Войти



Ошибка Кода
Разбор заданий, средний уровень
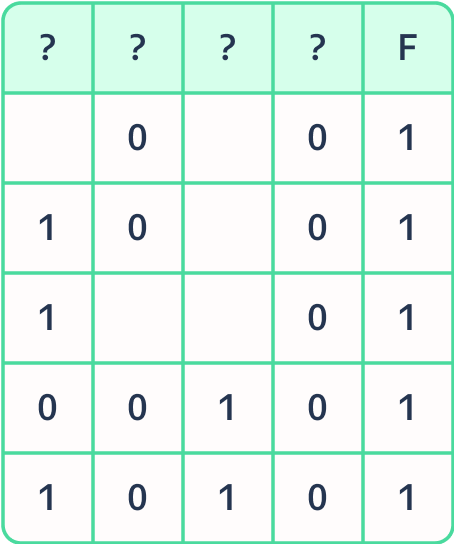
Это даст нам всевозможные варианты истинности или ложности для каждой переменной.
Затем, в каждой итерации цикла, мы проверяем, выполняется ли заданное условие. Это условие включает в себя логические операции «НЕ» (not), «И» (and), «ИЛИ»(or), «ИМПЛИКАЦИЯ» (логическое следование, в python можно записать как «≤», меньше или равно, но нужно быть очень внимательным и следить за приоритетами операций).
В данной задаче необходимо (((not (a)) ≤ (not (d))) взять в дополнительные скобки, чтобы не нарушить порядок действий.
Если условие выполняется, мы выводим текущую комбинацию переменных a, b, c, и d. Важно заметить, что логические операции и сравнения нужно проводить в правильном порядке, соблюдая приоритеты, чтобы получить корректный результат.
print("a b c d")
for a in 0,1:
for b in 0,1:
for c in 0,1:
for d in 0,1:
if (not(c) and (((not(a)) <= (not(d))) <= (not(b)))) == 1:
print(a, b, c, d)
Подход к решению задачи строится на следующих этапах:
Почему мы используем такой подход? Этот метод является наиболее прямолинейным и систематическим способом найти решение. Он позволяет нам перебрать все возможные комбинации и перестановки, чтобы найти те, которые соответствуют заданной таблице истинности и функции F.
# Импортируем нужные функции из модуля itertools
from itertools import *
# Определяем функцию f, реализующую логическую функцию F
def f(a, b, c, d):
return (not(c) and (((not(a)) <= (not(d))) <= (not(b))))
# Генерируем все возможные комбинации значений переменных a1, a2, a3, a4, a5, a6
for a1, a2, a3, a4, a5, a6 in product([0, 1], repeat=6):
# Задаем фрагмент таблицы истинности в виде списка кортежей
table = [(a1, 0, a2, a6), (1, 0, a3, 0), (1, a4, a5, 0), (0, 0, 1, 0), (1, 0, 1, 0)]
# Проверяем, что все строки в таблице уникальны
if len(table) == len(set(table)):
# Перебираем все возможные перестановки столбцов (abcd, abdc, acbd, ...)
for p in permutations("abcd"):
# Проверяем, что для данной перестановки значения F совпадают с заданными в таблице
if [f(**dict(zip(p, r))) for r in table] == [1, 1, 1, 1, 1]:
# Выводим найденную перестановку
print("".join(p))
На вход программы подаётся натуральное число N. Программа преобразует это число в новое число R следующим образом:
Суть этого решения заключается в том, чтобы пройти через заданный диапазон чисел, преобразовать каждое из них по определенным правилам и отобрать те, которые удовлетворяют заданному условию. После этого из отобранных чисел выбираем минимальное.
*В данной задаче использование массива действительно оправдано, потому что минимальное число, удовлетворяющее условиям, не обязательно будет первым найденным числом, которое больше 213. Это связано с тем, что преобразование числа N в число R не является монотонным. То есть, большее значение N не гарантирует большее значение R, и наоборот. Следовательно, необходимо проверить все возможные числа R в заданном диапазоне и только потом выбрать минимальное из них.
# Инициализация пустого списка arr для хранения чисел R, которые больше 213.
# Это нужно для того, чтобы в конце найти минимальное из них.
arr = []
# Запускаем цикл for для каждого числа N в диапазоне от 1 до 299.
# Мы выбрали верхнюю границу 300 (не включительно), чтобы учесть все возможные числа R, которые могут быть больше 213.
for N in range(1, 300):
# Преобразуем число N в его двоичное представление, удаляем префикс "0b", оставляя только двоичные цифры.
n = bin(N)[2:]
# Проверяем, делится ли число N на 4 без остатка.
if N % 4 == 0:
# Если делится, добавляем последние две двоичные цифры к числу n.
n = n + n[-2:]
else:
# Если не делится, переводим остаток от деления N на 4 в двоичную систему и дописываем его к числу n.
n = n + bin(N % 4)[2:]
# Проверяем, равна ли последняя цифра двоичного числа n нулю.
if n[-1] == "0":
# Если равна, удаляем эту последнюю цифру.
n = n[:-1]
# Переводим полученное двоичное число n обратно в десятичную систему.
R = int(n, 2)
# Проверяем, больше ли число R 213.
if R > 213:
# Если больше, добавляем его в список arr.
arr.append(R)
# Из всех чисел в списке arr выбираем минимальное.
print(min(arr))
Суть этого решения заключается в полном переборе всех возможных четырёхзначных чисел в восьмеричной системе счисления и проверке каждого из них на соответствие ряду заданных условий. После перебора всех комбинаций выводим количество чисел, которые удовлетворяют всем условиям.
# Импортируем функцию product из библиотеки itertools
from itertools import product
# Инициализируем переменную n, которая будет хранить количество подходящих чисел
n = 0
# В цикле перебираем все возможные четырёхзначные числа в восьмеричной системе счисления
for i in product("01234567", repeat = 4):
# Преобразуем кортеж в строку
s = ''.join(i)
# Проверяем, что число начинается на '3', заканчивается на '0' и все его цифры различны
if s[0] == '3' and s[-1] == '0' and len(set(s)) == 4:
# Заменяем все четные цифры на '0', чтобы удобнее проверять условие о соседних четных цифрах
s = s.replace('2','0').replace('4','0').replace('6','0')
# Проверяем, что в числе нет двух подряд идущих четных цифр ('00')
if '00' not in s:
# Увеличиваем счетчик подходящих чисел
n += 1
# Выводим ответ
print(n)
Определите сумму всех чисел в строке с наименьшим номером, для чисел которой выполнены оба условия:
Суть этого решения заключается в построчном чтении файла и анализе каждой строки на соответствие заданным условиям. Как только находится строка, удовлетворяющая всем условиям, вычисляется сумма чисел в этой строке, и поиск прекращается.
# Инициализируем переменную result для хранения результата
result = None
# Открываем файл для чтения
with open('9.txt','r') as file:
# Читаем файл построчно
for row in file:
# Разделяем числа
str_numbers = row.split(' ')
# Преобразуем строки в целые числа
numbers = list(map(int, str_numbers))
# Создаем словарь для хранения количества каждого числа в строке
num_counts = {}
# Считаем количество каждого числа в строке
for num in numbers:
if num in num_counts:
num_counts[num] += 1
else:
num_counts[num] = 1
# Проверяем условия
if (
list(num_counts.values()).count(3) == 2 and # Два числа повторяются трижды
len(num_counts) == 4 and # Всего 4 различных числа в строке
num_counts[min(numbers)] == 1 # Минимальное число встречается один раз
):
result = sum(numbers) # Суммируем числа в строке
break # Выходим из цикла, так как нашли нужную строку
# Выводим результат
print(result)
Исполнитель редактор принимает на вход строку цифр и может выполнять две команды:
НАЧАЛО
ПОКА нашлось (733) ИЛИ нашлось (331) ИЛИ нашлось (3333)
ЕСЛИ нашлось (733)
ТО заменить (733, 411)
КОНЕЦ ЕСЛИ
ЕСЛИ нашлось (331)
ТО заменить (331, 24)
КОНЕЦ ЕСЛИ
ЕСЛИ нашлось (3333)
ТО заменить (3333, 7)
КОНЕЦ ЕСЛИ
КОНЕЦ ПОКА
КОНЕЦ Для решения этой задачи мы используем метод «перебора» для нахождения минимального значения n. Суть метода заключается в следующем:
Таким образом, мы ищем минимальное n, при котором выполнение заданной программы приводит к строке, сумма цифр которой равна 64.
# Определяем функцию для поиска минимального n
def find_minimum_n():
# Перебираем все возможные значения n от 4 до 9999
for n in range(4, 10000):
# Формируем входную строку
input_string = '7' + '3' * n
# Применяем программу к входной строке
while '733' in input_string or '331' in input_string or '3333' in input_string:
input_string = input_string.replace('733', '411', 1)
input_string = input_string.replace('331', '24', 1)
input_string = input_string.replace('3333', '7', 1)
# Проверяем, равна ли сумма цифр 64
if sum(map(int, input_string)) == 64:
print(n)
break
# Вызываем функцию
find_minimum_n()
Представьте, что в вашей сети, заданной IP-адресом 192.168.32.200 и маской сети 255.255.255.224, каждый IP-адрес ассоциируется с устройством, и каждое устройство имеет уникальный идентификатор, представленный количеством единиц в двоичной записи своего IP-адреса.
Для решения этой задачи мы используем класс ip_network из модуля ipaddress.
Таким образом, мы получаем количество IP-адресов в заданной сети, для которых количество единиц в двоичной записи делится на 3.
# Импортируем класс ip_network из модуля ipaddress
from ipaddress import ip_network
# Инициализируем переменную count для подсчета количества IP-адресов
count = 0
# Создаем объект сети на основе IP-адреса и маски
net = ip_network('192.168.32.200/255.255.255.224', strict=False)
# Перебираем все IP-адреса в данной сети
for ip in net:
# Преобразуем каждый IP-адрес в двоичную форму и считаем количество единиц
# Проверяем, делится ли количество единиц на 3
if f'{ip:b}'.count('1') % 3 == 0:
# Увеличиваем счетчик, если условие выполняется
count += 1
# Выводим ответ
print(count)
Для решения этой задачи мы используем перебор всех возможных значений для переменной y в 15-ричной системе счисления.
Таким образом, мы ищем такое значение y, при котором арифметическое выражение делится на 14 без остатка. Как только такое значение найдено, мы выводим результат и останавливаем поиск.
# Перебираем все возможные значения y в 15-ричной системе счисления
for y in '0123456789ABCDE':
# Вычисляем значение арифметического выражения для текущего y
n = int(f'ABCD{y}', 15) + int(f'123{y}4', 15)
# Проверяем, делится ли полученное число на 14 без остатка
if n % 14 == 0:
# Если делится, выводим частное от деления на 14
print(n // 14)
# Прекращаем перебор
break
Для решения этой задачи мы используем перебор всех возможных комбинаций значений переменных a, x, и y для проверки заданного логического выражения.
Такой «полный перебор» гарантирует, что мы проверим все возможные случаи. Это важно, потому что нам нужно удостовериться, что выражение истинно для всех x и y в заданном диапазоне, прежде чем сделать вывод о a. Основные шаги решения следующие:
Таким образом, мы находим минимальное значение a, при котором заданное логическое выражение будет истинным для всех возможных значений x и y в заданном диапазоне.
# Определение функции f, которая возвращает значение логического выражения
def f(x, y, a):
return (2*x + y < a) or (y > 17) or (x > y)
# Перебор значений a от 0 до 499
for a in range(0, 500):
# Проверка, является ли выражение истинным для всех x и y от 0 до 499
if all(f(x, y, a) for x in range(0, 500) for y in range(0, 500)):
# Вывод найденного значения a и завершение выполнения
print(a)
break
Решение описывает рекурсивную функцию f (n), которая вычисляет значение на основе заданных условий.
Для ускорения вычислений используется декоратор @lru_cache (None), который кеширует результаты предыдущих вызовов функции, чтобы избежать повторного вычисления.
'''
1. Функция f(n) рекурсивно вычисляет значение на основе заданных условий.
2. Декоратор lru_cache кеширует результаты, чтобы ускорить вычисления и избежать повторных вызовов.
3. В зависимости от значения n, функция может вызывать себя с разными аргументами и выполнять разные математические операции.
4. В конце функция вызывается с аргументом 99, и результат выводится на экран.
'''
# Импорт декоратора для кеширования результатов функции
from functools import lru_cache
# Применение декоратора к функции для кеширования результатов
@lru_cache(None)
def f(n):
# Если n <= 1, возвращаем 42
if n <= 1:
return 42
# Если n чётное и больше 1, возвращаем сумму результатов f(n - 2), f(n - 3) и n
elif n > 1 and n % 2 == 0:
return f(n - 2) + f(n - 3) + n
# Если n нечетное, возвращаем разницу между результатами f(n - 1), f(n - 3) и n
else:
return f(n - 1) + f(n - 3) - n
# Выводим результат функции для n = 99
print(f(99))
Этот решение также представляет собой рекурсивную функцию f (n), но, в отличие от предыдущего примера, он использует глобальный список values для кеширования результатов функции, вместо использования декоратора lru_cache.
Рассмотрим код подробнее:
'''
1. Функция f(n) рекурсивно вычисляет значение на основе заданных условий.
2. Глобальный список values используется для кеширования результатов, чтобы ускорить вычисления и избежать повторных вызовов.
3. В зависимости от значения n, функция может вызывать себя с разными аргументами и выполнять разные математические операции.
4. После вычисления значения оно сохраняется в списке values.
5. В конце функция вызывается с аргументом 99, и результат выводится на экран.
'''
# Инициализация списка для кеширования результатов функции
values = [None] * 100
# Определение функции f(n)
def f(n):
global values
# Если значение для n уже вычислено, возвращаем его
if values[n] != None:
return values[n]
# Если n <= 1, значение равно 42
if n <= 1:
value = 42
# Если n чётное и больше 1, вычисляем значение на основе f(n - 2), f(n - 3) и n
elif n > 1 and n % 2 == 0:
value = f(n - 2) + f(n - 3) + n
# Если n нечетное, вычисляем значение на основе f(n - 1), f(n - 3) и n
else:
value = f(n - 1) + f(n - 3) - n
# Сохраняем вычисленное значение в список values
values[n] = value
return value
# Выводим результат функции для n = 99
print(f(99))
В ответе запишите количество найденных четвёрок чисел, затем максимальную из сумм элементов таких четвёрок.
Такой подход эффективен, потому что мы делаем только один проход по списку чисел, сохраняя при этом всю нужную информацию для ответа на вопросы задачи. В итоге, мы получаем количество четверок, удовлетворяющих заданным условиям, и максимальную сумму среди этих четверок.
# Путь к файлу
file_path = '17.txt'
# Чтение чисел из файла и преобразование их в список целых чисел
with open(file_path, 'r') as f:
nums = list(map(int, f.read().split()))
# Находим максимальное число в последовательности, которое оканчивается на 47
max_47 = max(x for x in nums if x % 100 == 47)
# Инициализируем переменные для подсчета количества четверок и максимальной суммы
cnt = 0
max_sum = 0
# Перебираем все четверки чисел в последовательности
for i in range(len(nums) - 3):
quartet = nums[i:i + 4]
# Проверяем условия для каждой четверки:
# 1) ровно два элемента больше 1000
# 2) сумма элементов не больше max_47
if sum(x > 1000 for x in quartet) == 2 and sum(quartet) <= max_47:
cnt += 1
max_sum = max(max_sum, sum(quartet))
# Выводим результат
print(cnt, max_sum)
Алиса и Боб играют в игру с двумя кучами монет. Алиса ходит первой. За один ход игрок может либо добавить одну монету в одну из куч (по своему выбору), либо умножить количество монет в одной из куч на два.
Игра завершается, когда суммарное количество монет в кучах становится не менее 122.
В начальный момент в первой куче 22 монеты, во второй куче — S монет 1 ≤ S ≤ 99.
Известно что Боб выиграл своим первых ходом, после неудачного хода Алисы.
Для решения этой задачи мы используем рекурсивную функцию, которая моделирует ходы в игре между Алисой и Бобом.
Основная идея решения:
В итоге, мы ищем минимальное значение S, при котором Боб выигрывает своим первым ходом после ошибочного хода Алисы. Это делается с помощью перебора возможных начальных значений S и проверки исхода игры для каждого из них.
# Определение рекурсивной функции f, которая моделирует игру
def f(a, b, m):
# Проверка, достигла ли сумма двух куч 122 или более
if a+b >= 122:
# Если это ход Боба, он выигрывает
return m % 2 == 0
# Если это ход Алисы и сумма еще не достигла 122, она проигрывает
if m == 0:
return 0
# Рекурсивный вызов функции для всех возможных ходов
h = [f(a+1, b, m-1), f(a * 2, b, m-1), f(a, b+1, m-1), f(a, b*2, m-1)]
# Если это ход Боба, он выигрывает, если хотя бы один из рекурсивных вызовов возвращает True
# Если это ход Алисы, она проигрывает, если хотя бы один из рекурсивных вызовов возвращает True
return any(h) if (m-1) % 2 == 0 else any(h)
# Поиск минимального значения S, при котором Боб выигрывает своим первым ходом
print(min([s for s in range(1, 100) if f(22, s, 2)]))
Алиса и Боб играют в игру с двумя кучами монет. Алиса ходит первой. За один ход игрок может либо добавить одну монету в одну из куч (по своему выбору), либо умножить количество монет в одной из куч на два.
Игра завершается, когда суммарное количество монет в кучах становится не менее 122.
В начальный момент в первой куче 22 монеты, во второй куче — S монет 1 ≤ S ≤ 99.
Найдите минимальное значение S, при котором у Алисы есть выигрышная стратегия, причём одновременно выполняются два условия:
Ход решения для данной задачи отличается от задачи 19 тем, что на этот раз оба игрока играют оптимально (нет неудачных ходов).
В остальном решение идентичное и подробно расписано в 19 задаче.
# Функция f рекурсивно решает задачу для заданных состояний куч a и b и ходов m.
# Возвращает True, если для игрока, который ходит m-м, есть выигрышная стратегия.
def f(a, b, m):
# Если сумма монет в кучах больше или равна 122, то проверяем, выигрывает ли текущий игрок.
if a+b >= 122:
return m % 2 == 0
# Если ходов больше нет, то текущий игрок проигрывает.
if m == 0:
return 0
# Вычисляем возможные ходы для текущего игрока и храним их в списке h.
h = [f(a+1, b, m-1), f(a * 2, b, m-1), f(a, b+1, m-1), f(a, b*2, m-1)]
# Если следующий ход принадлежит противнику, то текущий игрок выигрывает, если противник проигрывает хотя бы одной стратегии.
# Иначе текущий игрок выигрывает только если противник проигрывает всем стратегиям.
return any(h) if (m-1) % 2 == 0 else all(h)
# Ищем минимальное значение S, при котором Алиса не может выиграть за один ход, но может выиграть своим вторым ходом.
print(min([s for s in range(1, 100) if not f(22, s, 1) and f(22, s, 3)]))
Алиса и Боб играют в игру с двумя кучами монет. Алиса ходит первой. За один ход игрок может либо добавить одну монету в одну из куч (по своему выбору), либо умножить количество монет в одной из куч на два.
Игра завершается, когда суммарное количество монет в кучах становится не менее 122.
В начальный момент в первой куче 22 монеты, во второй куче — S монет 1 ≤ S ≤ 99.
Найдите значение S, при котором одновременно выполняются два условия:
Ход решения для данной задачи отличается от задачи 20 тем, что:
В остальном решение идентичное и подробно расписано в 19 задаче.
# Функция f рекурсивно решает задачу для заданных состояний куч a и b и ходов m.
# Возвращает True, если для игрока, который ходит m-м, есть выигрышная стратегия.
def f(a, b, m):
if a+b >= 122: # Проверка условия окончания игры
return m % 2 == 0 # Проверка, выигрывает ли текущий игрок
if m == 0: # Проверка наличия ходов
return 0 # Если ходов нет, игрок проигрывает
# Рекурсивный перебор возможных ходов для текущего состояния
h = [f(a+1, b, m-1), f(a * 2, b, m-1), f(a, b+1, m-1), f(a, b*2, m-1)]
# Логика определения выигрыша или проигрыша для текущего игрока
return any(h) if (m-1) % 2 == 0 else all(h)
# Ищем значение S, при котором Боб может выиграть первым или вторым ходом, но не может гарантированно выиграть первым ходом.
print(*[s for s in range(1, 100) if not f(22, s, 2) and f(22, s, 4)])
Информация о процессах представлена в виде txt файла.
В первом столбце указан идентификатор процесса (ID), во втором столбце — время его выполнения в миллисекундах, в третьем столбце перечислены с разделителем «;» ID процессов, от которых зависит данный процесс. Если процесс является независимым, то указано значение 0.
Изначально в этом словаре есть только начальный процесс с временем выполнения равным нулю.
Мы также создаём список, в который считываем все данные о процессах и их зависимостях.
Перебираем процессы до тех пор, пока не найдены минимальные времена выполнения для всех процессов. В каждом проходе этого цикла мы просматриваем все процессы и проверяем, известно ли нам уже минимальное время выполнения для всех их зависимостей. Если известно, мы вычисляем и сохраняем минимальное время выполнения для текущего процесса как сумму его собственного времени выполнения и максимального из минимальных времен выполнения его зависимостей.
В конце программы мы выводим максимальное из найденных минимальных времен выполнения.
d = {'0': 0} # Словарь для хранения минимального времени выполнения для каждого процесса
data = [] # Список для хранения информации о каждом процессе
# Чтение данных из файла и преобразование их в удобный для работы формат
for s in open('22.txt'):
data.append(s.replace(';', ' ').split())
# Цикл, который будет выполняться до тех пор, пока для всех процессов не будет найдено минимальное время выполнения
while len(d) != len(data) + 1:
for s in data:
# Проверка, известно ли минимальное время выполнения для всех зависимостей текущего процесса
if all(sub in d for sub in s[2:]):
# Вычисление и сохранение минимального времени выполнения для текущего процесса
d[s[0]] = int(s[1]) + max(d[sub] for sub in s[2:])
# Вывод максимального значения среди всех минимальных времен выполнения процессов
print(max(d.values()))
Программа для исполнителя — это последовательность команд.
На самом деле, этот процесс повторяется для каждого рекурсивного вызова, пока x не станет равным или большим y.
В конце мы просто перемножаем количество способов для двух разных интервалов чисел (от 3 до 50 и от 50 до 200) для получения итогового ответа.
# Функция f рекурсивно считает количество программ от числа x до числа y
def f(x, y):
# Если на каком-то этапе x стало равным 15, такая программа нам не подходит
if x == 15:
return 0
# Если x достиг или превысил y, проверяем, равны ли они
if x >= y:
return x == y
# Рекурсивно вызываем функцию для всех трех операций и суммируем результаты
return f(x + 2, y) + f(x * 2, y) + f(x ** 3, y)
# Считаем количество программ, которые переходят от 3 к 50, и от 50 к 200
# Перемножаем эти количества для получения итогового ответа
print(f(3, 50) * f(50, 200))
В итоге, у нас будет значение максимальной длины подстроки, удовлетворяющей заданным условиям.
# Открываем файл и читаем его содержимое
with open('24.txt') as file:
content = file.read()
max_len = 0 # Инициализируем переменную для хранения максимальной длины подстроки
# Перебираем каждую начальную позицию подстроки в файле
for i in range(len(content)):
encountered_A = False # Флаг для отслеживания вхождения 'A' в подстроку
cur_len = 0 # Переменная для хранения текущей длины подстроки
# Перебираем символы, начиная с i-того элемента
for j in range(i, len(content)):
if content[j] == 'A': # Если встретилась 'A', устанавливаем флаг в True
encountered_A = True
if content[j] == 'B' and encountered_A: # Если встретилась 'B' после 'A', прерываем цикл
break
cur_len += 1 # Увеличиваем текущую длину подстроки
# Если текущая длина подстроки больше максимальной, обновляем максимальную длину
if cur_len > max_len:
max_len = cur_len
# Выводим максимальную длину подстроки
print(max_len)
Назовём маской числа последовательность цифр, в которой также могут встречаться следующие символы:
Например, маске 123*4?5 соответствуют числа 123405 и 12300405.
Числа нужно выводить в порядке возрастания, в одной строке — одно число и частное от деления найденного числа на 2024.
Для решения этой задачи мы используем специальную функцию из библиотеки fnmatch, которая позволяет сравнивать строки с определенными «масками» или шаблонами.
Таким образом, мы находим все числа в заданном диапазоне, которые соответствуют определенному шаблону, и выводим их вместе с частным от деления на 2024.
from fnmatch import fnmatch # Импортируем все функции из библиотеки fnmatch
# Перебираем числа от 2024 до 10^10 с шагом 2024
for n in range(2024, 10**10 + 1, 2024):
# Проверяем, соответствует ли текущее число маске '19?71*32?'
if fnmatch(str(n), '19?71*32?'):
# Если да, выводим число и частное от деления его на 2024
print(n, n//2024)
При таких исходных данных условию задачи удовлетворяет набор коробок с длинами сторон 39, 40, 41 и 43, 44 т. е. максимальное количество коробок равно 3, а длина стороны самой маленькой коробки равна 39.
Основная идея заключается в том, чтобы найти самую длинную последовательность коробок, которую можно использовать для упаковки подарка «матрёшкой».
В итоге у нас будет два числа: максимальное количество коробок, которое можно использовать для упаковки подарка, и минимальный размер коробки в этой последовательности.
# Чтение данных из файла
with open("26.txt", 'r') as file:
N = int(file.readline().strip()) # Читаем количество коробок
box_sizes = sorted([int(file.readline().strip()) for _ in range(N)]) # Читаем размеры коробок и сортируем их
# Инициализация переменных
max_count = 0 # Максимальное количество коробок для упаковки подарка
min_size = box_sizes[0] # Инициализация минимального размера коробки
# Цикл для поиска максимального количества коробок и минимального размера коробки
count = 1 # Текущее количество коробок в последовательности
for i in range(1, N):
if box_sizes[i] - box_sizes[i - 1] == 1: # Если разница между текущим и предыдущим размером равна 1
count += 1 # Увеличиваем счетчик коробок в последовательности
min_size = min(min_size, box_sizes[i - count + 1]) # Обновляем минимальный размер коробки
max_count = max(max_count, count) # Обновляем максимальное количество коробок
else:
count = 1 # Сбрасываем счетчик коробок
# Вывод результата
print(max_count, min_size)
Задача состоит из двух частей:
1-я часть:
2-я часть:
В итоге, мы получим два ответа: минимальную сумму подпоследовательности, которая делится на заданный делитель, и максимальную длину подпоследовательности с этой суммой.
Этот метод хорошо подходит для небольших данных, но может быть неэффективным для больших объёмов, как указано в условии для варианта «B».
# Открываем файл и считываем числа
with open('27_A.txt') as f:
n, *nums = [int(num) for num in f.read().strip().split()]
div = 997 # заданный делитель
# Инициализация переменной для хранения минимальной суммы
total_min = float('inf')
# Перебор всех подпоследовательностей
for left in range(0, n): # начало подпоследовательности
for right in range(left, n): # конец подпоследовательности
sub = nums[left:right + 1] # текущая подпоследовательность
# Проверка кратности суммы
if sum(sub) % div == 0:
total_min = min(sum(sub), total_min) # обновление минимальной суммы
print(total_min)
# Инициализация переменной для хранения максимальной длины
l_max = -float('inf')
# Перебор всех подпоследовательностей для нахождения максимальной длины
for left in range(0, n): # начало подпоследовательности
for right in range(left, n): # конец подпоследовательности
sub = nums[left:right + 1] # текущая подпоследовательность
# Проверка суммы
if sum(sub) == total_min:
l_max = max(len(sub), l_max) # обновление максимальной длины
print(l_max)
Этот метод гораздо быстрее простого перебора всех подпоследовательностей.
В итоге, у нас будет два числа: минимальная сумма подпоследовательности, которая делится на заданный делитель, и максимальная длина подпоследовательности с этой суммой.
# Открываем файл и считываем числа
with open('27_B.txt') as f:
n, *nums = [int(num) for num in f.read().strip().split()]
div = 997 # заданный делитель
# Инициализация массива для хранения информации о остатках от деления сумм
rems = [None] * div # (sum, len)
rems[0] = (0, 0) # инициализация для остатка 0
# Переменные для хранения текущей суммы и минимальной суммы
total = 0
total_min = float('inf')
# Первый проход: поиск минимальной суммы
for i in range(0, n):
total += nums[i] # обновление текущей суммы
rem = total % div # вычисление текущего остатка
# Проверка и обновление минимальной суммы
if rems[rem] != None:
total_min = min(total_min, total - rems[rem][0])
# Обновление информации о остатке
if rems[rem] == None or rems[rem][0] > total or (rems[rem][0] == total and rems[rem][1] < i + 1):
rems[rem] = (total, i + 1)
# Второй проход: поиск максимальной длины
total = 0
l_max = -float('inf')
for i in range(0, n):
total += nums[i]
rem = total % div
# Проверка и обновление максимальной длины
if rems[rem] != None:
if total - rems[rem][0] == total_min:
l_max = max(l_max, i + 1 - rems[rem][1])
# Обновление информации о остатке
if rems[rem] == None or rems[rem][0] > total or (rems[rem][0] == total and rems[rem][1] < i + 1):
rems[rem] = (total, i + 1)
# Вывод результатов
print(total_min)
print(l_max)