранжирование, где мы сортируем объекты по их значимости. Например, при поиске в интернете нужно вывести релевантные страницы в начало списка.
Какие задачи решают машины
Искомое решение может оказаться ложным. Например, в задаче сегментации изображения компьютеру нужно определить, к какому объекту на фото относится каждый пиксель. В задаче машинного перевода нужно сгенерировать предложение на другом языке на основе исходного. Также можно научить модели создавать новые объекты или улучшать качество изображения. Такие используются в масках в социальных сетях.
Есть ещё задачи, где ответы неизвестны или не существуют. Их относят к обучению без учителя. Например, кластеризация — разделение объектов на группы на основе неизвестных свойств: распределить документы по темам или новости по сюжетам.
Этими примерами задачи машинного обучения не ограничиваются, их гораздо больше. Поэтому, если задача не решается одним методом, можно всегда попробовать другой подход.
Например, мы хотим обучить робокота запрыгивать на стол из произвольной позы. Можно создать физическую модель движения робокота и рассчитать оптимальную последовательность. Или создать модель, которая будет в каждый момент времени на основе конфигурации сочленений, высоты от пола, расстояния до стола, фазы Луны и других важных параметров предсказывать, как дальше поворачивать лапы, изгибать спину кота и так далее. Эту модель будем прогонять в симуляции, меняя её в зависимости от того, насколько удачно робот справляется со своей задачей. Такая парадигма машинного обучения называется обучением с подкреплением.
Как оценить качество решения
Допустим, мы стремимся к созданию модели с хорошими предсказаниями. Но как понять, насколько они хороши? В этом помогают метрики качества — способ численно измерить, насколько модель помогает нам в жизни. Поэтому важно понимать, какой именно результат нас устроит и в какой ситуации.
Известная метрика обычно напрямую связана с результатами предсказаний. Тогда мы сразу понимаем, насколько близки к правильному результату. Но на практике задачи могут быть сложнее.
Например, мы хотим повысить уровень счастья пользователей сервиса, чтобы получать стабильный прогнозируемый доход. В таком случае возникает целая иерархия метрик: бизнес-метрики, например будущий доход сервиса, и офлайн-метрики, например точность предсказания.
Что такое офлайн-метрики для оценки результатов предсказаний
Не все результаты можно оценить числами. Бывает, мы ориентируемся на субъективное восприятие людей. Для оценки их реакции нанимают асессоров, которые определяют, насколько удалось улучшить, к примеру, качество машинного перевода или релевантность выдачи в поисковой системе. Оценку асессоров также считают офлайн-метрикой.
Например, для бинарной классификации (да/нет, положительно/отрицательно) используют такие метрики:
-
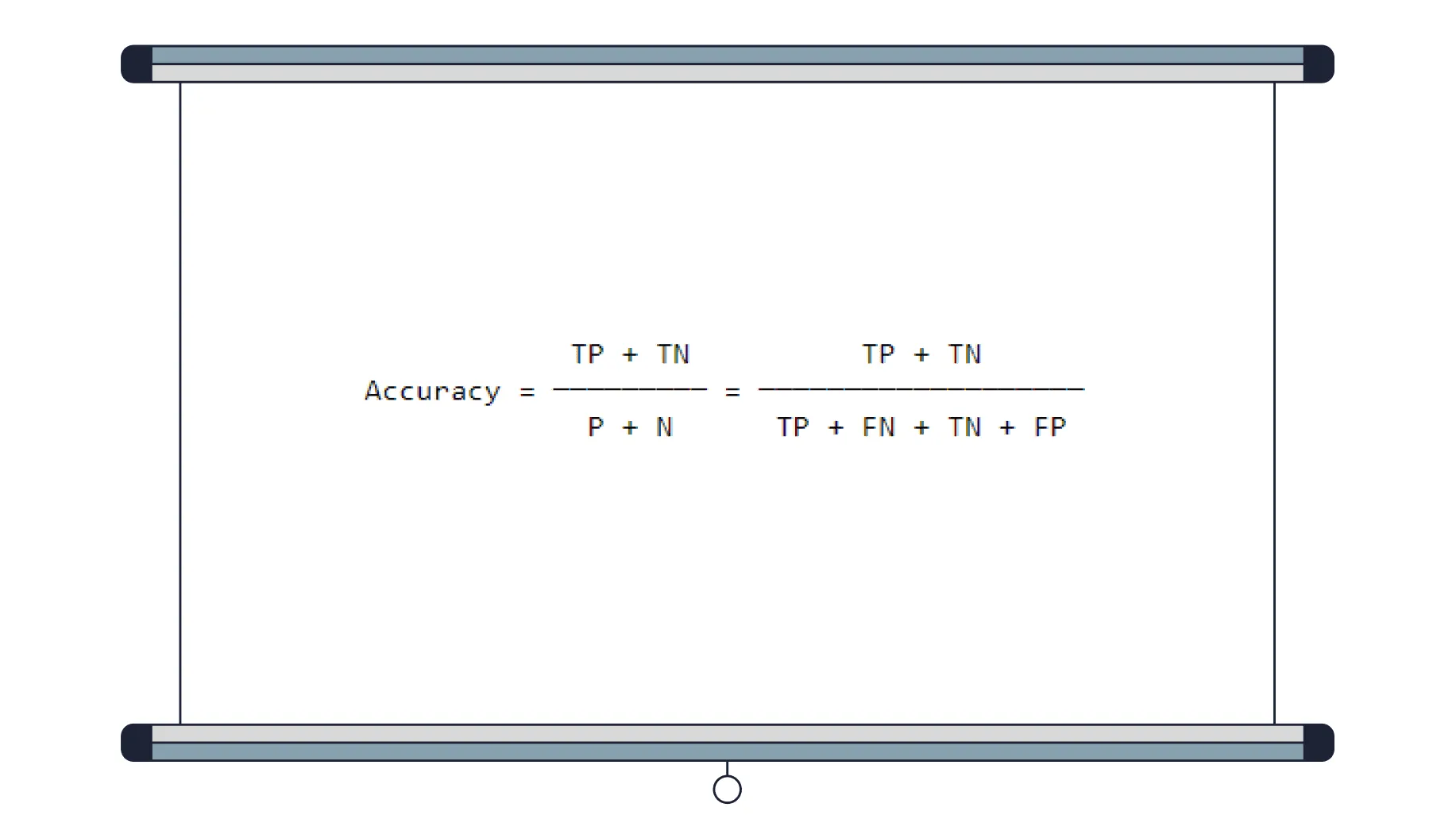
Accuracy — доля правильных предсказаний от их общего числа;
-
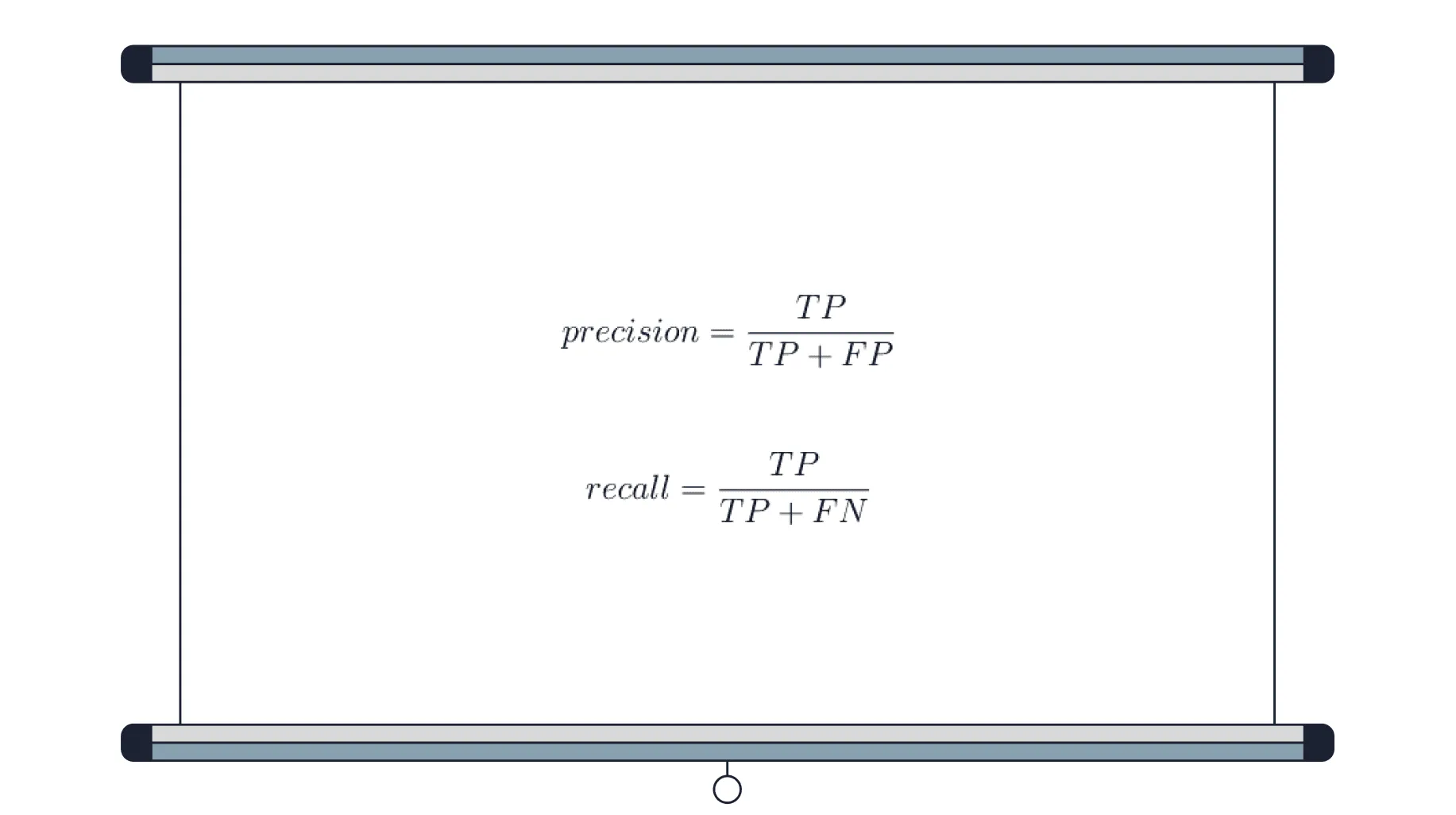
Precision — доля положительных предсказаний, которые совпали с реальным состоянием объектов;
-
Recall — доля правильных предсказаний от общего числа правильных.
Выбор предсказания у алгоритма лежит между «да» и «нет», positive и negative. Для построения метрик составляют матрицу ошибок. Она помогает понять, как соотносятся предсказания с ситуацией в реальной жизни.
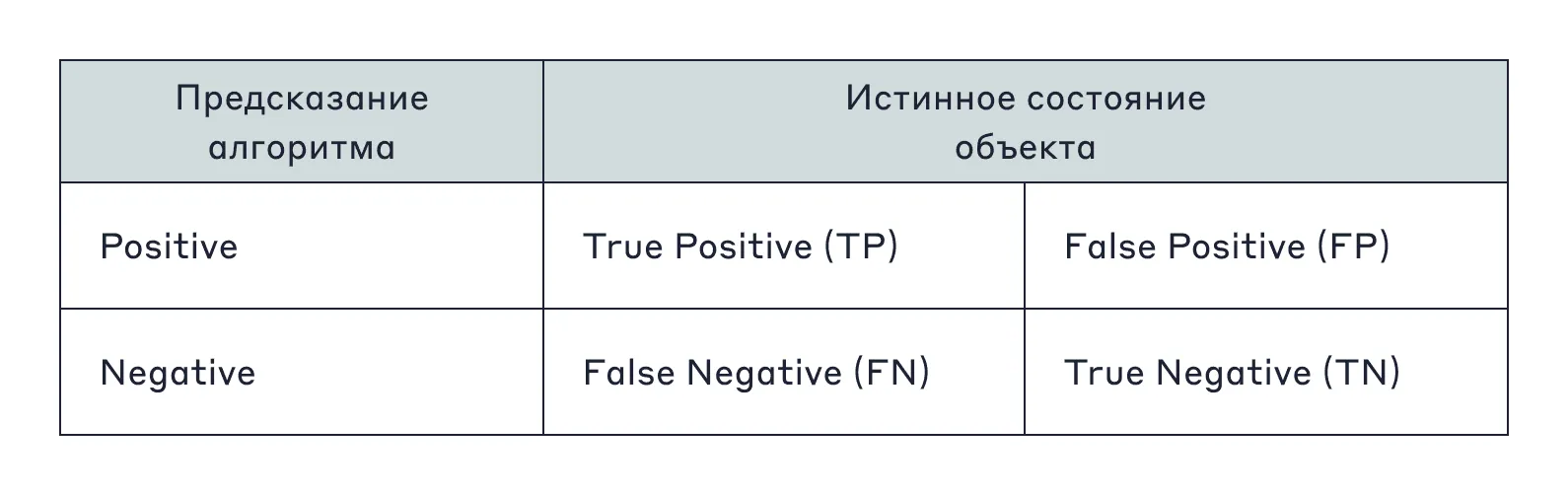
Ответы в этой таблице интерпретируются так:
-
P (Positive) — сколько положительных предсказаний;
-
N (Negative) — сколько отрицательных;
-
TP (True Positive) — положительное предсказание модели совпало с истинным состоянием объекта;
-
FP (False Positive) — модель не угадала с положительным предсказанием;
-
TN (True Negative) — отрицательное предсказание совпало с истинным состоянием объекта;
-
FN (False Negative) — модель не угадала с отрицательным предсказанием.
Интуитивно понятно, что:
P = TP + FN
N = TN + FP
Тогда метрику Accuracy можно представить как соотношение:
Precision и Recall будут выглядеть так:
На примере постановки диагноза больным это можно представить так:
-
Accuracy — доля вообще всех верных заключений (болен / не болен) от общего числа пациентов, как больных, так и здоровых;
-
Precision — доля действительно больных среди тех, кому был поставлен диагноз;
-
Recall — доля выявленных больных среди всех страдающих этим заболеванием.
Как выбрать модель
Модель — некая упрощённая версия реальности, которую мы используем, чтобы лучше понимать мир вокруг нас. Чем точнее модель, тем сложнее её использовать и вычислять, поэтому в каждом случае выбирают модель, которая подходит для задачи.
Например, предсказательные модели вида Y = f(X) пытаются уловить зависимость между признаковым описанием X объекта и таргетом Y. Чаще всего предсказательные модели берутся из набора связанных объектов (параметрического семейства) Y = fᵥᵥ(X), где W — это параметры, которые подбираются по данным.
Для предсказания цены квартиры можно использовать константные функции. Поскольку значение не зависит от x, неважно, как выглядит признаковое описание. Это может быть просто набор любых сведений о квартире. В этом случае для оценки качества подходит среднее абсолютное отклонение (mean absolute error, MAE).

f — модель (f(x) = c); X = (x₁,..., x<sub>N</sub>) — обучающие примеры (данные о квартирах); y = (y<sub>1</sub>,..., y<sub>N</sub>) — правильные ответы (цены на квартиры). Тогда, чтобы найти минимум MAE, нужно взять производную от выражения:

Затем приравнять её к нулю:

Таким образом, для решения функции подходят точки c, для которых число y<sub>i</sub>, строго меньших c, равно числу y<sub>i</sub>, строго больших c. Иначе говоря, для решения функции подходит <a href="https://translated.turbopages.org/proxy_u/en-ru.ru.efed9441-64647240-d3afb2cd-74722d776562/https/en.wikipedia.org/wiki/Median" target="_blank">медиана</a> набора (y<sub>1</sub>,...y<sub>N</sub>):

Для решения большинства практических задач на сегодня достаточно знать только два типа моделей: градиентный бустинг на решающих деревьях и нейросетевые модели.
Как выбрать алгоритм обучения модели
Алгоритм обучения — процесс, который превращает обучающую выборку в обученную модель. Например, для константной модели (с постоянной функцией) в качестве алгоритма обучения можно использовать градиентный спуск.
Любую модель можно натренировать так, что она идеально найдёт закономерности в обучающей выборке по любой метрике. Но важнее, чтобы она работала эффективно там, где результат неизвестен. Поэтому у работающей модели всегда проверяют, насколько она способна находить общие закономерности в новых данных, а не только признаки в обучающей выборке. Это называется обобщающей способностью модели.
Чтобы проверить, датасет делят на обучающую и тестовую выборки (train и test). Обучающую используют для тренировки модели, метрики считают на тестовой. Это позволяет отделить модели, которые хорошо подстроились к обучающим данным, от моделей, в которых произошла генерализация (generalization). То есть от тех, которые действительно что-то «поняли» в ходе обучения и могут выдавать верные предсказания для неизвестных объектов.
Что делает специалист по машинному обучению после обучения модели
-
Редактирует и верно организует код модели. Об этом процессе мы выпустили отдельный материал.
-
Проверяет модель на совместимость с фреймворками и «выкатывает» её в продакшен.
-
Считает онлайн-метрики и проводит A/B-тестирование: сравнивает с предыдущей версией модели на случайно выбранных подмножествах пользователей или сессий. Если новая модель работает с ошибками, откатывается к старой версии.
-
Продолжает дообучать или переобучать модель при поступлении новых данных, мониторит качество.



