
Как использовать GPT при создании сервисов

Промтинг: как общаться с моделью, чтобы получать от неё нужные ответы
Прежде чем использовать более сложные функции GPT, которые помогают при создании сервисов, важно научиться правильно составлять промт. С него начинается любое взаимодействие с LLM (Large Language Model), и от него будет зависеть качество ответа модели.
Но с непрерывным обновлением нейросетей обучаться промтингу становится не так просто, потому что способы взаимодействия с ними тоже меняются. То, что было актуально для одних моделей, быстро оказывается устаревшим для других. Однако есть несколько универсальных приёмов, которые помогут составить классный промт и получить от модели нужный ответ.
Что работает:
-
примеры;
-
заданный формат ответа;
-
просьба изложить свои рассуждения;
-
точные инструкции;
-
уточнения на основе полученного ответа.
Что не работает:
-
поиск и выделение нескольких категорий в тексте (лучше заменить на несколько бинарных классификаций);
-
слишком длинные промты;
-
избыточное ролевое моделирование.
JSON Response: как встроить ответы ИИ в код
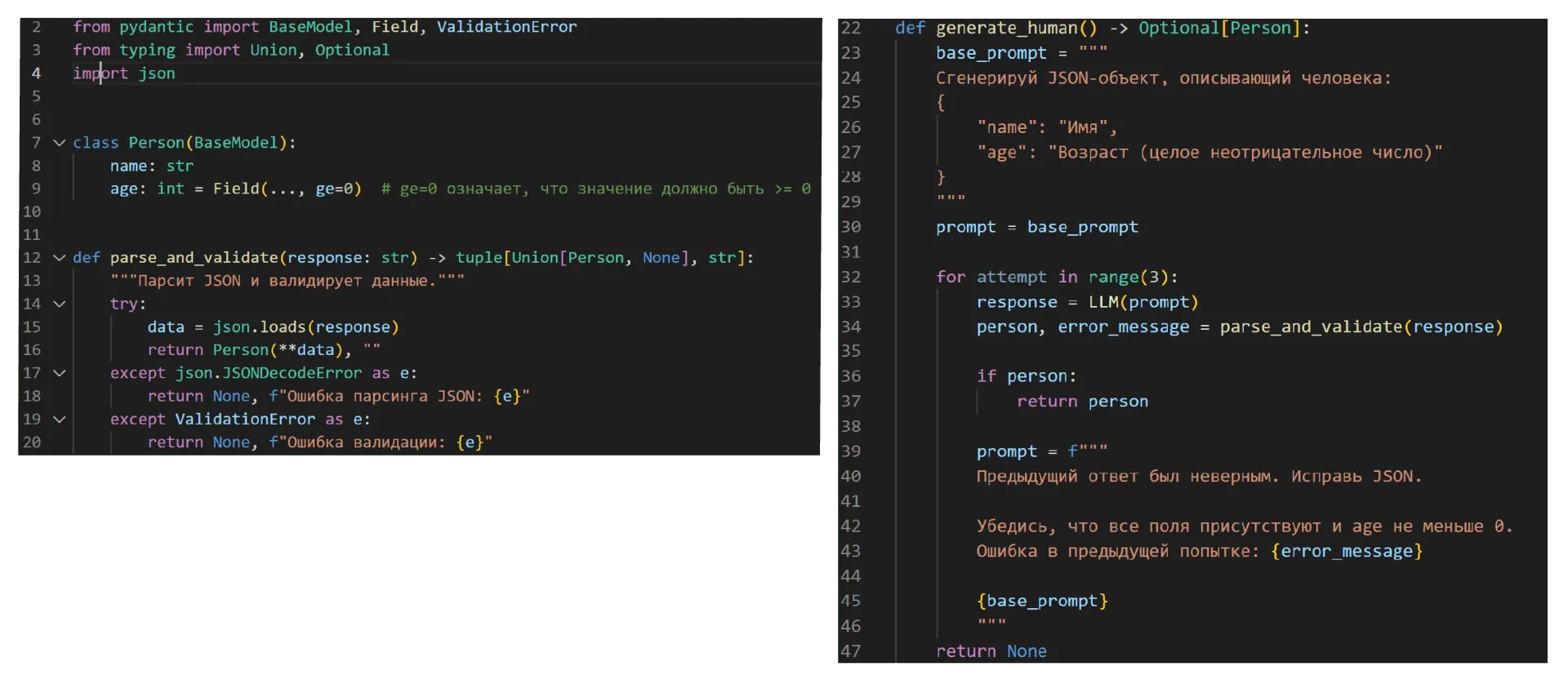
После того как вы научились задавать модели правильные вопросы, нужно научить её выдавать вам правильные ответы. Лучше всего для этого подойдёт формат JSON Response (JavaScript Object Notation). Он используется при общении приложений друг с другом и представляет собой набор ключей и их значений. В JSON вся информация из ответа LLM чётко структурируется — поэтому такой формат проще и быстрее встраивается в код и систему, чем обычный текст.
Но не стоит забывать, что модель может ошибиться: добавить лишний ключ, пропустить нужный или заменить его на другой, выдать невалидное значение объекта или сделать синтаксическую ошибку в коде. Как можно это исправить:
-
Проверьте промт и возможности модели. Те, что помощнее (Claude, ChatGPT, Gemini), имеют внутренние системы генерации JSON — это поможет решить часть проблем. Если использовать такие модели возможности нет, максимально подробно опишите в промте, что вы хотите получить ответ именно в формате JSON. Пусть он будет как можно более простым, а сложные запросы разделите на несколько — так модель справится лучше.
-
Проверьте ответ модели. Убедитесь, что модель вернула валидный JSON с правильными полями и что значения этих полей лежат в нужном диапазоне.
-
Исправьте ответ. Можно указать модели на её ошибки и попросить их исправить, а можно сделать это самостоятельно или с помощью библиотек вроде json_repair или Instructor.
RAG: как дать модели доступ к новой информации без переобучения
Несмотря на удобство JSON, иногда от модели всё же нужен текст — например, если она отвечает на вопрос пользователя сервиса. В таком случае информация в ответе должна быть наиболее актуальной, чтобы пользователь остался доволен предложенным ему решением. Но нужная информация могла появиться уже после обучения модели.
Чтобы не переобучать LLM на новых данных перед каждым ответом на запрос пользователя, можно использовать RAG (Retrieval Augmented Generation). Он позволяет добавлять более актуальную информацию — будь то закрытые компанией или постоянно обновляющиеся данные — напрямую в запрос.
Как следует из названия, RAG подразумевает три этапа: retrieval — самостоятельный поиск актуальных документов, augmentation — «подмешивание» этих документов в промт, generation — генерация моделью ответа на основе новых данных. Ключевую роль здесь играет именно первый этап, потому что на нём информация ранжируется по релевантности. От того, как это будет сделано, зависит качество ответа нейросети.
Чаще всего RAG реализуется при помощи фреймворка LangChain, который помогает создавать LLM-агентов для их интеграции в приложения. А вот в каких сферах можно эффективно использовать эту функцию.
Автоматизированная техподдержка. Модель не знает, что происходит в документации компании. Но если разрешить ей доступ, она сможет на основе этой информации дать максимально актуальный ответ на запрос пользователя.
Поисковые системы в духе «Нейро». Они устроены следующим образом: модель ищет документы по запросу в интернете, добавляет их в LLM и в ответе суммаризирует найденные статьи.
Обучение по конкретным материалам. Если ученик чего-то не понимает, он может задать свой вопрос, например, YandexGPT. Но если это вопрос в рамках определённой темы на курсе, лучше добавить материалы из этого курса в промт, чтобы ответ соответствовал методическому плану и не включал в себя ещё не пройденные темы.
Работа с юридическими документами. Они постоянно обновляются, и, чтобы не тратить время и средства на переобучение модели, можно добавлять новые версии документов в запрос при использовании RAG.
Function Calling: как связать модель с внешними сервисами
Вызов функции, как и RAG, даёт модели доступ к наиболее актуальным данным — но не «подмешивая» их в запрос, а объединяя с другими сервисами.
Допустим, пользователь хочет узнать прогноз погоды на завтра. На этой информации модель точно не обучалась, а добавлять её через RAG слишком трудозатратно, ведь прогноз меняется чаще, чем любая документация. Тогда модели нужно обратиться к погодному сервису, который регулярно обновляется и предоставляет точные данные. И Function Calling позволяет реализовать этот процесс.
Также вызов функций может объединить LLM с календарём, трекерами задач, приложениями для вычислений и построения графиков. Это не только открывает модели доступ к новым источникам информации, которые повышают качество её ответов, но и упрощает взаимодействие пользователя с системой сервисов. Например, можно просто попросить нейросеть добавить совещание в расписание — и она сделает это.
В современные LLM, такие как GPT-4 и GigaChat, уже встроены необходимые функции для Function Calling. Но если их нет, можно написать их самостоятельно. Для этого в промте нужно указать запрос пользователя и попросить модель вернуть бинарный JSON, который будет говорить, нужно ли вызывать ту или иную функцию. Если ответ будет положительным, то необходимо вызвать функцию и подставить её ответ в следующий запрос.


